






学习MySQL也有一阵子,从秦路老师的七周成为数据分析,到《对比EXCEL学习,轻松学习SQL》,再到刷牛客网的SQL题目。总结过SQL要点,也对比EXCLE总结过SQL,但还是觉得不成一体。
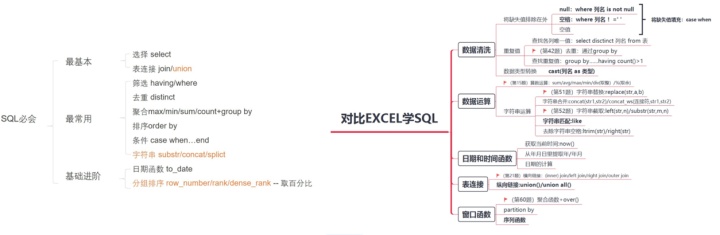
所以我想借此文,将自己现在掌握的MySQL一一呈现,也算给自己个交代。
至今学过的知识点:
- 表相关(创建,更新,删除表,插入值)
- 简单查询(select)
- 复杂查询:子查询,多表查询,聚合函数(group by)的使用
- 表连接(left/right/inner/outer/cross)
- 行转列问题(归根结底case when end的用法)列转行(union)
- SQL中常用高级函数相关的题目【case when end】【字符串相关:substr/concat/split】
- 基础进阶【日期函数】【组内排序:row_number()/rank()/dense_rank()】【取百分比】【窗口函数】 Reference: 无眠:数据分析面试必备——SQL你准备好了吗?
- 运营数据分析:复购率、回购率
- DAU的分析,次日留存、三日留存、七日留存,及留存率
不熟悉的SQL函数
1)取百分比可以用【percentile】
但不知为何我的电脑里不存在percentile,用法记录在此
#想要获取top10%的值?—— percentile 百分位函数
-- 获取income字段的top10%的阈值
select percentile(CAST (salary AS int),0.9)) as income_top10p_threshold from table_1;
-- 获取income字段的10个百分位点
select percentile(CAST (salary AS int),array(0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0)) as income_percentiles
from table_1;
#CAST它常用于string/int/double型的转换。查找前20%的数据,我用以下方法
【解题思路】①用row_rumber()对数据进行降序排名,得到ranking ②ranking<=(select max(ranking) from 表)
#查找前20%数据(拼多多面试题)
用户访问次数表,列名包括用户编号、用户类型、访问量。要求在剔除访问次数前20%的用户后,每类用户的平均访问次数。
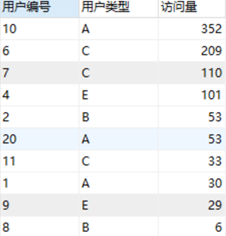
SELECT t.用户类型,avg(t.访问量) from
(SELECT *,row_number() over (ORDER BY 访问量 desc) as ranking from 拼多多访问) t
where t.ranking>(SELECT count(用户编号) from 拼多多访问)*0.2
GROUP BY t.用户类型;2)字符串相关
- substr/concat/split
- concat( A, B...)返回将A和B按顺序连接在一起的字符串,如:concat('foo', 'bar') 返回'foobar'
select concat('www','.iteblog','.com') from
iteblog;
--得到 www.iteblog.com
#变形①--以分隔符连接
SELECT CONCAT_WS(',','GOOD','JOB')
---得到GOOD,JOB
#变形②--同组连接
select dept_no,group_concat(emp_no) as employees from dept_emp
group by dept_no
;
--将表dept_emp中相同dept_no的emp_no连接(from牛客网53题)2. split(str, regex)用于将string类型数据按regex提取,分隔后转换为array。???
