





参考:《java并发编程之美》
此问题的思考源于机器视觉的老师在上课时的一波话题扩展,后面在最近学习的《java并发编程之美》中看到了原理性的解释,和最近学习的操作系统的基础知识有联系了起来,所以特地写下此文(虽然大都摘抄于书,只因觉得作者的表述已经再好不过了,目的是学习嘛)
请先看两段代码:
第一段:
public class Cache {
static final int LINE_NUM = 10240;
static final int COLUM_NUM = 10240;
public static void main(String[] args) {
long[][] array = new long[LINE_NUM][COLUM_NUM];
long startTime = System.currentTimeMillis();
for (int i = 0; i < LINE_NUM; i++) {
for (int j = 0; j < COLUM_NUM; j++) {
array[i][j] = i * 2 + j;
}
}
long endTime = System.currentTimeMillis();
long cacheTime = endTime - startTime;
System.out.println("cacheTime= " + cacheTime);
}
}第二段:
public class Test {
static final int LINE_NUM = 10240;
static final int COLUM_NUM = 10240;
public static void main(String[] args) {
long[][] array = new long[LINE_NUM][COLUM_NUM];
long startTime = System.currentTimeMillis();
for (int i = 0; i < LINE_NUM; i++) {
for (int j = 0; j < COLUM_NUM; j++) {
array[j][i] = i * 2 + j;
}
}
long endTime = System.currentTimeMillis();
long cacheTime = endTime - startTime;
System.out.println("cacheTime= " + cacheTime);
}
}这两段代码是计算双重for循环访问二维数组的运行时间,然后差异就是最中间的访问数组的方式:
第一段是array[i][j],第二段是array[j][i].
也就是说,第一段是以一行行的形式访问二维数组,第二段是以一列列的形式访问二维数组。
大家猜猜结果是啥?也就是哪段代码用的时间长?或者说一样长? 然后你得出这个结果的依据是什么?
让我来公布答案吧。
在我的win10电脑上运行,第一段代码的的输出是:224左右 (并不是稳定不变的时间,只是在一个小范围内波动)
第二段代码的输出是:2300左右
why?(此处可加一张黑人问号脸)
因为一行行访问?
或者说因为地址连续?
根本原因是啥?
因为cpu在运行代码的时候是有缓存行这一说法的。
然后来科普计算机基础知识:
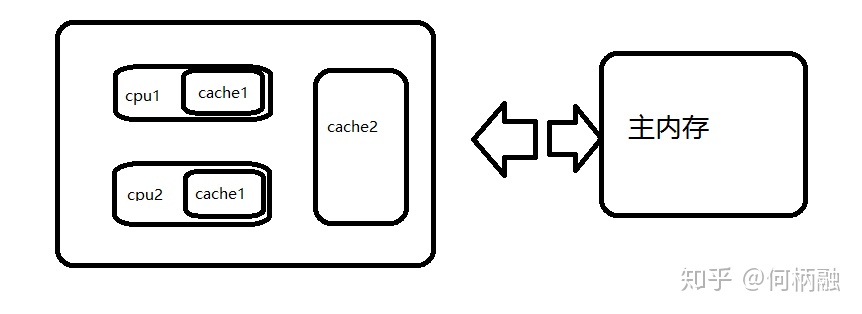
为了解决计算机系统中主内存与CPU之间运行速度差的问题,会在CPU与主内存之间添加一级或者多级高速缓冲存储器(Cache)。这个Cache一般是被集成到CPU内部的,所以也叫CPU Cache。如下图所示是两级Cache结构。
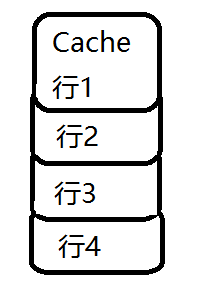
在Cache内部是按行存储的,其中每一行称为Cache行(缓存行)。Cache行是Cache与主内存进行数据交换的单位。缓存行的大小一般为2的幂次数字节。下图为缓存行示意图:
当CPU去访问某个变量时,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存复制到Cache中。由于存放到Cache行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache行中。
所以,回到我们前面提到的双重for循环访问二维数组的时间问题。
我们都知道,二维数组的存放地址是这样的:
比如定义一个3x3的int类型的二维数组,即每个元素占四个字节,那么就有如下示意图:
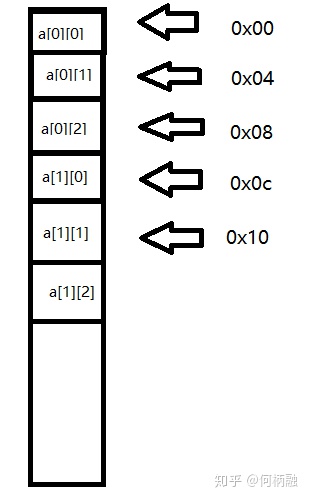
这里是用16进制表示地址0x0c表示12,我们都知道数组的存放地址是连续的,二维数组则是下一行的地址接着在这一行的尾地址上继续添加。所以也是地址也是连续的。
这样的话,当访问数组第一个元素时,会把第一个元素后的若干元素一块放入缓存行,这样顺序访问数组元素时就会在缓存中命中,因而就不会去主内存读取了,后续访问也是这样。也就是说,当顺序访问数组里面的元素时,如果当前元素在缓存没有命中,那么会从主内存一下子读取后续若干个元素到缓存,也就是一次内存访问可以让后面多次访问直接在缓存中命中。而第二段代码是跳跃式访问数组元素的,不是顺序的,这破坏了程序访问的局部性原则,并且缓存是有容量控制的,当缓存满了时会根据一定淘汰算法替换缓存行,这会导致从内存置换过来的缓存行的元素还没等到被读取就被替换掉了。
所以,在单个线程下顺序修改一个缓存行中的多个变量,会充分利用程序运行的局部性原则,从而加速了程序的运行。
好了,关于前面两段代码的讨论就到此为止了。相信大家应该对这个问题已经有了比较深入的了解。
前面讲了很多次程序的局部性原理,那么什么是局部性原理呢?
