





全文共 3482字,预计学习时长 7分钟

如今,大家都在Python工具(pandas和Scikit-learn)的简洁性、Spark和Hadoop的可扩展性以及Kubernetes的操作就绪之间做选择。结果是,选择应用了以上所有工具。主攻Python的数据科学家、精通Java和Scala Spark的大师和一批开发者,他们三批人马保持独立,分别管理解决办法。
数据科学家们用pandas进行探索。然后,其他的数据工程师团队重新编写相同的逻辑代码并使其大规模工作,或者使用Spark令其与实时流一同工作。当数据科学家需要更改逻辑或将一个不同的数据集用于他/她的模型时,则会进行一次次地迭代。
除了注意业务逻辑之外,还要分别或同时在Hadoop和Kubernetes构建集群,并应用整个CI / CD过程手动进行管理。最重要的是,大家都在努力工作,没有足够的业务影响来展示它......
如果你想在Python中编写简单代码,并且用比Spark更快的速度运行,同时无需重新编码、无需开发者解决部署、扩展和监控问题,可能吗?
你可能会“说我是一个梦想家”。我是一个梦想家,但不是唯一的一个!本篇文章将证明如今可以使用Nuclio和RAPIDSlimg令以上设想成为现实,它们是由NVIDIA孵化的免费开源数据科学加速平台。
过去几个月,有人将RAPIDS与Nuclio开源无服务器项目和Iguazio的PaaS集成在一起。现在,使用相同的Python代码会拥有更快的数据处理速度和可扩展性,并且由于采用无服务器方法,其操作开销可达到最低水平。
本文将对同样广受欢迎的实时数据的用例进行演示,它们由基于Json的日志组成。本文将根据以上数据完成分析任务,并将聚合结果转储为压缩的Parquet格式,便于进一步的查询或机器学习训练。本文将研究批和实时流(是的,使用简单Python代码的实时流)。但开始之前,先进行总体概述。
是什么导致Python既慢又无法扩展?
在小型数据集上使用pandas时,其性能表现不错,但这只发生在整个数据集适合内存且在pandas和NumPy层下使用已优化的C代码进行处理的情况下。处理大量数据包含集中的的IO操作、数据转换、数据拷贝等,拖慢了处理的速度。从本质上讲,臭名昭著的GIL 给Python带来了线程同步的困难,在处理复杂任务时非常低效,异步Python相对更好,但其开发复杂且无法解决固有的锁定问题。
像Spark这样的框架具有异步引擎(Akka) 和内存优化数据布局的优势,它们可以将工作分配给不同机器中的多个工作人员,从而提高性能和可扩展性,并使其成为实际标准。
RAPIDS帮助Python开挂
英伟达想出了绝佳的点子:保留面向Python的API(接口)中受欢迎框架,如pandas、Scikit-learn和,而在GPU的高性能C代码中处理数据。他们采用内存友好型的ApacheArrow 数据格式,以加速数据传输和操作。
RAPIDS支持数据IO (cuIO), 数据分析(cuDF)和机器学习(cuML).这些不同组成部分共享相同的内存结构,因此基本上可以在不将数据来回复制到CPU中的情况下完成数据摄取、分析和机器学习的过程。
以下示例演示了读取大型Json文件(1.2GB)的实例,其使用pandas API聚合数据。可以看到,使用RAPIDS运行相同的代码,速度如何增快30倍(完整Notebook:https://github.com/nuclio/rapids/blob/master/demo/benchmark_cudf_vs_pd.ipynb),与没有IO的计算相比,它快了100倍,这意味着还有对数据进行更为复杂计算的余地。