-- 以","为分隔符分割字符串,并转化为array
Select split("1,2,3",",")as value_array from table_1;
-- 结合array index,将原始字符串分割为3列
select value_array[0],value_array[1],value_array[2] from
(select split("1,2,3",",")as value_array from table_1 )t3. substr(str,0,len) 截取字符串从0位开始的长度为len个字符。
select substr('abcde',3,2) from
iteblog;
-- 得到cd- 字符串长度/替换
查找字符串'10,好,B' 中逗号','出现的次数cnt(第51题)
#总长度-剔除(,)长度
#剔除(,)用replace
SELECT CHAR_LENGTH('10,好,B')-CHARACTER_LENGTH(replace('10,好,B',',',''))注意:char_length()基于字符计数,length()基于字节计数
SELECT replace('10,好,B',',',''),
CHAR_LENGTH('10,好,B'),
CHARACTER_LENGTH(replace('10,好,B',',','')),
length('10,好,B'),
length(replace('10,好,B',',',''))
以下是各种练习
这部分,是我的错题本,会随刷题不断增加内容~
1)基础过关50题
猴子:图解SQL面试题:经典50题,题目很基础,适合初学练手~
2)牛客网题目
- 复杂查询——【牛客网28题】查找描述信息(film.description)中包含robot的电影对应的分类名称(category.name)以及电影数目(count(film.film_id)),而且还需要该分类包含电影总数量(count(film_category.category_id))>=5部
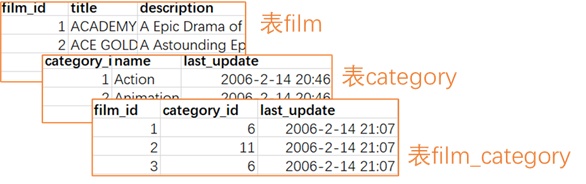
【思路拆解】
Step1:明确最终输出:包含robot的电影【分类名称】以及对应分类的电影【数目】
Step2:明确限制条件
①film.description包含robot(like '%robot%')
②查找出category_id,满足(count(film_category.category_id))>=5
【解答】
SELECT c.`name`,count(f.film_id) from film f
LEFT JOIN film_category fc
on f.film_id=fc.film_id
LEFT JOIN category c
on c.category_id=fc.category_id
where f.description like '%robot%'
and fc.category_id=(
select category_id from film_category
group by category_id
having count(film_id)>=5);- 考虑重复值1——【牛客网8题】找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
【已知】
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
【思路一】用distinct去重
select distinct(salary) from salaries
where to_date='9999-01-01'
order by salary desc;
【思路二】用group by
select salary from salaries
where to_date='9999-01-01'
group by salary
order by salary desc;考虑重复值2——【牛客网第14题】从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。注意对于重复的emp_no进行忽略(即emp_no重复的title不计算,title对应的数目t不增加)。
【已知】
CREATE TABLE IF NOT EXISTS `titles` (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);
【求解】
select title,count(distinct emp_no) as t from titles
group by title
