





继续介绍,下面是最近半年的论文(2019-2020年)。
•Pix2Pose: Pixel-Wise Coordinate Regression of Objects for 6D Pose Estimation (2019.8)
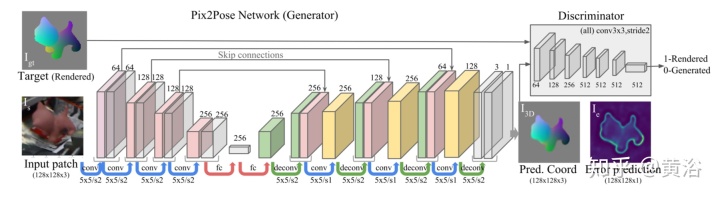
由于存在诸如遮挡和对称性等问题,仅使用RGB图像估计目标的6D姿势仍然具有挑战性。没有专家知识或专门的扫描设备,也很难构建具有精确纹理的3D模型。为了解决这些问题,它提出了一种姿态估计方法Pix2Pose,它可以在没有纹理模型的情况下预测每个目标像素的3D坐标。该文设计一个自动编码器(auto-encoder )体系结构,旨在估计每个像素的3D坐标和误差。然后,这些按像素进行的预测在多步中形成2D-3D对应关系,直接用RANSAC迭代的PnP算法计算姿态。该方法通过对抗性生成训练来精确地恢复被遮挡的部分,其对遮挡是鲁棒的。此外,提出了一种损失函数,即变换器损失(transformer loss),将预测引导至最接近的对称姿态来处理对称目标。
下图是模型架构图和训练流水线:
Pix2Pose用目标的裁剪区域预测单个像素的3D坐标。通过恢复被遮挡部分的3D坐标并运用目标区域的所有像素进行姿势预测,建立鲁棒估计。
训练一个单一网络用于每个目标类。3D模型的纹理对于训练和推理不是必需的。网络输入是检测目标类别的边框的裁剪图像。
网络输出是目标坐标中每个像素的标准化3D坐标以及来自Pix2Pose网络每个预测的估计误差。目标输出(target output)通过在真实姿态下绘制彩色坐标模型,可以轻松导出真实输出。
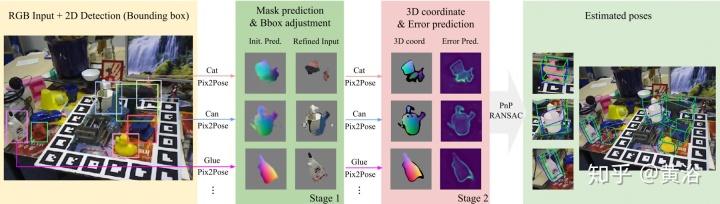
下图是一个姿势估计过程的示例。 图像和二维检测结果作为输入。 第一阶段,预测结果用于指定重要像素并调整边框,同时去除背景和不确定像素。 第二阶段,有效坐标值和较小误差预测的像素,用附加RANSAC的PnP算法来估计姿态。 结果中,绿线和蓝线表示真实姿势和估计姿势的目标3D边框。
如图是一些结果示例:

•Accurate 6D Object Pose Estimation by Pose Conditioned Mesh Reconstruction (2019.10)
