






MyISAM 索引与数据的关系(非聚簇索引)
InnoDB索引与数据的关系(聚簇索引)
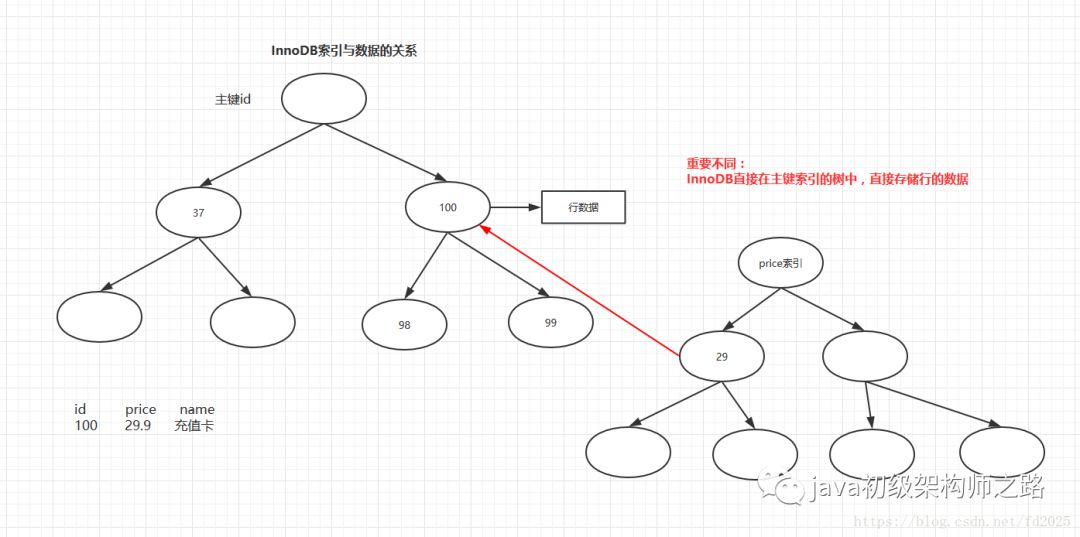
InnoDB的主索引文件上直接存放该行数据,称为聚簇索引,次索引指向对主键的引用。
MyISAM中,主索引和次索引 ,都指向物理行(磁盘位置);
注意:InnoDB来说
1. 主键索引,既存储索引值,又在 叶子中存储行的数据
2. 如果没有主键,则会Unique key做主键
3. 如果没有unique,则系统生成一个内部的rowid做主键
4.像innodb中,主键的索引结构中,既存储了主键值,由存储了行数据,这种结构称为"聚簇索引";
聚簇索引:
优势:根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势:如果碰到不规则数据插入时,总爱城频繁的页分裂
聚簇索引的页分裂过程:
聚簇索引的注意事项: 聚簇索引的主键值,应尽量数连续增长,而不是随机值(不要用随机字符串或UUID),否则造成大量的页分裂 与页移动。
高性能索引策略
对于 InnoDB而言,因为节点下有数据文件,因此节点的分裂将会比较慢,对于InnoDB的主键,尽量用整型,而且是递增的整型,如果是无规则的数据,将会产生页的分裂,影响速度。
索引覆盖:
索引覆盖 是指 如果查询的列恰好是索引的一部分,那么查询 只需要在索引文件上进行,不需要回行到磁盘再找数据。这种查询速度非常快,称为"索引覆盖"。
理想的索引:
1.查询频繁
2.区分度高
3.长度小
4.尽量覆盖常用查询字段
1.索引的长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多);
针对 列中的值,从左往右截取部分来建索引。
1: 截的越短,重复读越高,区分度越小,索引效果不好
2: 截的越长,重复读越低,索引效果越好,但带来的影响也越大-增删改慢,并间接影响查询速度
所以,我们要 区分度+长度 两者上取得一个平衡
常用手法:截取不同长度,并测试其区分度
mysql> select count(distinct left(word,6))/count(*) from dict;
对于一般的系统应用,区分度能达到0.1,索引的性能就可以接受。














 3728
3728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