局部性原理:
时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次被执行;如果某个数据被访问过,不就之后该数据很有可能再次被访问。(因为程序中存在大量的循环)
空间局部性:一旦程序访问了某个存户单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)。
时间局部性和空间局部性统称为局部性原理。
前面的例子就是空间局部性的应用。详细有了前面的例子,大家应该很好理解前面这段定义的意思了。局部性原理在操作系统和程序代码上有很多方面的应用,比如虚拟内存技术,还有逻辑地址到物理地址转换时的快表机构等等。所以,感觉深刻地了解这个原理还是很有必要的。
说了那么多局部性原理的应用,也来说一下局部性原理对我们不太友好的地方吧。
前面说了,在单个线程下顺序修改一个缓存行中的多个变量,会充分利用程序运行的局部性原理,从而加速了程序的运行。而在多线程下,并发修改一个缓存行中的多个变量时就会竞争缓存行,从而降低程序运行性能。这属于并发方面的话题了。
具体一点就是,把多个变量放在一个缓存行中,当多个线程同时修改一个缓存行里面的多个变量时,由于只能有一个线程操作缓存行,所以相比将每个变量放到一个缓存行,性能会有所下降,这就是伪共享。如下图所示:(仿照书上的图画的,比较潦草)
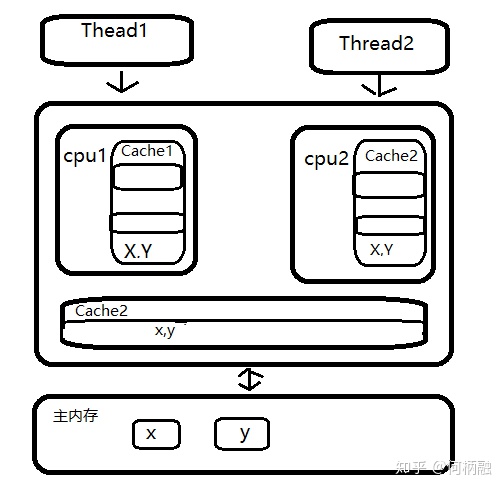
在该图中,变量X,Y同时被放到了cpu的一级和二级缓存,当线程1使用cpu对变量x进行更新时,首先会修改cpu1的一级缓存变量x的所在的缓存行,这时候在缓存一致性协议下,cpu2中变量x对应的缓存行失效。那么线程2在写入变量x时就只能去二级缓存里查找,这就破坏了一级缓存。而一级缓存比二级缓存更快,这也说明了多个线程不可能同时去修改自己所使用的cpu中相同的缓存行里面的变量。更坏的是,如果cpu只有一级缓存,则会导致频繁的访问主存。(上文直接摘自《java编程之美》,我觉得作者后面可能笔误写得不太科学,这里说线程2在写入变量x时就只能去二级缓存查找,而在这段内容中强调的是缓存行,所以我觉得应该是线程2在写入变量x所在缓存行的任何变量时,都只能去二级缓存里查找,二级缓存或者主存中有正确的修改过的值)
那么,java是如何避免伪共享的呢?
在jdk8以前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中,例如如下代码:
public final static class FilledLong{
public volatile long value=0L;
public long p1,p2,p3,p4,p5,p6;
}假如缓存行为64字节,那么我们在FilledLong类里面填充了6个long类型的变量,每个long类型的变量占用8字节,加上value变量的8字节总共占56字节。另外,这里FilledLong是一个类对象,而类对象的字节码对象头占用8个字节,所以一个FilledLong对象实际会占用64字节的内存,这正好可以放入一个缓存行。
jdk8提供了一个sun.misc.Contended注解,用来解决伪共享问题。将上面代码修改如下:
@sun.misc.Contended
public final class FilledLong{
public volatile long value =0L;
}在这里用来修饰类,当然也可以修饰变量,比如在thread类中:(也就是说,前面的方法只能作用在类内)
@sun.misc.Contended("tlr")
int threadlocalrandomprobe;需要注意的是,在默认情况下,这个注解只用于java核心类,比如rt.jar下的类,入股用户路径下的类需要使用这个注解,则需要添加JVM参数:-XX:-RestricContended。填充的宽度默认为128,要自定义宽度则可以设置-XX:ContendedPaddingWidth参数。
(原理是在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突)
Java8使用@sun.misc.Contended避免伪共享 这篇文章对这个话题做了非常详细的解释,有兴趣的可以好好了解一下。
嗯,到这里我们已经对缓存行有了比较深入的认识和理解了。总结一下就是,最开始我们对单线程情况下访问同一个缓存行的多个变量对程序的运行起到加速作用做了形象的理解,后面对多线程情况下访问同一个缓存行的多个变量时会出现伪共享的原理做了讨论,并且最后给出了jdk的解决方案。
希望大家能从此文中收获到东西。
欢迎交流讨论。














 4681
4681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