当前的6D目标姿势估计方法由针对单个目标完全优化的深CNN模型组成,但其结构在具有不同形状的目标之间进行了标准化。这项工作明确地利用了每个目标的独特拓扑信息,即在任何后期处理优化之前,其姿态估计模型中的3D密集网格(dense meshes)。
为此,它提出了一个学习框架,其中图卷积神经网络(Graph Convolutional Neural Network )重构了目标的姿态条件3D网格(pose conditioned 3D mesh)。
在规范和重构密集3D网格之间可微分地计算Procrustes对齐(Procrustes’ alignment),可恢复同心圆朝向(allocentric orientation)的估计。使用附加模版和2D质心投影,自中心姿势(egocentric pose)估计可以提升到6D。通过测量重构网格的质量可验证其姿势估计。
如图是姿态估计的流水线图:
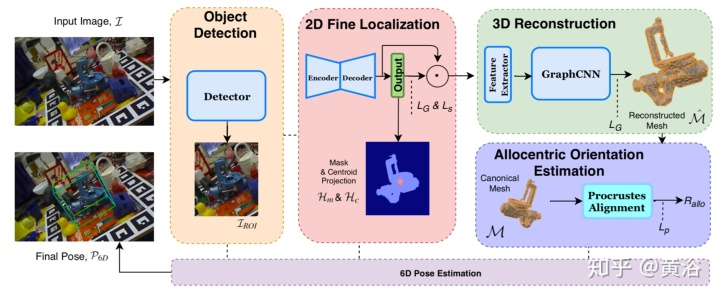
给定单眼RGB输入图像,目标是估计刚性物体的完整6D姿势。它旨在通过充分利用目标的先验信息,以自动化的方式设计每个目标不同的体系结构。重建阶段将已知目标的拓扑与图像提取的编码姿态信息结合在一起。估计的网格信息用于恢复目标的同心轴朝向。用预训练的基于FasterRCNN的2D目标检测器,采用训练数据进行微调,以检测2D空间中的目标。该检测器用于裁剪目标ROI,用于高分辨率,在流水线的下一阶段提取目标外观的精细细节。注意,该特设(ad hoc)检测器是独立训练的。
如图是一些定性结果例子:

•DeepIM: Deep iterative matching for 6d pose estimation (2019.10)
尽管近来的几种技术已将深度相机用于目标姿态估计,但是这种相机在帧速率、视场、分辨率和深度范围方面具有局限性,这使得很难检测小、薄、透明或快速移动的物体。从图像估计目标6D姿势是各种应用(例如机器人操纵和虚拟现实)中的重要问题。虽然将图像直接回归到目标姿态的准确性有限,但是将目标的渲染图像与输入图像进行匹配可以产生准确的结果。
这项工作为6D姿势匹配提出了一个名为DeepIM的深度神经网络。在给出初始姿势估计的情况下,该网络能够通过将渲染的图像与观察到的图像进行匹配来迭代地改善姿势。用3D位置和3D方向的解缠表示法(disentangled representation)以及迭代训练过程对网络训练预测其相对姿态变换。DeepIM能够匹配以前没见过的目标。
