






我们自己的写的代码在电脑上运行的时候,是怎么运行的呢。一般会有这么几个问题?
- 程序是顺序执行的,CPU 是怎么进行实现的呢?
- 程序是如何调用函数的,如何传递参数的?
- 当调用函数完成后,CPU 是怎么确定下一条指令的地址的?
基本概念介绍
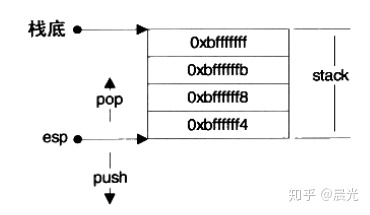
1. 栈
栈在内存中是一块特殊的存储空间,它的存储原则是“先进后出”,即最先被存储的数据,最后被释放。汇编过程通常使用 PUSH 和 POP 指令对栈进行压入和弹出的操作。
栈在程序运行的过程中很重要,栈保存了一个函数调用所需要维护的信息:
- 函数的返回地址和参数
- 局部变量
- 保存的上下文(函数调用前后需要保持不变的寄存器)
2. 寄存器
寄存器是CPU的组成部分,因为在CPU内,所以CPU对其读写速度是最快的,不需要IO传输。
寄存器的用途:
- 可将寄存器内的数据执行算术及逻辑运算。
- 存于寄存器内的地址可用来指向内存的某个位置,即寻址。
- 可以用来读写数据到电脑的周边设备。
通用寄存器
- EAX 累加和结果寄存器
- EBX 数据指针寄存器
- ECX 循环计数器
- EDX i/o指针
- ESI 源地址寄存器
- EDI 目的地址寄存器
- ESP 堆栈指针
- EBP 栈指针寄存器
指令寄存器
- EIP 标志当前进程将要执行指令位置
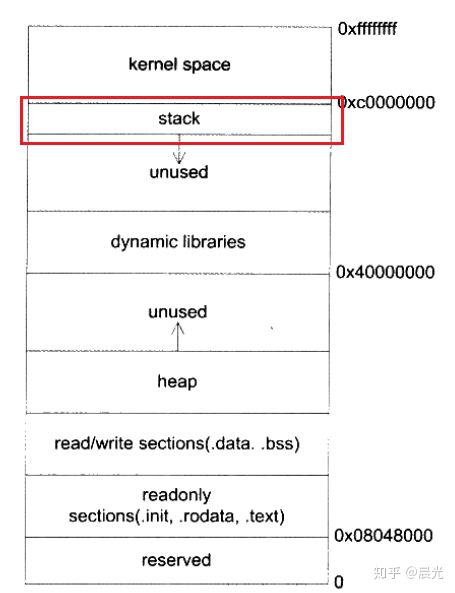
下图是进程的地址空间布局
函数调用流程
压栈
函数参数压栈 返回地址压栈, 使用PUSH和POP指令
跳转
跳转到函数所在代码处执行, 使用call指令调用函数
执行
执行函数代码
返回
找出返回地址并跳回,然后平衡堆栈
常见的调用约定
调用约定堆栈平衡方式__stdcall函数自己平衡__cdecl调用者负责平衡__thiscall调用者负责平衡__fastcall调用者负责平衡__naked有编写者负责