本文使用单GPU (NVIDIA T4) 它可以使服务器价格增加约30%,性能提升30多倍。只使用几行Python代码,每秒就可处理1千兆字节的复杂数据。哇!!
如果将此代码打包在无服务器函数中,它可以在每次用户请求时或定期运行,并读取或写入动态附加的数据卷。
Python中可实现实时流吗?
你是否尝试使用Python执行实时流式传输?好吧,我们做到了。以下代码选取自Kafka最佳实践指南,此代码从流中读取,同时并未额外处理。
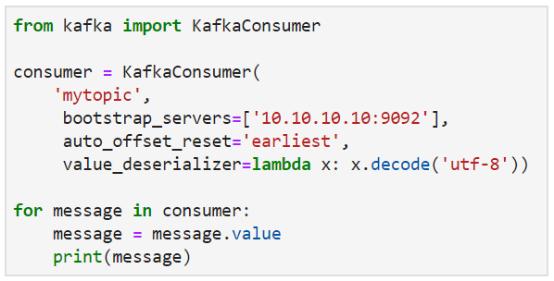
问题在于Python本质上是同步的,而其在实时或复杂的数据操作方面效率相当低。该程序每秒只生成几千条消息,而且还没做任何有意思的工作。当我们添加前文示例中使用的json和pandas处理(Notebook:https://github.com/nuclio/rapids/blob/master/demo/python-agg.ipynb)时,性能会进一步降低,处理速度仅为18MB / s。那么,是否需要回到Spark进行流处理呢?
不,等等。
最快的无服务器框架是Nuclio,现在它也是Kubeflow(Kubernetes机器学习框架)的一部分。Nuclio运行由实时和高度并发的执行引擎包装的各种代码语言。Nuclio无需额外编码,可并行运行多个代码实例(使用高效的微线程)。Nuclio处理流程内和多个流程/容器中的自动扩展(请参阅此技术报道博客:https://theburningmonk.com/2019/04/comparing-nuclio-and-aws-lambda/)。
Nuclio以高度优化的二进制代码处理流处理和数据访问,并通过简单的函数处理程序调用函数。它支持14种不同的触发或流协议(包括HTTP、Kafka, Kinesis、Cron和批),这些协议通过配置指定(不更改代码),并支持快速访问外部数据卷。单个Nuclio函数每秒可处理数十万条消息,吞吐量超过千兆字节/秒。
最重要的是,Nuclio是目前唯一一款具有优化NVIDIA GPU支持的无服务器框架。它知道如何确保GPU利用率最大化,并在需要时扩展到更多流程和GPU。
笔者对Nuclio持保留意见,但它的功能的确很先进。
无需Devops的30倍速度流处理
结合使用Nuclio与RAPIDS,基于Python流处理获得GPU加速,最终实现完美蜕变。以下代码与批处理案例别无二异,本文只是将其置于一个函数处理程序中,并将传入的消息收集到更大的批中以减少GPU调用。(请参阅完整笔记本:https://github.com/nuclio/rapids/blob/master/demo/nuclio-cudf-agg.ipynb)
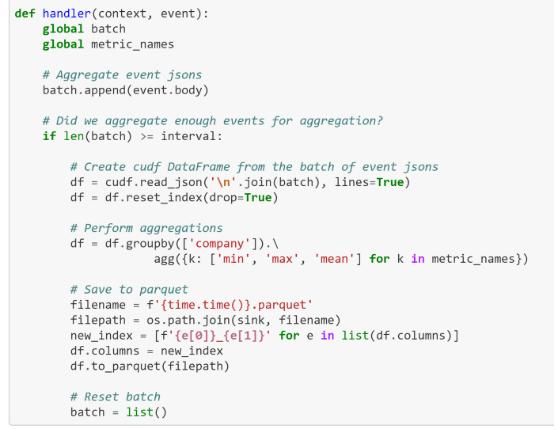
可以使用HTTP或Kafka触发器测试同一个函数:在两种情况下,Nuclio都将处理并行性,并将流分区划分给多个工作人员,无需任何额外开发工作。本文测试的设置是使用3节点Kafka集群和单个Nuclio函数进程(在具有一个NVIDIA T4的双插槽Intel服务器上)。本文设法处理638 MB / s,比编写自己的Python Kafka客户端快30倍,并且它可以自动扩展以处理任何数量的流量。值得一提的是,所使用Python代码短小而简单!
在测试中,笔者注意到GPU未充分利用,这意味着可以对数据进行更复杂的计算(连接、机器学习预测、转换等),同时保持相同的性能水平。
那么,也就是以更少的开发获得更快的性能,但无服务器解决方案的真正好处在于“无服务器”。使用相同的代码,在Notebook中进行开发 (请参阅此笔记本示例:https://github.com/nuclio/rapids/blob/master/demo/nuclio-cudf-agg.ipynb) 或选用你喜欢的IDE,并在一个命令中对其进行构建、集装箱化并运送到有完整检测功能、已安全加固的的Kubernetes集群(日志、监控、自动缩放......)。
Nuclio与Kubeflow管道集成。构建多阶段数据或机器学习管道,你可以轻松地实现数据科学工作流自动化,并收集执行和工件元数据,从而轻松地重现实验结果。
下载Nuclio(https://nuclio.io/)并将其部署在你的Kubernetes上(请参阅RAPIDS示例:https://github.com/nuclio/rapids)。

留言 点赞 关注
我们一起分享AI学习与发展的干货
如需转载,请后台留言,遵守转载规范
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









