






-点击蓝字关注我们
 人生苦短,我用Python
前天,本人在爬取某网站时,第一次遇到IP被封的情况,等了几个小时之后,还是不行。最后,迫于无奈,还是请出了大招,使用代理IP。今天,闲来无事,本人爬取了快代理网站上 5 万多条免费高匿名代理IP。
首先,我们进入网站免费代理页面,可以看到该网站目前共有免费代理IP 3482 页。免费代理IP首页的url地址为:https://www.kuaidaili.com/free/inha/。
人生苦短,我用Python
前天,本人在爬取某网站时,第一次遇到IP被封的情况,等了几个小时之后,还是不行。最后,迫于无奈,还是请出了大招,使用代理IP。今天,闲来无事,本人爬取了快代理网站上 5 万多条免费高匿名代理IP。
首先,我们进入网站免费代理页面,可以看到该网站目前共有免费代理IP 3482 页。免费代理IP首页的url地址为:https://www.kuaidaili.com/free/inha/。
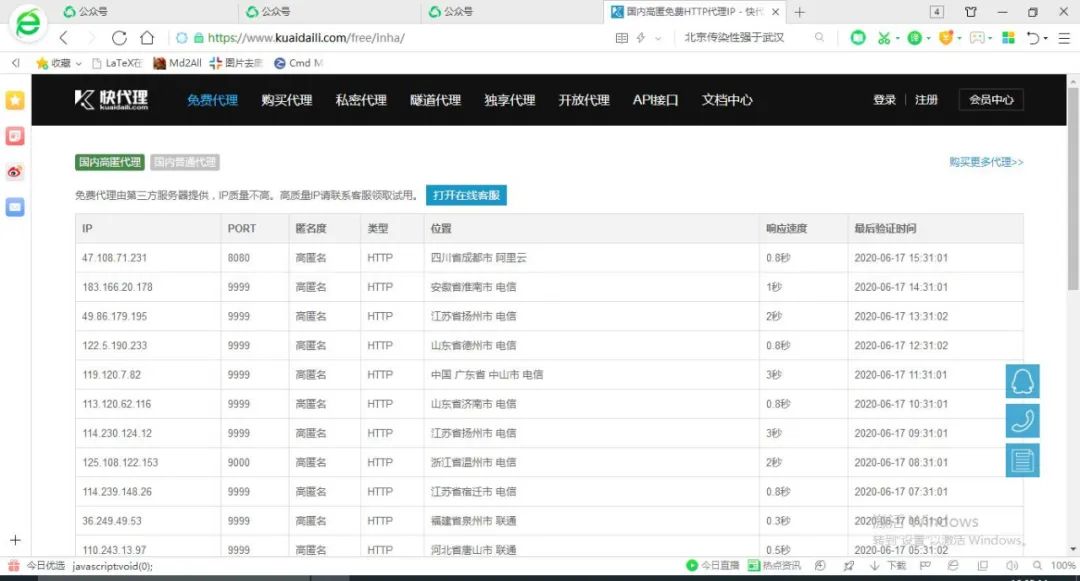 你可能会疑惑,我们的目标是爬取三千多页的代理IP信息,上面只提到了首页的url地址,如何知道其余页面的url地址呢?这时,不用着急,我们再点开第二页,可以看到第二页的url地址为https://www.kuaidaili.com/free/inha/2/,仔细观察就会发现,该url地址结尾有一个数字 2 ,你可能会想,第三页会不会就是3呢?事实上,正是如此,后面的以此类推……
你可能会疑惑,我们的目标是爬取三千多页的代理IP信息,上面只提到了首页的url地址,如何知道其余页面的url地址呢?这时,不用着急,我们再点开第二页,可以看到第二页的url地址为https://www.kuaidaili.com/free/inha/2/,仔细观察就会发现,该url地址结尾有一个数字 2 ,你可能会想,第三页会不会就是3呢?事实上,正是如此,后面的以此类推……
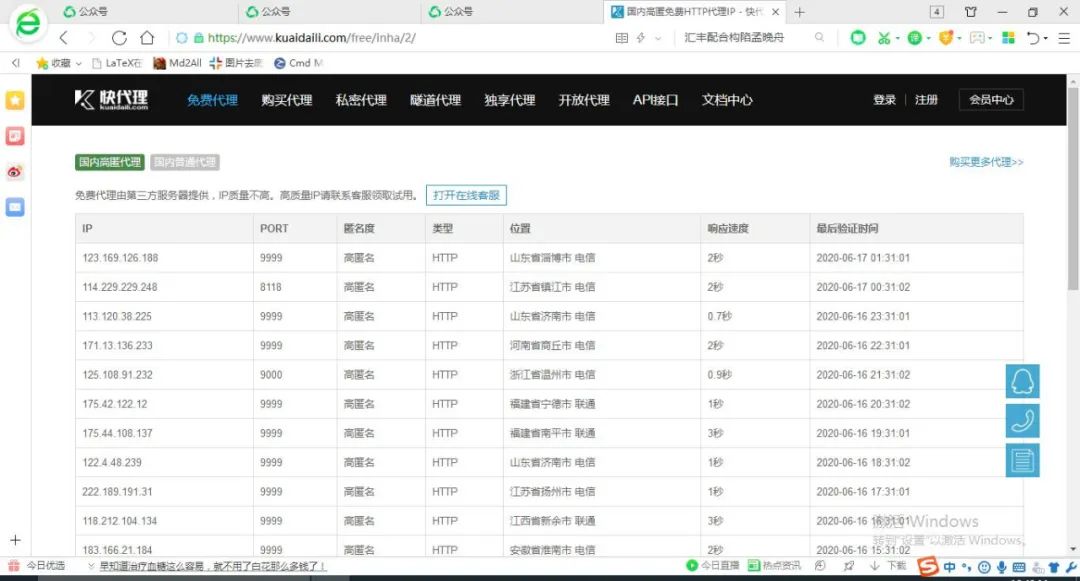 这样,从第 2 页至最后一页的url地址所符合的规律我们已经找到了。其实,这种情况是很常见的,而且,首页url地址也可以是这样的,即url地址https://www.kuaidaili.com/free/inha/1/和https://www.kuaidaili.com/free/inha/对应的是同一页面。知道了这一点,我们就可以使用format()方法轻松写出每一页的url地址,代码如下:
这样,从第 2 页至最后一页的url地址所符合的规律我们已经找到了。其实,这种情况是很常见的,而且,首页url地址也可以是这样的,即url地址https://www.kuaidaili.com/free/inha/1/和https://www.kuaidaili.com/free/inha/对应的是同一页面。知道了这一点,我们就可以使用format()方法轻松写出每一页的url地址,代码如下:
1url = 'https://www.kuaidaili.com/free/inha/{}/'.format(str(i))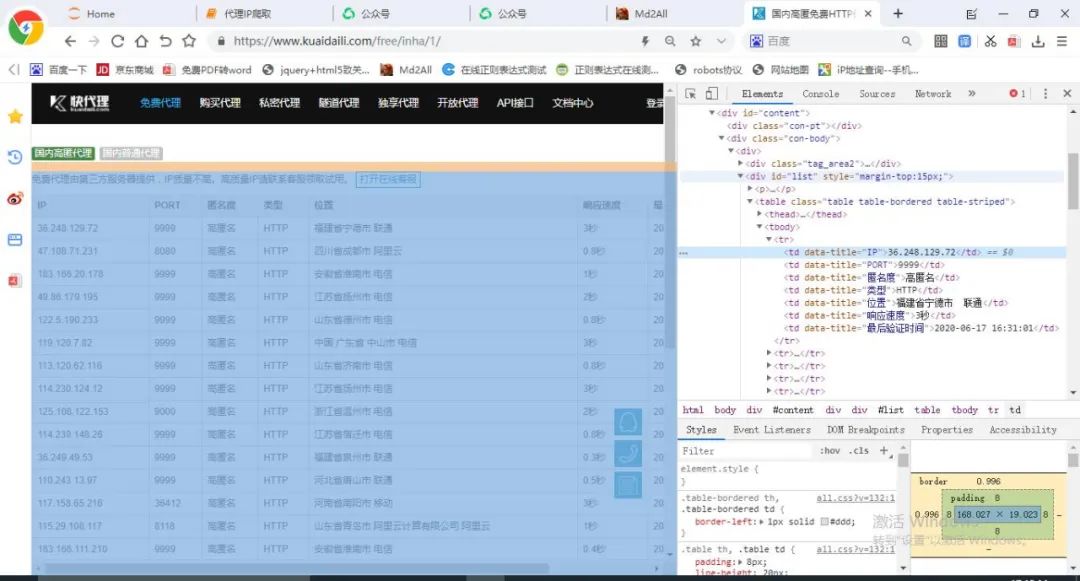 通过观察发现,可以使用正则表达式re模块的findall()方法匹配相关信息,下面我们开始编写程序。
首先,我们需要导入所需的库,代码如下:
通过观察发现,可以使用正则表达式re模块的findall()方法匹配相关信息,下面我们开始编写程序。
首先,我们需要导入所需的库,代码如下:
1# 导入相关模块库2import requests3import re4import os5import time 1def get_ipinfo(url): 2 '''定义一个函数,用于获取单个页面的IP代理信息''' 3 r = requests.get(url, headers={'user-agent':'Mozilla/5.0'}) # 获取网页内容 4 html = r.text # 获取http响应内容的字符串形式 5 6 # 利用正则表达式匹配IP、PORT、匿名度、类型、位置、响应速度、最后验证时间信息 7 ip = re.findall('((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))', html) # 匹配IP信息 8 port = re.findall('(\d+)', html) # 匹配端口号信息 9 anonymity = re.findall('([\u4e00-\u9fa5]+)', html) # 匹配匿名度信息10 genre = re.findall('(.+)', html) # 匹配类型信息11 position = re.findall('([\u4e00-\u9fa5 ]+)', html) # 匹配位置信息12 speed = re.findall('(.