





1 Scrapy 爬虫完整案例-基础篇
1.1 Scrapy 爬虫案例一
Scrapy 爬虫案例:爬取腾讯网招聘信息
案例步骤:
第一步:创建项目。
在 dos下切换到目录
D:爬虫_scriptscrapy_project
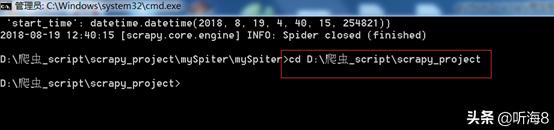
新建一个新的爬虫项目:scrapy startproject tencent
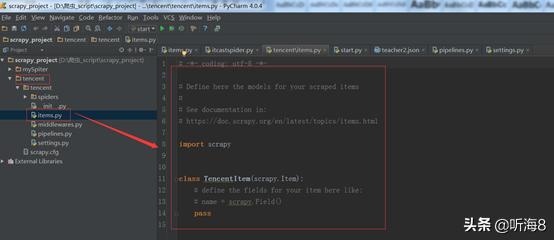
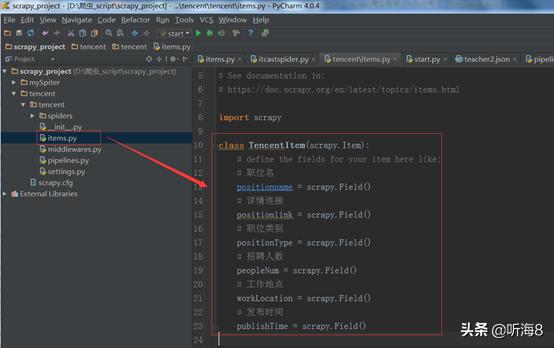
第二步:编写 items.py 文件,设置好需要保存的数据字段。
import scrapy
class TencentItem(scrapy.Item):
# 职位名
positionname = scrapy.Field()
# 详情连接
positionlink = scrapy.Field()
# 职位类别
positionType = scrapy.Field()
# 招聘人数
peopleNum = scrapy.Field()
# 工作地点
workLocation = scrapy.Field()
# 发布时间
publishTime = scrapy.Field()
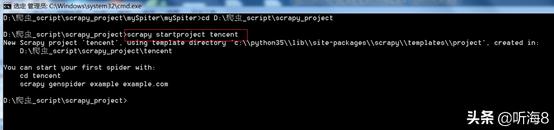
第三步:创建爬虫。
在 dos下切换到目录
D:爬虫_scriptscrapy_projectencentencentspiders
用命令 scrapy genspider tencents "tencent.com" 创建爬虫。
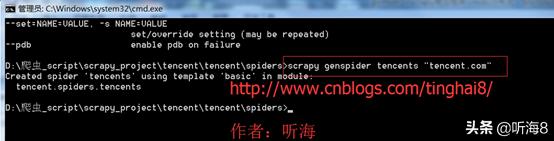
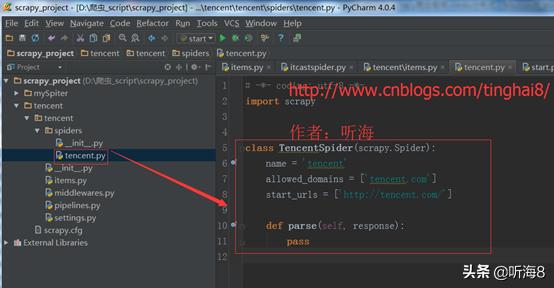
备注:因为用命令创建的时候,爬虫名称不能和域名tencent.com 一样,所以创建的时候,爬虫名为:tencents,创建完之后,可以把爬虫名修改成 tencent。
第四步:编写爬虫文件。
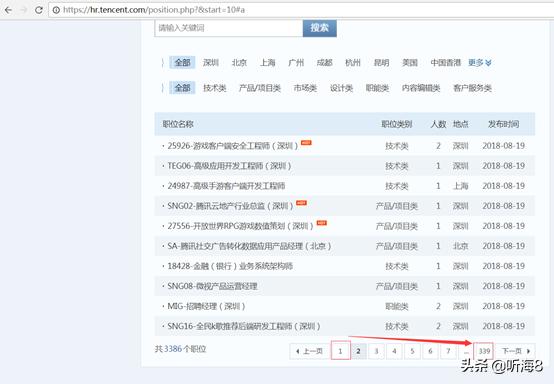
从图片中看到tencent招聘信息有339页。
第一页的链接地址:
https://hr.tencent.com/position.php?&start=0
第二页的链接地址:
https://hr.tencent.com/position.php?&start=10
最后一页的链接地址:
https://hr.tencent.com/position.php?&start=3380
通过分析我们得知,每一页的的链接地址start的值递增10,就是下一页的地址。
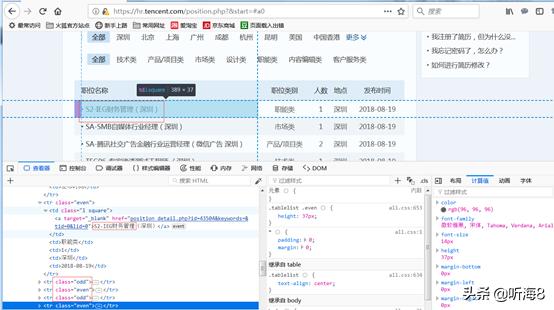
通过对页面的分析,得出需要保存的数据字段在页面上的位置。
info= response.xpath("//tr[@class='even'] | //tr[@class='odd']")
each in info
# 职位名
item['positionname'] = each.xpath("./td[1]/a/text()").extract()[0]
# 详情连接
item['positionlink'] = each.xpath("./td[1]/a/@href").extract()[0]
# 职位类别
item['positionType'] = each.xpath("./td[2]/text()").extract()[0]
# 招聘人数
item['peopleNum'] = each.xpath("./td[3]/text()").extract()[0]
