





原标题:【Python连载】那些必须掌握的Python数据类型
经过近几年的发展,Python已成为了数据科学和机器学习的首选语言,许多人也因此开始走上自学python之路。从今天开始,本公众号将陆续分享Python的基础操作,希望能够给予开始入门python的小白一点帮助。话不多说,那么今天先给大家分享一下python中的常用类型及其应用。

1.字符串
字符串是 Python 中最常用的数据类型。
1.1 创建字符串
我们可以使用引号 ' 或 " 来创建字符串。
s1 = 'haha1'
s2 = "haha2"
print(s1) # haha1
print(s2) # haha21.2 字符串截取与拼接
通过方括号的形式来截取字符串
s1 = 'Hello World!'
s2 = "abcd dcba"
print ("s1[0]: ", s1[0]) # 结果为: s1[0]: H
print ("s2[0:5]: ", s2[0:5]) # 结果为: s2[0:5]: abcd
除此之外,还可以将截取字符串的一部分与其他字段拼接
s1 = 'Hello World!'
s2 = s1[0:6] + 'ABC'
print(s2) # Hello ABC1.3 转义字符
在需要在字符中使用特殊字符时,python用反斜杠''转义字符
# 常用的转义字符有:n表示换行;t表示横向制表符;表示反斜杆符号
s1 = 'abcndef'
print(s1)
# abc
# def
s2 = 'abctdef'
print(s2)
# abc def
s3 = 'abcdef'
print(s3)
# abcdef1.4 字符串运算符
具体字符串运算符如下表所示
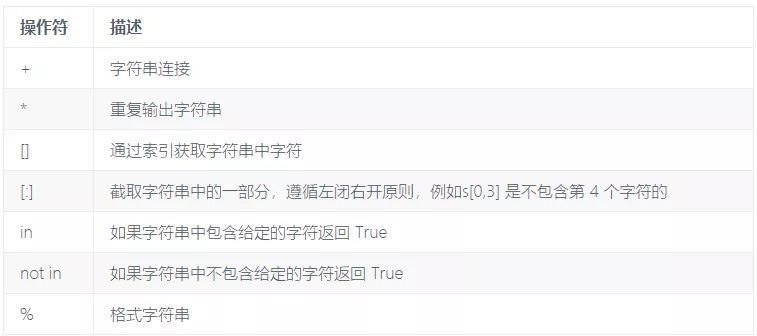
下面举栗说明
s1 = 'I am a'
s2 = ' handsome boy!'
s3 = s1 + s2
print(s3) # I am a handsome boy!
print(s3*2) # I am a handsome boy!I am a handsome boy!
print(s3[2]) # a
print(s3[16:19]) # boy
print('c' in s3) # False
print('c' not in s3) # True
print('%s abc'%11) #11 abc1.5 字符串的常用内置函数
在python中,可以通过字符串的内置函数来快速实现某些功能。
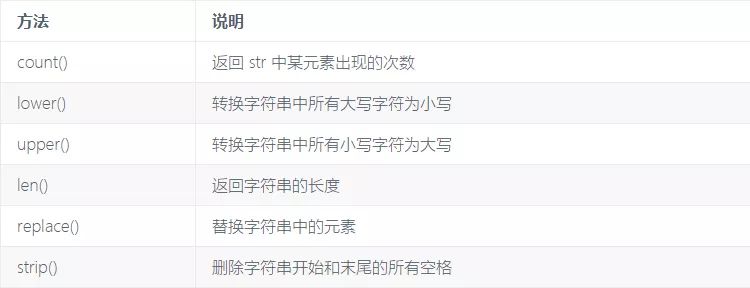
具体操作如下
s = 'abc 123 abc 456'
print(s.count('abc')) #2
print(s.upper) #ABC 123 ABC 456
print(len(s)) #15
print(s.replace('abc','ok')) #ok 123 ok 456
s2 = ' AA11 '
print(s2.lower) # aa11
print(s2.strip) # AA112.元组
元组是一个固定长度且不可改变的Python序列对象。
2.1 创建元组
可以通过以下方式来创建元组
tu=(1)
tu2=(1,)
tu3=(1,2,3,4)
tu4=1,2,3,4
type(tu4)
# 输出结果为:tuple
用tuple可以将任意序列或迭代器转换成元组
tup = tuple('string')
tup
# 输出结果为:('s', 't', 'r', 'i', 'n', 'g')2.2 访问元组元素
元组可以使用下标索引来访问元组中的值
t1 = ('abc','123','456',111)
print(t1[0]) # abc
print(t1[1:3]) # ('123', '456')2.3 修改元组
元组是不可变的对象,但如果元组中的某个对象是可变的,比如列表,则可以对这个对象进行修改
tup = tuple(['foo', [1, 2], True])
tup[1].append(3)
tup
# 输出结果为:('foo', [1, 2, 3], True)
还可以使用加法和乘法串联
tup1 = (4, None, 'foo') + (6, 0) + ('bar',)
tup2 = ('foo', 'bar') * 5
