






Linux下nload的安装:
nload是个很好用的一个工具,功能也很强.只是相对单一,只能查看总的流量,不能像iptraf那样,可针对IP,协议等
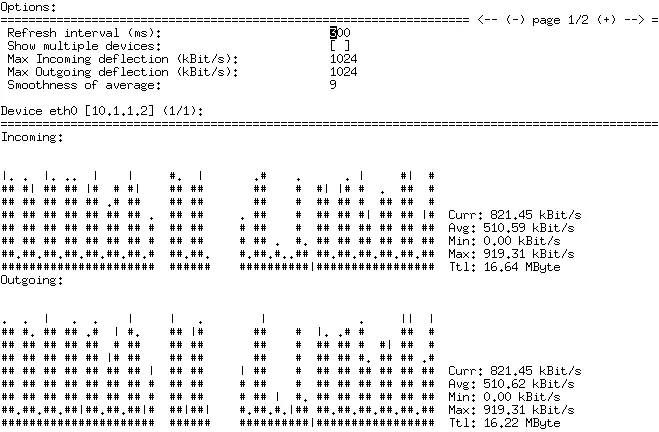
可以实时地监控网卡的流量,分Incoming,Outgoing两部分,也就是流入与流出的流量。同时统计当前,平均,最小,最大,总流量的值,使人看了一目了然,如下图
#wget http://cdnetworks-kr-1.dl.sourceforge.net/project/nload/nload/0.7.2/nload-0.7.2.tar.gz
#tar zxvf nload-0.7.2.tar.gz
#cd nload-0.7.2
#./configure –prefix=/usr/local/nload && make && make install
安装好以后,来看看效果
#/usr/local/nload/bin/nload
Device eth0 [192.168.100.210] (1/13):
===================================================================================
Incoming:
Curr: 31.23 kBit/s
Avg: 95.94 kBit/s
Min: 0.89 Bit/s
Max: 0.54 kBit/s
Ttl: 2.41 GByteOutgoing:
Curr: 41.34 kBit/s
Avg: 82.34 kBit/s
Min: 7.41 kBit/s
Max: 0.30 kBit/s
Ttl: 3.84 GByte
可以看到他可以监控到输出和输入的流量,感觉还不错,呵呵,完全可以用到流量监控报警机制上,那个就是要看你的脚本功底了 哈哈.
=====================================================================
FreeBSD下nload安装及使用:
nload是查看网卡当前流量的工具
freebsd#cd /usr/ports/net/nload
freebsd#make install
安装完成后使用:
freebsd#nload lnc0 //lnc0是网卡名。
不可以长时间查看,会增加CPU负担。














 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