# 工作地点
item['workLocation'] = each.xpath("./td[4]/text()").extract()[0]
# 发布时间
item['publishTime'] = each.xpath("./td[5]/text()").extract()[0]
编写完整的爬虫文件。
import scrapy,sys,os
path = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
#print(path)
sys.path.append(path)
from tencent.items import TencentItem
class TencentpositionSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["tencent.com"]
url = "http://hr.tencent.com/position.php?&start="
offset = 0
start_urls = [url + str(offset)]
def parse(self, response):
info= response.xpath("//tr[@class='even'] | //tr[@class='odd']")
for each in info:
# 初始化模型对象
item = TencentItem()
item['positionname'] = each.xpath("./td[1]/a/text()").extract()[0]
# 详情连接
item['positionlink'] = each.xpath("./td[1]/a/@href").extract()[0]
# 职位类别
item['positionType'] = each.xpath("./td[2]/text()").extract()[0]
# 招聘人数
item['peopleNum'] = each.xpath("./td[3]/text()").extract()[0]
# 工作地点
item['workLocation'] = each.xpath("./td[4]/text()").extract()[0]
# 发布时间
item['publishTime'] = each.xpath("./td[5]/text()").extract()[0]
#将获取的数据交给管道文件 pipelines ,yield的作用是把一个函数当成一个生成器,程序每次执行到yield时,返回一个值,程序会先暂停,下次调用再返回一个值,程序会接着暂停....
yield item
if self.offset < 3390:
self.offset += 10
# 每次处理完一页的数据之后,重新发送下一页页面请求
# self.offset自增10,同时拼接为新的 url,并调用回调函数 self.parse 处理 Response
yield scrapy.Request(self.url + str(self.offset), callback = self.parse)
第五步:编写管道文件:TencentPipeline。
import json
class TencentPipeline(object):
# __init__方法是可选的,做为类的初始化方法
def __init__(self):
# 创建了一个 tencent.json 文件,用来保存数据
self.filename = open("tencent.json















 7440
7440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