tup1,tup2
# 输出结果为:
((4, None, 'foo', 6, 0, 'bar'),
('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar'))2.4 元组拆分与替换
如果你想将元组赋值给类似元组的变量,Python会试图拆分等号右边的值
tup = (4, 5, 6)
a, b, c = tup
a,b,c
# 输出结果为:(4, 5, 6)
可以进行简单的元组替换
a,b = 1,2
b,a = a,b
a,b
# 输出结果为:(2, 1)
目前Python还支持更高级的元组拆分功能,允许从元组的开头“摘取”几个元素。
#它使用了特殊的语法*rest,这也用在函数签名中以抓取任意长度列表的位置参数
values = 1, 2, 3, 4, 5
a,b,*rest = values
a,b,rest
#rest的部分是想要舍弃的部分,rest的名字不重要。作为惯用写法,许多Python程序员会将不需要的变量使用下划线,即*_
# 输出结果为:(1, 2, [3, 4, 5])2.5 元组的内置函数
可以使用count来统计某个值的出现频率
a = (1, 2, 2, 2, 3, 4, 2)
a.count(2)
# 输出结果为:4
元组还可以通过len来查看元素个数
print(len(a)) # 73.列表
与元组对比,列表属于可变的数据类型,它的长度和内容都可变。因此列表可以执行添加、删除。
3.1 创建列表
我们可以通过以下方式来创建列表,列表里的元素可以是不同数据类型的
li = [1,2,3,4]
li2 = ['a','b','c','d']
li3 = [1,2,'a','b']3.2 添加元素
可以通过append方法在列表末尾添加元素
a_list = [2, 3, 7, None]
a_list.append('dwarf')#append在列表末尾添加元素
a_list
# 输出结果为:[2, 3, 7, None, 'dwarf']
使用extend方法可以追加多个元素
x = [4, None, 'foo']
x.extend([7, 8, (2, 3)])
x
# 输出结果为:[4, None, 'foo', 7, 8, (2, 3)]3.3 插入元素
通过insert方法向列表的特定位置插入元素
x.insert(2,'abc')
x # [4, None, 'abc', 'foo', 7, 8, (2, 3)]3.4 删除元素
使用pop移除并返回指定位置的元素
x.pop(2)
# 输出结果为:'abc'
我们还可以通过remove来删除列表元素
x.append('foo')#在末尾加上'red'。这样就有两个'foo'值
# 此时的x为:[4, None, 'foo', 7, 8, (2, 3), 'foo']
x.remove('foo')#remove会先寻找第一个值并除去
x
# 输出结果为:[4, None, 7, 8, (2, 3), 'foo']3.5 切片、拼接、遍历
切片可以选取大多数序列类型的一部分,切片的基本形式是在方括号中使用。切片的起始元素是包括的,不包含结束元素。
seq = [7, 2, 3, 7, 5, 6, 0, 1]
seq[1:5],seq[:5] # start或stop都可以被省略,省略之后,分别默认序列的开头和结尾
# 输出结果为:([2, 3, 7, 5], [7, 2, 3, 7, 5])
a = [1,2,3]
a = a + [6,8,7] # 进行拼接操作
print(a) # [1, 2, 3, 6, 8, 7]
我们可以通过以下方式来遍历列表元素
#遍历
lists = ["m1", 1900, "m2", 2000]
#1.使用iter
for val in iter(lists):
print(val)
#2.enumerate遍历方法
for i, val in enumerate(lists):
print(i, val)
#3.索引遍历
for index in range(len(lists)):
print(lists[index])4.字典
字典是另一种可变容器模型,且可存储任意类型对象。字典使用花括号{}包括,键和值之间用冒号':'分割,每对键-值用逗号','分割。键必须唯一,即一个键不能对应多个值,不过多个键可以指向一个值。
