





本文是 Python 系列的特别篇的第十四篇
特别篇 1 - PyEcharts TreeMap
特别篇 2 - 面向对象编程
特别篇 3 - 两大利「器」
特别篇 4 - 装饰器
特别篇 5 - Sklearn 0.22
特别篇 6 - Jupyter Notebook
特别篇 7 - 格式化字符串
特别篇 8 - 正则表达式
特别篇 9 - 正则表达式实战
特别篇 10 - 错误类型
特别篇 11 - 异常处理
特别篇 12 - Collection
特别篇 13 - Matplotlib Animation
特别篇 14 - All 和 Any
今天星期五,不烧脑了,写一个简单的例子以飨大家。例子虽然简单,但还是有些东西可以学习的。
故事背景:判断一个正整数是不是质数。
逻辑很简单,对于一个数 n,只有从 2 到 n 做个循环,来检查 n 是不是被每个数能整除,如果是,那么 n 不是质数;如果不是,n 是质数。简单明了,代码如下。
def is_prime(n): for i in range(2, n): if n % i == 0: return False return True检验结果没问题。
print( is_prime(6) )print( is_prime(7) )False如果你就此满足,就太不 Pythonic 了。你看这上面 for + if + 两个 return 不觉得丑吗?反正我觉得丑。因此我准备用 Python 里面的 all() 函数来实现,先看看 all() 函数怎么用,用 help(all) 来查看。
help(all)Help 从上可知,all() 函数的参数是一个可迭代对象(iterable),像列表、元组、字典等等都是可迭代对象。不清楚的同学请参考【两大利器】此贴。
当所有元素都为 True 时,返回 True;只要有一个元素为 False,返回 False。
来我们验证几组,结果没问题。
all([1, 2, 3]all([1, 2, 0])all([1, 2, 'all'])all([[], 2, 'all'])True这时候需要了解一个知识点,看完就弄懂上面的结果了。
知识点 非布尔型变量也有相对性的布尔值,设该变量为 X当 X 是元素型变量(整型、浮点型)
当 X 为 0, 0.0,
bool(X) =False当 X 非零,
bool(X) =True
当 X 是容器型变量(字符串、列表、元组、字典、集合)
当 X 为空,
bool(X) =False当 X 不为空,
bool(X) =True
print( type(0), bool(0), bool(3) )print( type(10.31), bool(0.00), bool(10.31) )print( type(''), bool( '' ), bool( 'python' ) )print( type(()), bool( () ), bool( (10,) ) )print( type([]), bool( [] ), bool( [1,2] ) )print( type({}), bool( {} ), bool( {'a':1, 'b':2} ) )print( type(set()), bool( set() ), bool( {1,2} ) )class 'int'> False True好,我们现在开始用 all() 函数来实现找质数,那么最自然的就是先创建一个空列表,然后检查 n 是否能被每个元素 i 整除,是的话 n 不是质数,因此列表附加 False 值,反之列表附加 True 值。
def is_prime(n): divisible = [] for i in range(2, n): if n % i == 0: divisible.append(False) else: divisible.append(True) return all(divisible)结果虽然没问题,但更丑了,这怎么越改还越差了呢?
print( is_prime(11) )print( is_prime(12) )True来做点改进,直接在列表上附件表达式 n%i != 0,和上面的代码等价。
def is_prime(n): divisible = [] for i in range(2, n): divisible.append(n % i != 0) return all(divisible)结果没问题,但代码还是丑陋冗长。
print( is_prime(13) )print( is_prime(14) )TrueHello,这可是生成列表啊,那用列表解析式(list comprehension)啊!不清楚的同学请参考【盘一盘 Python 下篇】此贴第 5 章。