如图所示是DeepIM的示意图。 训练网络预测其相对SE(3)转换,该转换可以应用于初始姿势估计并进行迭代的姿势优化。 给定目标的6D姿势估计(无论是来自PoseCNN还是来自先前迭代的姿势)以及目标的3D模型,它都会在粗略姿势估计下生成显示目标外观的渲染图像。 利用渲染图像和观察图像的图像对,网络可以预测相对变换,该变换可用于完善输入姿势估计。
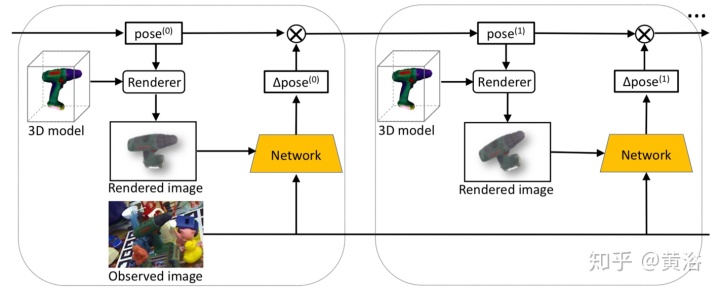
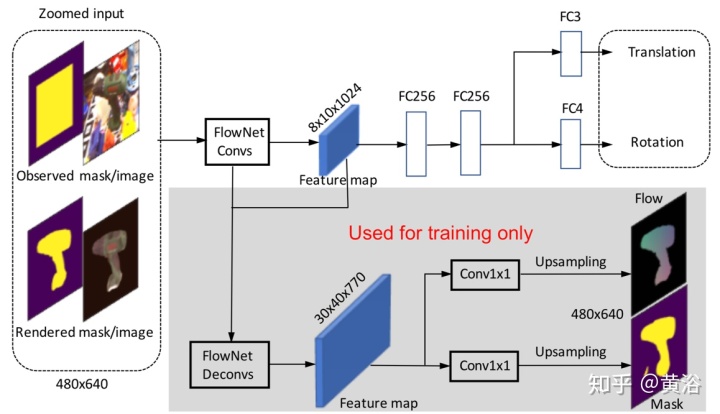
观察到的图像、渲染的图像和两个模版被连接到网络的8通道张量输入(对于观察/渲染的图像为3通道,每个模版为1通道)。它使用FlowNetSimple架构作为骨干网络,该网络经过训练可以预测两个图像之间的光流。姿势估计分支将FlowNetSimple的10个卷积层之后的特征图作为输入。它包含两个全连接层,每个层的尺寸均为256,然后是两个附加的全连接层,分别用于预测3D旋转的四元数和3D平移。在训练过程中,两个辅助分支可以规范化网络的特征表示,并提高训练的稳定性和性能。训练一个分支以预测渲染图像和观察图像之间的光流,另一分支被训练以预测在观察图像中模版的前景模版。其原理直观图如下图所示。
最后是一些试验结果示例:

•CDPN: Coordinates-Based Disentangled Pose Network for Real-Time RGB-Based 6-DoF Object Pose Estimation (ICCV, 2019)
从单个RGB图像进行6自由度目标姿态估计是计算机视觉中一个基本且长期存在的问题。当前的领先方法是通过训练深度网络来解决该问题的,该网络可以直接从图像中回归旋转和平移;也可以构建2D-3D对应关系,并进一步通过PnP方法间接解决。
作者认为旋转和平移的显着差异应区别对待。 这项工作提出了一种新颖的6自由度姿势估计方法:基于坐标的解缠姿势网络(CDPN,Coordinates-based Disentangled Pose Network),该方法可以解开姿势分别预测旋转和平移,实现高度准确和鲁棒的姿势估计。这种方法灵活和高效,可以处理没有纹理和被遮挡的目标。