having count(distinct emp_no)>=2
;- 多思维解题——【牛客网第17题】获取当前(to_date='9999-01-01')薪水第二多的员工的emp_no以及其对应的薪水
【已知】
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
【思路1】用limit函数来限制
select emp_no,salary from salaries
order by salary desc
limit 1,1
【思路3】第二大就是比最大小的最大
select emp_no,max(salary)
from salaries
where salary < (select max(salary) from salaries)
【思路2】用窗口函数排序
select t.emp_no,t.salary from
(select *,row_number() over (order by salary desc) as ranking from salaries) t
where t.ranking=2
;3)连续签到天数
求解连续签到问题的关键在于找出数据间的逻辑关系,连续签到意味着某两列数据之差是一致的。
腾讯经典面试题,百度也考过☞接受挑战
数据分析SQL面试9套题里第8题也出现了连续签到,一个表记录了某论坛会员的发贴情况,存储了user_id ,发贴时间post_time和内容content。找出连续发贴三次及以上的会员。
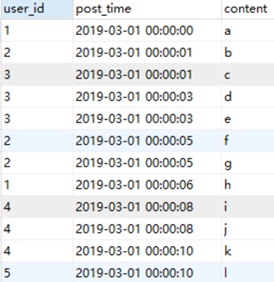
思路:①每个用户按照签到先后排序 ②所有用户按照签到先后排序 ③如果连续签到,则排序②与排序①的差值相同
SELECT t.user_id from
(SELECT user_id,post_time,
ROW_number() over (PARTITION by user_id ORDER BY post_time) as row1,
row_number() over (order by post_time) as row2,
row_number() over (order by post_time)-ROW_number() over (PARTITION by user_id ORDER BY post_time) as diff
from tablename)t
GROUP BY t.user_id,t.diff
having count(t.user_id)>=3
;4)数据分析SQL面试题9套汇总
参考:数据蛙datafrog:数据分析SQL面试题目9套汇总,此外在B站关注同名账号,也有不少资料的~
- 字符串连接
- 留存率
- 行列转换
- 列转行
- 窗口函数应用(求累计和)
- 查询登录次数
- 红包领取活动
- 连续签到
- 【题目】求用户号对应的前两个不同场景(场景重复的话,选重复场景的第一个访问时间,场景不足两个的输出为止)
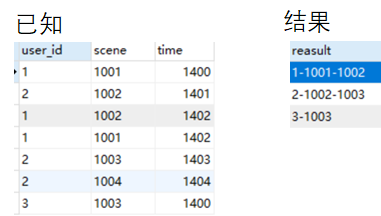
该题目与牛客网第53题类似,涉及字符串连接的知识:可以用group_concat(列名 SEPARATOR '分隔符') 解决。解题思路 ①排序 ②条件查询 ③concat函数连接
SELECT concat(t.user_id,'-',GROUP_CONCAT(DISTINCT t.scene SEPARATOR '-') ) as reasult FROM
(SELECT *,
row_number() over (PARTITION by user_id order by time) as ranking
from scene) t
where t.ranking<3
GROUP BY t.user_id
;
- 【题目】求累计和(窗口函数之聚合函数,如sum. avg, count, max, min等的应用)
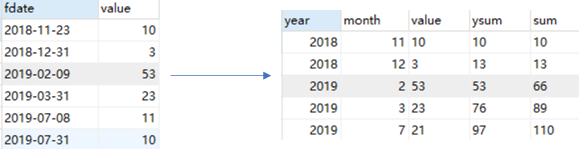
SELECT t.year,t.month,t.value,sum(value) over (PARTITION by year order by t.month) as ysum,
sum(value) over (order by t.ranking) as sum
FROM
(SELECT year(fdate) as year,
month(fdate) as month,
row_number() over (order by fdate) as ranking,
sum(value) as value
from sales