+)', html) # 匹配响应速度信息13 time = re.findall('(.+)', html) # 匹配验证时间信息1415 ipinfo = zip(ip, port, anonymity, genre, position, speed, time) # 将本页面匹配信息压缩,写入csv文件16 return ipinfo 1def write_ipinfo(ipinfo, page): 2 '''定义一个函数,将IP代理信息写入到指定的csv文件中''' 3 path = 'C:\\Users\\Lenovo\\Desktop\\IP代理' # 待写入文件存储目录 4 if not os.path.exists(path): # 判断桌面是否有名称为“IP代理”的文件夹,如果没有,就创建它 5 os.mkdir(path) 6 7 # 将匹配信息写入csv文件 8 with open(path + '//代理IP.csv', 'a' ,newline='') as f: 9 writer = csv.writer(f)10 if page == 1:11 writer.writerow(['IP', 'PORT', '匿名度', '类型', '位置', '响应速度', '最后验证时间']) # 写入表头信息12 writer.writerows(ipinfo) # 写入单个页面匹配信息1if __name__ == '__main__':2 for page in range(3482):3 url = 'https://www.kuaidaili.com/free/inha/{}/'.format(str(page+1))4 ipinfo = get_ipinfo(url)5 write_ipinfo(ipinfo, page+1)6 time.sleep(1)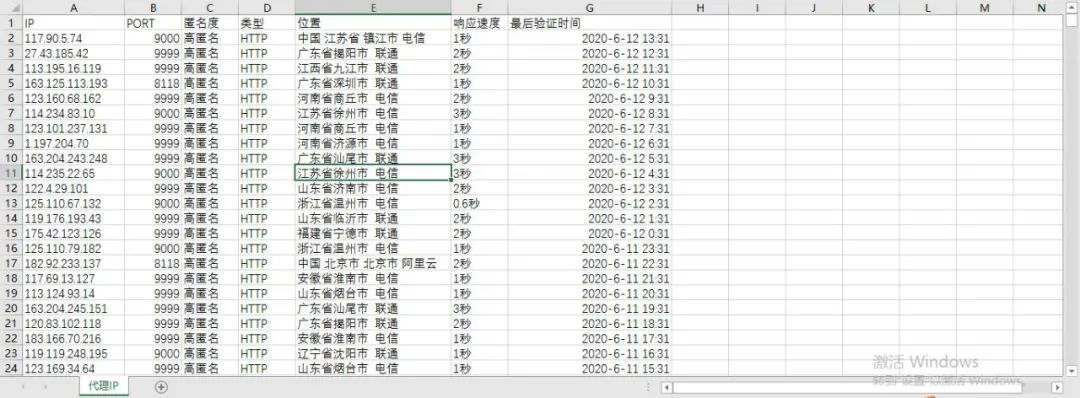 好了,以上就是本期内容,谢谢您的阅读!
觉得不错?支持一下呗!
往期推荐:
Python抓取2020校友会中国工业大学排名
Python抓取守望先锋所有英雄图片
Python爬取网络图片详解
好了,以上就是本期内容,谢谢您的阅读!
觉得不错?支持一下呗!
往期推荐:
Python抓取2020校友会中国工业大学排名
Python抓取守望先锋所有英雄图片
Python爬取网络图片详解

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