其步骤如图所示,给定输入图像,先放大目标,然后解开旋转和平移以进行估计。 具体而言,旋转是通过PnP从预测的3D坐标中解决的,而平移则直接从图像中估算出来。
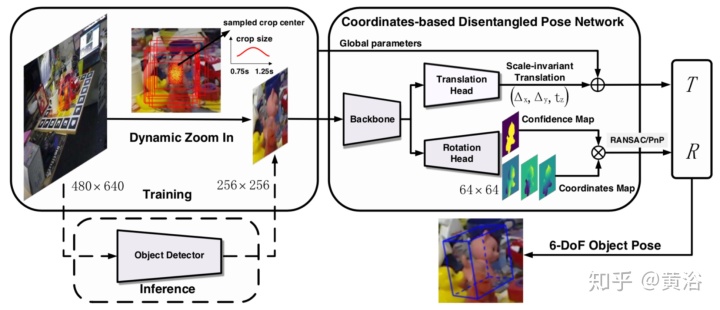
首先,其使用快速轻便的检测器(例如微型YOLOv3)进行粗略检测;其次,实现固定大小的分割以提取目标像素。对于检测,姿态估计系统可以在很大程度上归因于动态放大(DZI,Dynamic Zoom-In),因此可以忍受检测误差,故快速但精度较低的检测器就足够了。
分割,将其合并到坐标回归,足够轻和快。这个两步流水线可以在各种情况下有效地提取准确的目标区域。在平移方面,为了获得更鲁棒和准确的估计,从图像而不是2D-3D对应关系进行预测,以避免在预测的3D坐标中受到比例误差的影响。缩放不变平移估计(SITE)方法不是从整个图像上回归平移,而是从检测到的目标区域估计平移。这样,将有关旋转和平移的解缠结过程统一到单个网络中,即基于坐标的解缠姿势网络(CDPN)。
下面是一些结果例子:

•DPOD: 6D Pose Object Detector and Refiner (ICCV, 2019)
本文提出了一种仅从RGB图像进行3D目标检测和6D姿态估计的深度学习方法。此方法称为(DPOD,Dense Pose Object Detector)密集姿势目标检测器,用于估计输入图像和可用3D模型之间的密集多类2D-3D对应图。给定对应关系,可通过PnP和RANSAC计算6DoF姿态。基于深度学习的定制细化方案对初始姿态估计值进行细化。
与其他用真实数据而不在合成渲染数据进行训练的方法不同,它对合成和真实训练数据都进行评估,与最近的检测器相比,在细化之前/之后均显示出优异的结果。尽管很精确,但所提出的方法仍具有实时能力。
如图所示是DPOD的架构图。
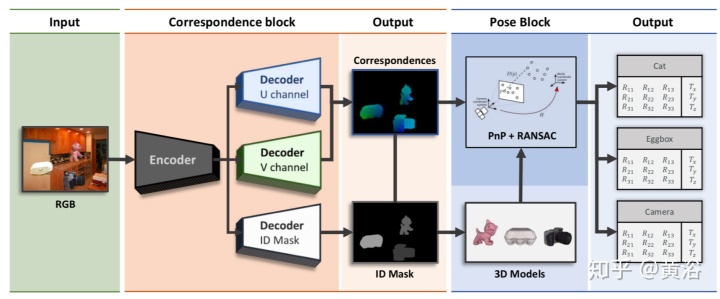
给定输入的RGB图像,具有编码器-解码器神经网络的对应块回归目标ID掩码和对应图。 后者提供了明确的2D-3D对应关系,而目标ID掩码则估算了每个检测目标应采用的对应关系。 然后,姿势模块基于PnP + RANSAC有效地计算各个6D姿势。
DPOD的推理流水线分为两个模块:对应模块和姿势模块。对应块由具有三个解码器头的编码器-解码器CNN组成,它们从大小为320×240×3的RGB图像中回归目标ID掩码和密集的2D-3D对应图。编码器部分基于类似ResNet的12层架构,具有残差层,可加快收敛速度。解码器使用一堆双线性内插和卷积层将特征上采样到其原始大小。
