






本次的话题是有关在机器学习模型构建中数据集划分问题。
在机器学习建模中,通常需要将数据集划分为两部分,训练集、测试集。训练集是已经有标签的数据,测试集是无标签的数据。有标签的数据与无标签的数据相互独立。
由于在模型训练过程中经常出现过拟合的情况,也就是说模型在训练过程中表现良好,但是在实际测试环节却不如训练效果。这时,人们将训练集一分为二,将其再次划分为训练集和验证集,目的是在实际进行测试之前就进行一次自我评估,因为训练集和验证集都是带有标签数据的,我们可以自己判断预测的效果。
模型的自我评估通常采用交叉验证,交叉验证就是要通过数据集划分充分利用样本数据评估一个数据模型的表现,尤其是样本量比较小的情况下;交叉验证是要重复利用数据,把样本数据进行选择,组合出不同的训练集和验证集,某次训练集中样本可能在下次成为验证集中的样本。这是“交叉”的含义。
sklearn的官方文档中介绍了许多数据集的分割方法,看上去容易混淆。
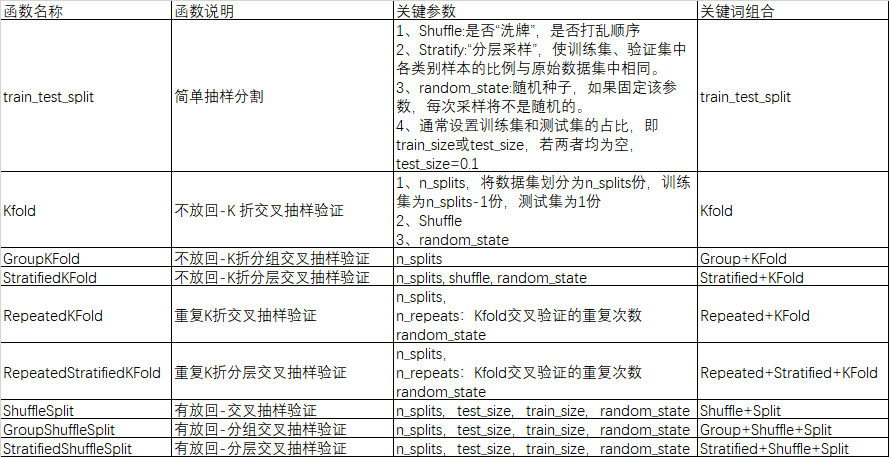
经过阅读文档并总结,本文将这些方法分解为几个关键词,那么数据集划分方法可以认为是关键词的组合。train_test_split:训练集、测试集简单分割。KFold:K 折交叉划分。Stratified:“分层采样”,使训练集、验证集中各类别样本的比例与原始数据集中相同。Group:测试集和训练集中不存在相同的组。Repeated:重复KFold n次,每次重复产生不同的分割。Shuffle:有放回抽样。train_test_split
Kfold
GroupKFold
StratifiedKFold
RepeatedKFold
RepeatedStratifiedKFold
ShuffleSplit
GroupShuffleSplit
StratifiedShuffleSplit
......
scikit-learn官方文档
import numpy as npfrom sklearn.model_selection import train_test_splitX=['a1','a2','a3','a4','b1','b2','b3','b4','c1','c2','c3','c4']y=[0,0,0,0,1,1,1,1,2,2,2,2]train_test_split(X,test_size=0.33333,shuffle=True,random_state=124 ,stratify=y)输出:[['c2', 'a1', 'a3', 'a4', 'b2', 'b3', 'c4', 'b4'], ['b1', 'c1', 'a2', 'c3' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2343
2343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