group by year(fdate),month(fdate))t;【题目】生成登录表,求出最近一次登录时间以及每个用户登录总次数(当天登录多次记录1次)
注意时间函数的用法。①文本转换成时间 DATE_FORMAT(文本,'%Y-%m-%d %H:%i:%s') ②时间的提取,datetime转化成date格式,直接用date()
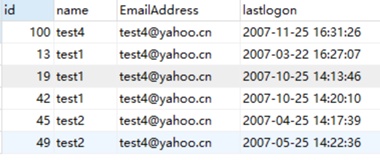
【生成表】
create table userlog
(
id int ,
name varchar(10),
EmailAddress varchar(50),
lastlogon varchar(50)
);
insert into userlog values(100,'test4','test4@yahoo.cn','2007-11-25 16:31:26');
insert into userlog values(13,'test1','test4@yahoo.cn','2007-3-22 16:27:07');
insert into userlog values(19,'test1','test4@yahoo.cn','2007-10-25 14:13:46');
insert into userlog values(42,'test1','test4@yahoo.cn','2007-10-25 14:20:10');
insert into userlog values(45,'test2','test4@yahoo.cn','2007-4-25 14:17:39');
insert into userlog values(49,'test2','test4@yahoo.cn','2007-5-25 14:22:36');
UPDATE userlog set lastlogon=DATE_FORMAT(lastlogon,'%Y-%m-%d %H:%i:%s');
SELECT * from userlog;
【查询登录次数】
SELECT name,max(lastlogon) as 最近一次登录时间,
count(DISTINCT date(lastlogon)) as 登录次数 from userlog
group by name;【题目】红包领取
两张表如下
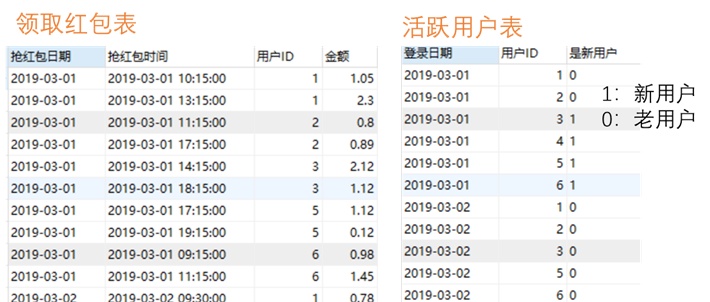
1、计算2019年6月1日至今,每日DAU(活跃用户量,即有登陆的用户)
2、计算20190601至今,每日领取红包的新用户数,老用户数,及人均领取金额,人均领取次数(注意领取人数中有未登录用户)
3、计算2019年3月,每个月按领红包取天数为1、2、3……30、31天区分,计算取每个月领取红包的用户数,人均领取金额,人均领取次数
4、计算2019年3月,每个月领过红包用户和未领红包用户的数量
5、计算2019年3月至今,每个月活跃用户的注册日期,2019年3月1日前注册的用户日期填空即可
6、计算2019年3月至今,每日的用户次日留存率,领取红包用户的次日留存,未领取红包用户的次日留存率
7、计算2019年6月1日至今,每日新用户领取得第一个红包的金额
8、计算2019年3月1日至今,每个新用户领取的第一个红包和第二个红包的时间差(只计算注册当日有领取红包的用户,注册当日及以后的DAU表中新用户为1的用户)
【1】每日DUA人数
SELECT `登录日期`,count(`用户ID`) as DAU from 活跃用户表
where `登录日期`>20190531
GROUP BY `登录日期`;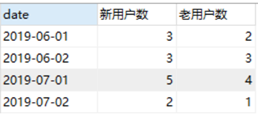
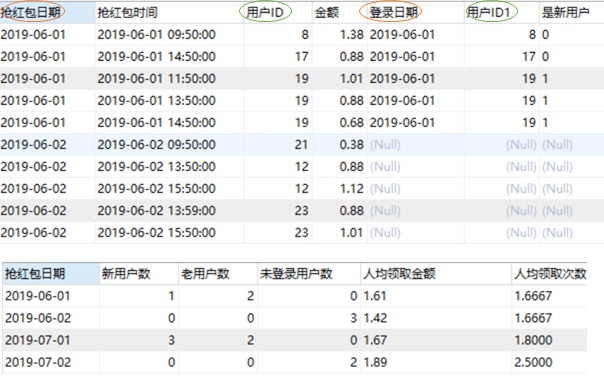
【2】每日领取红包人员构成(表连接的时候不仅要id连接,还要时间连接)
SELECT p.`抢红包日期`,
count(DISTINCT case when u.`是新用户`='1' then p.`用户ID` else null end) as 新用户数,
count(DISTINCT case when u.`是新用户`='0' then p.`用户ID` else null end) as 老用户数,
count(DISTINCT case when u.`是新用户`is null then p.`用户ID` else null end) as 未登录用户数,
round(sum(p.`金额`)/count(DISTINCT p.`用户ID`),2) as 人均领取金额,
count(p.`用户ID`)/count(DISTINCT p.`用户ID`) as 人均领取次数