姿势块负责姿势预测:给定估计的目标ID掩码,观察在图像中检测到哪些目标及其2D位置,而对应图将每个2D点映射到实际3D模型的坐标。然后,使用PnP(Perspective-n-Point)姿势估计方法去估计6D姿势。该方法在给定对应关系和照相机固有参数的情况下可估计照相机姿势。
最后还有一个细化架构,如下图所示:网络会根据初始姿态建议预测精炼姿态。 真实图像和渲染的作物被馈送到两个平行的分支中。 计算出的特征张量之差是为了估计精确的姿势。
最后一些结果例子:

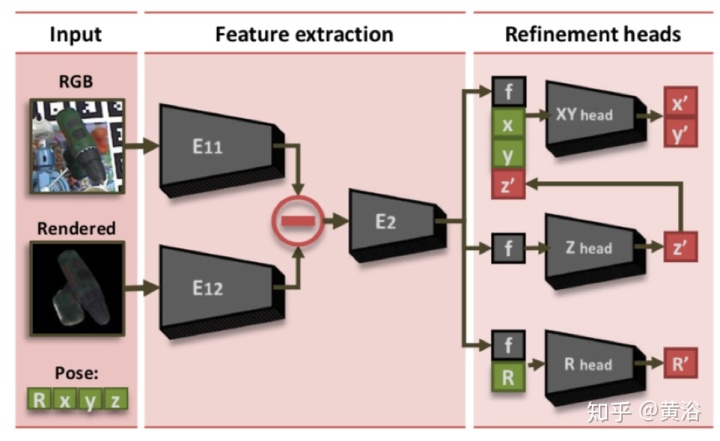
•ConvPoseCNN: Dense Convolutional 6D Object Pose Estimation (2019.12)
基于特征和基于模板的方法广泛用于6D目标姿态估计。基于特征的方法依赖于可区分的特征,并且对于纹理较差的目标表现不佳。如果目标被部分遮挡,则基于模板的方法将无法正常工作。随着深度学习方法成功地解决了一些图像相关的问题,启发或扩展这些模型已得到越来越多的使用。对称目标对方位估计提出了特殊的挑战,因为存在多个解决方案或解决方案的多种形式。
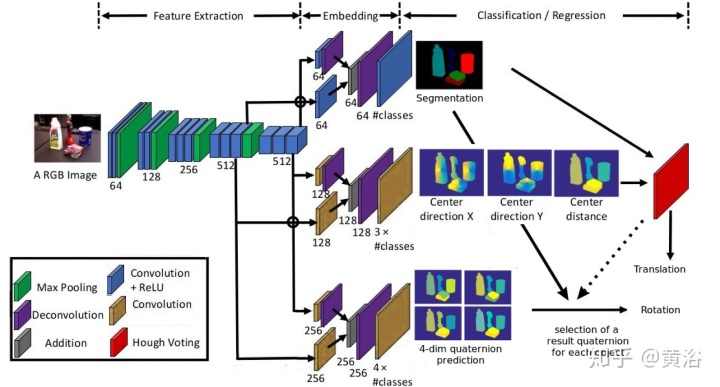
这项工作介绍了ConvPoseCNN,一种全卷积体系结构,避免裁剪出单个目标。它提出了目标姿态的平移和朝向分量的像素级密集预测,其中密集朝向以四元数形式表示。它提出了用于密集朝向预测的不同聚合方法,包括平均和聚类方案。密集朝向预测隐式地学习如何对付无遮挡且特征丰富的目标区域。下图是ConvPoseCNN的示意图:
如下图所示:从PoseCNN派生的ConvPoseCNN体系结构,从RGB图像预测每个目标的6D姿势。该网络从提取特征的VGG16的卷积主干开始。随后在三个分支中对它们进行处理:预测像素级语义分割的全卷积分割分支,预测中心朝向和深度像素级估计的全卷积顶点分支,以及四元数估计分支 。分割和顶点分支结果组合在一起,在Hough变换层中为目标中心投票。Hough变换层还预测检测目标的边框。然后,PoseCNN使用这些边框来裁剪和合并提取的特征,再将这些特征输入到全连接的神经网络体系结构中。该全连接部分预测每个边框的朝向四元数。