def is_prime(n): divisible = \ [n % i != 0 for i in range(2, n)] return all(divisible)检验结果没问题,而且代码漂亮了。但是如果 n 很大又刚好不是质数,那么按照判断逻辑,我们只要找到某个 i 使其可以整除 n 就已经可以判断 n 不是质数了,但是写成列表解析式我们还要把整个列表运行完!
print( is_prime(15) )print( is_prime(16) )False一个一个判断,只要到达某点就停,你想到了什么?对,生成器(generator)!
生成器是按需求调用 (call-by-need) 的,你需要调用一个值,我就 yield 一个值,然后用 next() 更新内部状态,等待你下次调用。这套流程也称作惰性求值 (lazy evaluation),目的是最小化计算机要做的工作。在大规模数据时,一次性处理往往抵消而且不方便,而惰性求值解决了这个问题,它把计算的具体步骤延迟到了要实际用该数据的时候。
改下代码,只用把列表解析式的方括号 [] 改成生成器的小括号 (),就完事了。
def is_prime(n): divisible = \ (n % i != 0 for i in range(2, n)) return all(divisible)检验结果当然没问题。
print( is_prime(17) )print( is_prime(18) )True那我们来看看两者的运行效率吧,为了方便比较,定义了两个函数:
is_prime_list_comprehension
is_prime_generator
def is_prime_list_comprehension(n): return all([n % i != 0 for i in range(2, n)])def is_prime_generator(n): return all((n % i != 0 for i in range(2, n)))例子 1:我找了个比较大的质数 131071,用 %timeit 魔法指令来显示运行时间。
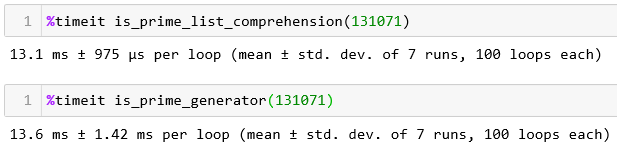
哈哈哈哈,傻眼了吧,生成器运行的时间 (13.6ms) 比列表解析式运行的时间 (13.1ms) 长。
再想想,当一个数的质数,两个函数都要从头运行到尾哦,13.6ms 和 13.1ms 可以看做一样的。
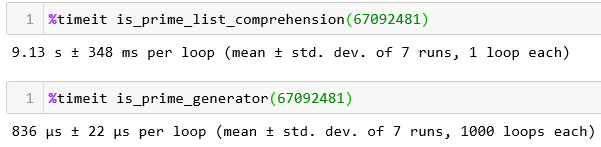
例子 2:在找一个比较大的非质数,试试 8191*8191 = 67092481,它肯定不是质数,而且也没那么快找出来,因为 8191 是质数,你品一下。
8191*8191
67092481再看两者运行对比结果,引起极度舒适。
你光讲了 all 函数,那 any 函数呢?类比一下嘛!
all( [x1, x2, ..., xn] ) 是所有 xi 都为 True 返回 True(all 的含义),反之返回 False。
any( [x1, x2, ..., xn] ) 是只要有一个 xi 为 True 就返回 True(any 的含义),反之返回 False。
因此,只要你见到下图左边的代码样子,你就可以用 all() + 生成器。

只要你见到下图左边的代码样子,你就可以用 any() + 生成器。

其实找质数也可以用 any() 函数来实现,代码如下:
def is_prime_use_any(n): return not any((n % i == 0 for i in range(2, n)))注意 any() 函数前面加了一个 not,而且表达式从 n%i != 0 改成 n%i = 0。意思就是说如果 n 可以被任何(any 的含义)i 整除,返回为 True,前面加个 not 就返回为 False,那么就不是质数。
我的天啊,绕不绕口?这代码反不反人性?再回顾一下优雅 all() 函数实现的代码吧。
def is_prime_use_all(n): return all((n % i != 0 for i in range(2, n)))说如果 n 不能被所有(all 的含义)i 整除,返回为 True,那么就是质数。
Yes, coding style is a progress!
Stay Tuned!
我的新书《快乐机器学习》
在新加坡终于有买了
扫码进 Lazada 购买
新加坡全岛包邮

我的新课《Python 基础》
扫码购买
零套路无前戏直接干货
上过的都说好

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