from `领取红包表` p
LEFT JOIN `活跃用户表` u
on p.`用户ID`=u.`用户ID` and p.`抢红包日期`=u.`登录日期`
where p.`抢红包日期`>20190531
GROUP BY p.`抢红包日期`
;
【3】每月领取红包状况~这个很简单
SELECT DATE_FORMAT(`抢红包日期`,'%Y-%m') as 月份,
count(DISTINCT `抢红包日期`) as 领取天数,
count(DISTINCT `用户ID`) as 每个月领取红包人数,
sum(`金额`)/count(DISTINCT `用户ID`) as 人均领取金额,
count(`用户ID`)/count(DISTINCT `用户ID`) as 人均领取次数
from `领取红包表`
GROUP BY DATE_FORMAT(`抢红包日期`,'%Y-%m');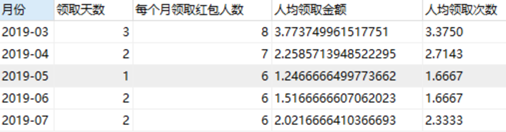
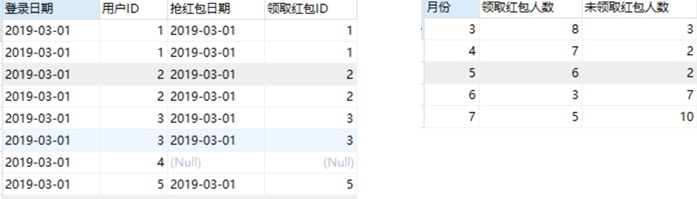
【4】登录用户中,每月领取红包人数 和 未领取红包人数
SELECT DATE_FORMAT(u.`登录日期`,'%Y-%m') as 月份,
count(DISTINCT case when p.`用户ID` is not null then u.`用户ID` else null end)as 领红包人数,
count(DISTINCT case when p.`用户ID` is null then u.`用户ID` else null end)as 未领红包人数
from `活跃用户表` u
LEFT JOIN `领取红包表` p
on u.`用户ID`=p.`用户ID` and u.`登录日期`=p.`抢红包日期`
group by DATE_FORMAT(u.`登录日期`,'%Y-%m')
;
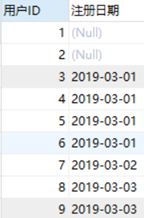
【5】各用户首次登录的日期
SELECT t1.`用户ID`,t2.`登录日期` as 注册日期 FROM
(SELECT `用户ID` from `活跃用户表`
group by `用户ID`)t1
LEFT JOIN
(SELECT * from `活跃用户表`
where `是新用户`=1)t2
on t1.`用户ID`=t2.`用户ID`
;
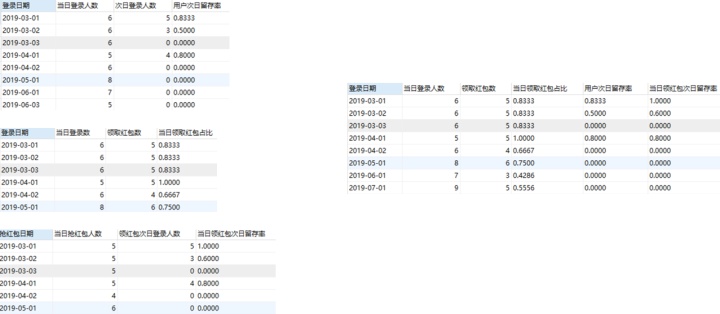
【6】解题思路是将要的总结果拆分,再将一个个分结果连接。
①求出登录用户次日留存率,活跃用户表与活跃用户表连接
②当日领取红包占比,活跃用户表与领取红包表连接
③领取红包次日留存,领取红包表与活跃用户表连接
以上三个连接均为左连接
【6】每日登录用户的次日留存、领取红包用户的次日留存、未领取红包用户的次日留存
SELECT t1.`登录日期`,t1.`当日登录人数`,t2.`领取红包数`,t2.`当日领取红包占比`,t1.`用户次日留存率`,t3.`当日领红包次日留存率` from
(SELECT a.`登录日期`,
count(DISTINCT a.`用户ID`) 当日登录人数,
count(case when DATE_ADD(a.`登录日期`,INTERVAL 1 day)=b.`登录日期` then b.`用户ID` else null end) as 次日登录人数,
count(case when DATE_ADD(a.`登录日期`,INTERVAL 1 day)=b.`登录日期` then b.`用户ID` else null end)/count(DISTINCT a.`用户ID`) as 用户次日留存率
from `活跃用户表` a
LEFT JOIN `活跃用户表` b
on a.`用户ID`=b.`用户ID`
GROUP BY a.`登录日期`) t1
JOIN
(SELECT u.`登录日期`,count(DISTINCT u.`用户ID`) as 当日登录数,
count(DISTINCT p.`用户ID`)as 领取红包数,
count(DISTINCT p.`用户ID`)/count(DISTINCT u.`用户ID`) as 当日领取红包占比
from `活跃用户表` u
LEFT JOIN `领取红包表` p
on u.`用户ID`=p.`用户ID` and u.`登录日期`=p.`抢红包日期`
group by u.`登录日期`)t2
on t1.`登录日期`=t2.`登录日期`
JOIN
(SELECT p1.`抢红包日期`,