一些定性结果示例:

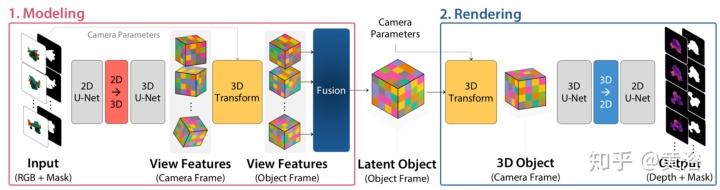
•LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation (2019.12)
当前的6D目标姿态估计方法通常需要为每个目标提供3D模型。这些方法还需要进行额外的训练才能合并新目标。结果,它们难以扩展到大量目标,并且不能直接应用于没见过的目标。
这项工作提出了一个没见过目标的6D姿态估计框架。它设计了端到端神经网络,该网络使用少量目标的参考视图来重建目标的潜在3D表示。用学习的3D表示,网络可以从任意视图渲染目标。使用该神经渲染器,可以根据输入图像直接优化姿势。通过使用大量3D形状训练网络进行重构和渲染,该网络可以很好地推广到没见过的目标。此外,它提出了一个用于没见过的物体姿态估计的数据集-MOPED(Model-free Object Pose Estimation Dataset)。
下图是其流水线结构图:
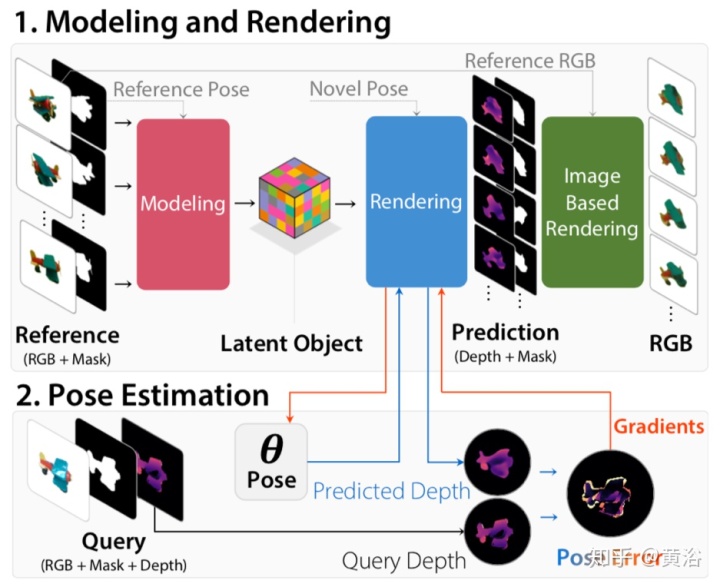
给定一组具有相关联的目标姿态和目标分割掩码的N个参考图像,它试图构建可以用任意相机参数渲染的目标表示。将目标表示为潜在的3D体素网格,可使用标准3D转换直接对其进行操作-自然地可以满足新视图渲染的要求。重建流水线有两个主要组件:1)通过预测每个视图的特征容量并将其融合为单个规范的潜在表示对目标建模; 2)将潜在表示渲染为深度和彩色图像。
建模步骤的灵感来自于空间雕刻(space carving),因为该网络从多个视图中获取观察结果,并利用多视图一致性来构建规范表示。渲染模块获取融合的目标体积,并在给定任意相机参数的情况下对其进行渲染。首先进行深度渲染,然后使用基于图像的渲染方法来生成彩色图像,并通过神经网络保留高频细节。
下图是体系结构的高级概览:1)该建模网络获得图像和掩码,并预测每个输入视图的特征容量;然后,通过融合模块将预测的特征容量融合到单个规范的潜在目标中。 2)给定潜在目标,渲染网络会为任何一个输出相机生成深度图和掩码。
下面是一些模型性能的比较表格:
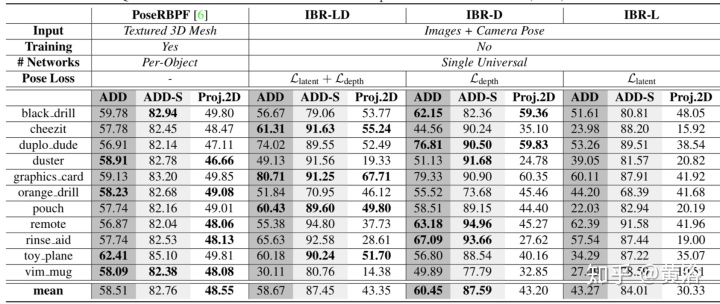