实例分析
下面是一段C++代码:
int add(int a, int b)
{
return a + b;
}
int sub(int a, int b)
{
return a - b;
}
int main()
{
int a = 10;
int b = 3;
int c = add(a, b);
int d = sub(a, b);
return 0;
}编译后,生成可执行文件,用 OD 动态调试,下面是是main函数的汇编代码,关于重点的汇编代码都有注释,可以按流程自己一步一步看下。
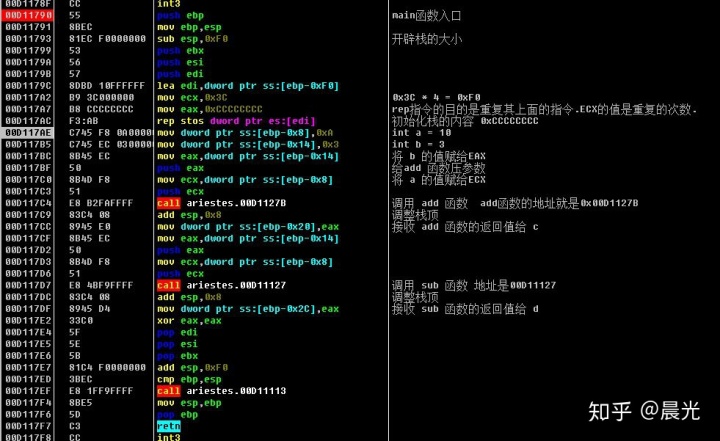
在调用 add 函数的时候,我们看到是用 call 指令加上 add 函数的地址,直接进入的 add 函数,这个时候的栈变化是这样的,如图
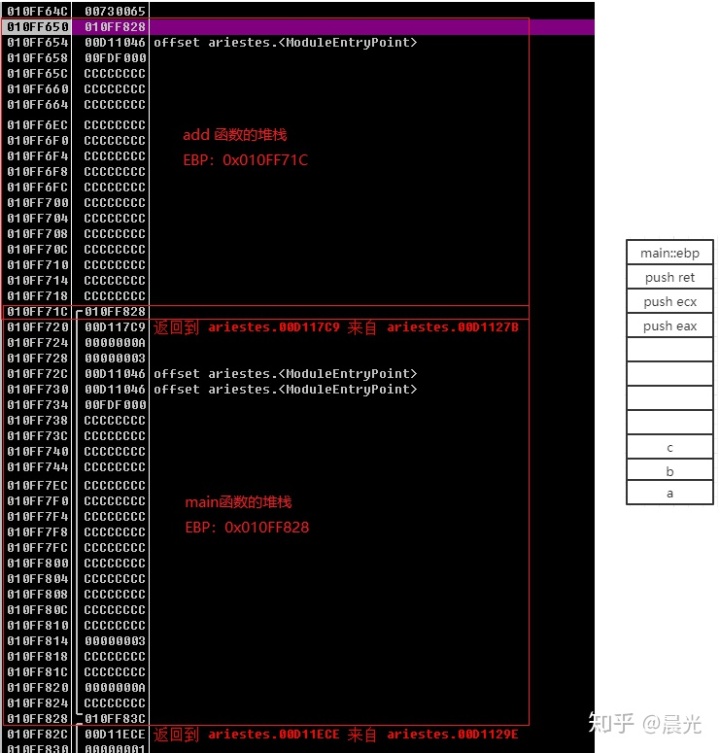
在栈中压入 a, b 两个参数,然后再压入了返回地址,这个地址很关键,因为它控制了执行完调用的函数后,应该返回到那个地址执行接下来的代码,我们常见的缓冲区溢出漏洞,就是通过溢出的字节码,来覆盖掉这个地址,使得返回地址跳转的自己的的地址,执行自己的 shellcode
下面的汇编比较简单,就是 add 函数里面实现了两个参数相加的汇编
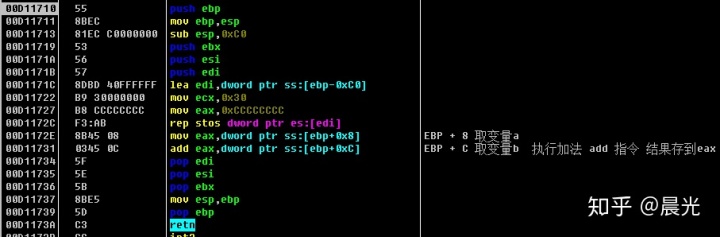
调用完成 add 函数后, 我们看到 ESP 通过加减的方式来增加和缩小自己当前的栈空间,最关键的是 add 函数中 a+b 的结果是通过寄存器 EAX 返回到了 main 函数中。
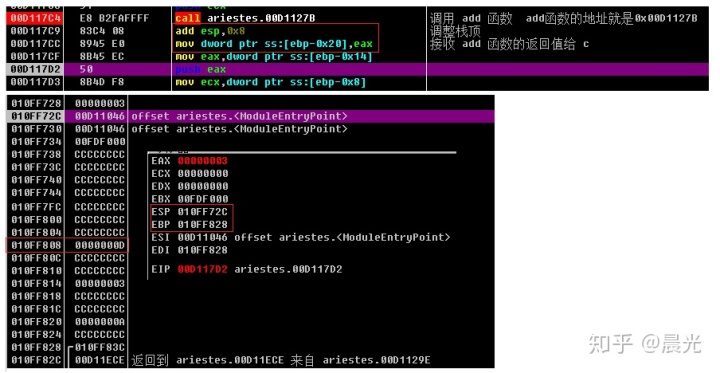
这就是一个完整的调用函数的流程,后面的 sub 函数也是这个流程。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