count(DISTINCT p1.`用户ID`) as 当日抢红包人数,
count(DISTINCT case when DATE_ADD(p1.`抢红包日期`,INTERVAL 1 day)=u1.`登录日期` then u1.`用户ID` else null end) as 领红包次日登录人数,
count(DISTINCT case when DATE_ADD(p1.`抢红包日期`,INTERVAL 1 day)=u1.`登录日期` then u1.`用户ID` else null end)/count(DISTINCT p1.`用户ID`) as 当日领红包次日留存率
from `领取红包表` p1
LEFT JOIN `活跃用户表` u1
on p1.`用户ID`=u1.`用户ID`
group by p1.`抢红包日期`)t3
on t2.`登录日期`=t3.抢红包日期
;
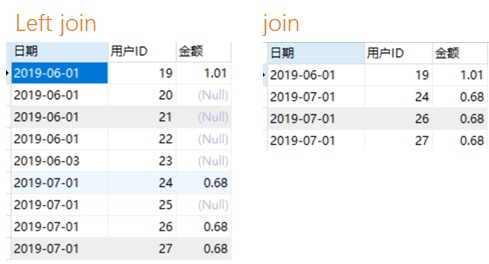
【7】思路:①筛选出每个用户首次抢红包的时间 ②筛选出首次抢的红包金额 ③活跃用户表与筛选出的表连接,求出结果
SELECT t1.`登录日期` as 日期,t1.`用户ID`,t2.`金额` FROM
(SELECT `登录日期`,用户ID from `活跃用户表`
where `登录日期`>=20190601 and `是新用户`=1)t1
LEFT JOIN
(SELECT t.`用户ID`,p.`抢红包日期`,p.`金额` from
(SELECT `用户ID`,min(`抢红包时间`) as 第一次领取时间 from `领取红包表`
GROUP BY `用户ID`)t
JOIN `领取红包表` p
on t.`用户ID`=p.`用户ID` and t.`第一次领取时间`=p.`抢红包时间`) t2
on t1.`用户ID`=t2.`用户ID` and t1.`登录日期`=t2.`抢红包日期`
;
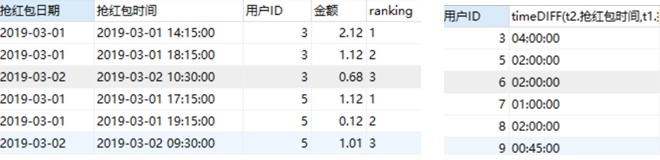
【8】思路:①求出新用户首次抢红包时间,活跃用户表left join领取红包表,使用筛选条件,并对连接表以领取红包userid进行分组,找出组内最早时间,即为首次领取红包时间。②将表一与领取红包表再次连接,并筛选出抢红包时间一致的数据,用TIMESTAMPDIFF求出时间间隔
SELECT t1.`用户ID`,t1.`首次抢红包时间`,
min(TIMESTAMPDIFF(minute,t1.`首次抢红包时间`,t2.`抢红包时间`)) as 抢红包时间间隔
FROM
(SELECT p.`用户ID`,min(p.`抢红包时间`) as 首次抢红包时间 from `活跃用户表` u
LEFT JOIN `领取红包表` p
on u.`用户ID`=p.`用户ID` and u.`登录日期`=p.`抢红包日期`
where u.`是新用户`='1'
GROUP BY p.`用户ID`) t1
LEFT JOIN `领取红包表` t2
ON t1.`用户ID`=t2.`用户ID`
where t1.`首次抢红包时间`!=t2.`抢红包时间`
group by t1.`用户ID`;
#窗口函数来排序求解
SELECT t1.用户ID,timeDIFF(t2.抢红包时间,t1.抢红包时间) from
(SELECT * FROM
(SELECT `抢红包时间`,`用户ID`,row_number() over (PARTITION by `用户ID` ORDER BY `抢红包时间`) as ranking from `领取红包表`
WHERE `用户ID` in
(SELECT `用户ID` from `活跃用户表`
where `是新用户`=1)) t
where t.ranking=1) t1
LEFT JOIN
(SELECT * FROM
(SELECT `抢红包时间`,`用户ID`,row_number() over (PARTITION by `用户ID` ORDER BY `抢红包时间`) as ranking from `领取红包表`
WHERE `用户ID` in
(SELECT `用户ID` from `活跃用户表`
where `是新用户`=1)) t
where t.ranking=2) t2
on t1.用户ID=t2.用户ID
;
这个内容实在是太多了,慢慢刷~数据分析真题日刷 | 目录索引_是圣洁呀✨-CSDN博客
(~ ̄▽ ̄)~















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