注:Ref[6] X Deng, A Mousavian, Y Xiang, F Xia, T Bretl, and D Fox. “PoseRBPF: A rao-blackwellized particle filter for 6D object pose tracking”. Robotics: Science and Systems (RSS), 2019.
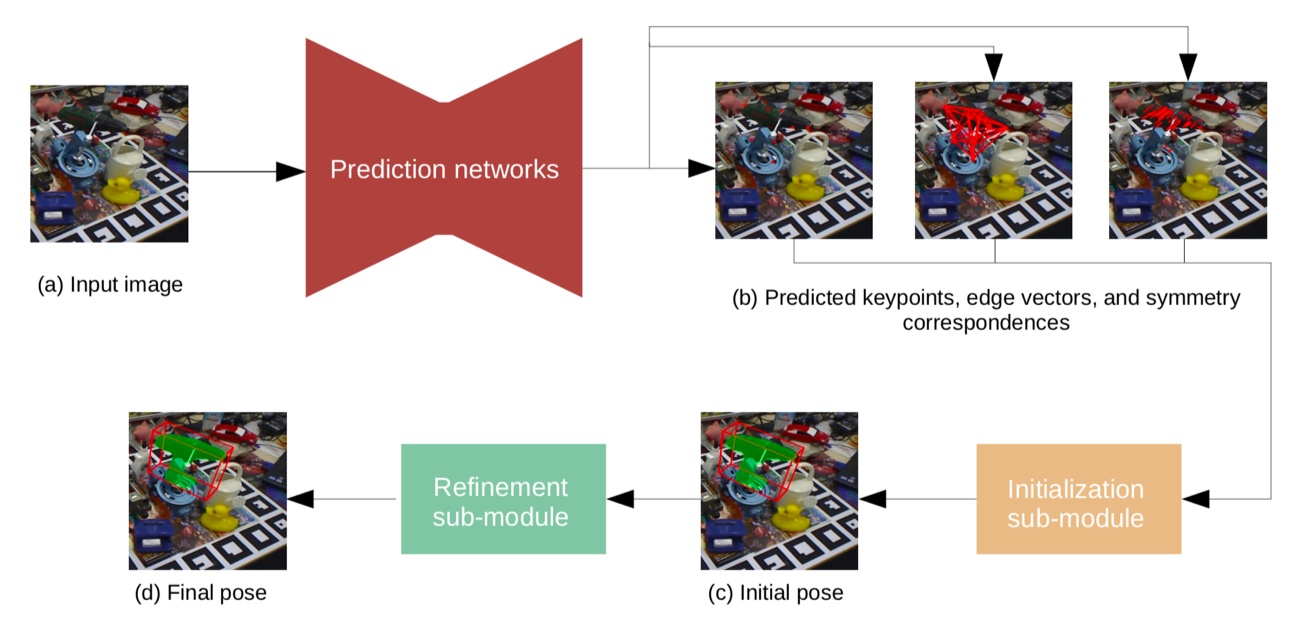
•HybridPose: 6D Object Pose Estimation under Hybrid Representations (2020.1)
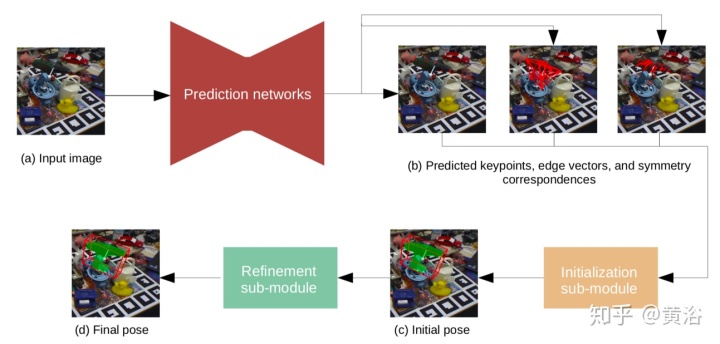
HybridPose,一个6D目标姿态估计方法,利用混合中间表示在输入图像中表达不同的几何信息,包括关键点、边缘向量和对称对应关系。与单一表示相比,当一种类型的预测表示不准确时(例如,遮挡),混合表示允许姿势回归利用更多且多样化的特征。HybridPose利用强大的回归模块来滤除预测的中间表示中的异常值。可以通过相同的简单神经网络预测所有中间表示,而不会牺牲整体性能。与SOA姿势估计方法相比,HybridPose在运行时间上具有可比性,并且准确性更高。HybridPose代码:https://github.com/chensong1995/HybridPose。
如图所示是HybridPose运行的直观图:(a)输入RGB图像;(b)红色标记表示预测的2D关键点;(c)边缘向量由所有关键点之间的完全连接图定义;(d)对称对应关系将目标上的每个2D像素连接到其对称的对应目标。

HybridPose的输入是包含已知类别目标的图像,假设该类目标具有规范的坐标系(即3D点云),在该坐标系下HybridPose输出图像目标的6D相机姿态。HybridPose由预测模块和姿势回归模块组成。HybridPose利用三个预测网络来估计一组关键点、一组关键点之间的边缘以及一组图像像素之间的对称对应关系。
关键点网络采用了现成的预测网络PVNet。边缘网络沿着预定义关键点图预测边缘向量,当关键点在输入的图像比较混乱时,这可以稳定姿势回归。对称网络(FlowNet 2.0的扩展)预测反映基本(部分)反射对称轴的对称对应。姿态回归模块优化目标的姿态适合三个预测网络的输出(如同遵循EPnP框架的P3P求解器)。如下图是其架构图:
下图结果展示遮挡的处理示例:

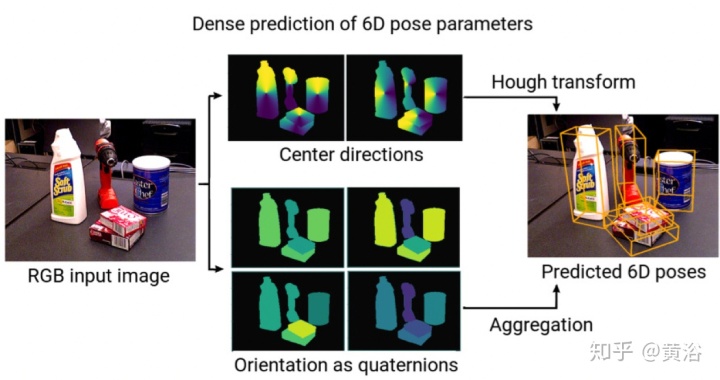
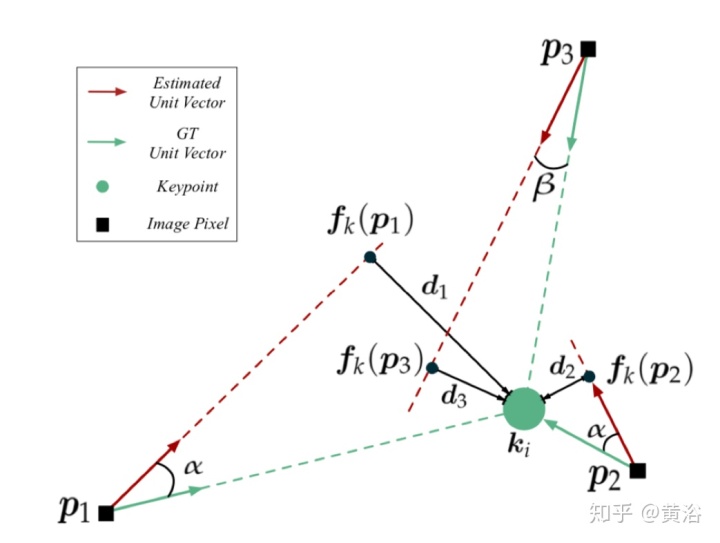
• 6DoF Object Pose Estimation via Differentiable Proxy Voting Loss (2020.2)
由于存在遮挡或缺少纹理,因此从单个图像估计6DOF目标姿势非常具有挑战性。基于矢量场的关键点投票已证明其在解决这些问题上的有效性和优越性。但是,矢量场的直接回归忽略了像素和关键点之间的距离也极大地影响了假设的偏差。换句话说,当像素远离关键点时,方向矢量的小误差可能会产生严重偏离的假设。
本文旨在通过将像素和关键点之间的距离纳入目标函数来减少此类误差。为此,它产生了可微分的代理投票损失(DPVL,differentiable proxy voting loss),该损失模拟了投票程序中的假设选择。利用投票损失,可以端到端的方式训练网络。
下图是DPVL示意图: 假设方向矢量的估计误差相同(例如α),则像素与关键点之间的距离会影响假设与关键点之间的接近度。 DPVL最小化代理假设fk(p⋆)与关键点ki之间的距离d⋆,以此实现关键点投票的准确假设。
下图所示是该系统的流水线图。这项工作着重于获得准确的初始姿态估计。特别是,此方法旨在精确定位和估计目标的朝向和平移而无需任何改进。目标姿态由从目标坐标系到摄像机坐标系的刚性转换表示。由于基于投票的方法已经证明了其对遮挡和视图更改的鲁棒性,因此这里采用基于投票的姿势估计流程。具体地,该方法首先从矢量场对目标关键点的2D位置进行投票,然后通过解决PnP问题来估计6DOF姿势。
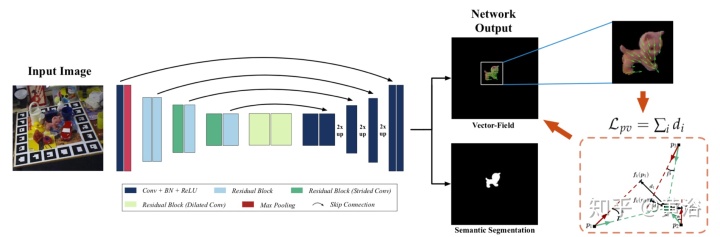
以前工作采用L1-loss(损失函数类型)回归逐像素的矢量场。但是,矢量场中的小误差可能会导致假设的较大偏差误差,因为损失并未考虑像素与关键点之间的距离。因此,通过模拟投票过程中的假设选择,提供了可微分代理投票损失(DPVL)以减少此类错误。此外,得益于DPVL,网络可以更快地收敛。
最后展示的是一些结果例子:


-完-















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