4.1 创建字典
可以通过以下方法创建字典
empty_dict = {} # 创建一个空字典
d1 = {'a' : 'some value', 'b' : [1, 2, 3, 4]}
d14.2 访问字典元素
把相应的键放入到方括号中即可访问字典元素
print(d1['a']) # 'some value'
但是要注意,如果用字典里没有的键访问数据时,会输出错误。因此我们可以使用get方法来获取字典元素,当访问不存在的键时,不会出现报错。
print(d1.get('a')) # some value
print(d1.get('h','该键不存在')) # 该键不存在4.3 修改字典
添加字典元素,或者修改原字典键对应的值的方法如下
d1['c'] = [6,8,9] # 添加元素
d1['a'] = 'haha' # 更新a
d1
# 结果:{'a': 'haha', 'b': [1, 2, 3, 4], 'c': [6, 8, 9]}
同样,我们也可以使用update方法来实现字典元素的添加和修改
d1.update({'b' : 'foo', 'c' : 12, 'd':'yes'}) # 原d1:{'a': 'haha', 'b': [1, 2, 3, 4], 'c': [6, 8, 9]}
d1 # {'a': 'haha', 'b': 'foo', 'c': 12, 'd': 'yes'}4.4 删除字典元素
可以使用pop或del关键字来删除值
d1[5] = 'some value'
print(d1) # {'a': 'haha', 'b': [1, 2, 3, 4], 'c': [6, 8, 9], 5: 'some value'}
d1['dummy'] = 'another value'
print(d1) # {'a': 'haha', 'b': [1, 2, 3, 4], 'c': [6, 8, 9], 5: 'some value', 'dummy': 'another value'}
del d1[5]
print(d1) # {'a': 'haha', 'b': [1, 2, 3, 4], 'c': [6, 8, 9], 'dummy': 'another value'}
ret = d1.pop('dummy') # pop可以返回要删除的字典元素的值
ret,d1 # ('another value', {'a': 'haha', 'b': [1, 2, 3, 4], 'c': [6, 8, 9]})4.5 字典内置函数
通过len获取字典元素个数,即键的总数
d = {'a':123,'b':[4,5,6]}
print(len(d)) # 2
通过str可以以字符串形式输出字典
print(str(d)) # "{'a': 123, 'b': [4, 5, 6]}"
获取字典的键和值
list(d1.keys),list(d1.values)
# 结果:(['a', 'b', 'c'], ['haha', [1, 2, 3, 4], [6, 8, 9]])4.6 字典其余常用操作
字典遍历方法如下
#1.遍历key值 在使用上,for key in a和 for key in a.keys:完全等价。
a={'a': '1', 'b': '2', 'c': '3'}
print("遍历key值:")
for key in a:
print(key+':'+a[key])
#2.遍历value值
print("遍历value值:")
for value in a.values:
print(value)
#3.遍历字典项
print("遍历字典项:")
for kv in a.items:
print(kv)
#4.遍历字典键值
print("遍历字典健值:")
for key,value in a.items:
print(key+':'+value)
字典总是明确地记录键和值之间的关联关系,但获取字典的元素时,获取顺序是不可预测的。如果要以特定的顺序返回元素,一种办法是在for 循环中对返回的键进行排序。
favorite_languages = {
'jen': 'python',
'sarah': 'c',
'edward': 'ruby',
'phil': 'python',
}
for name in sorted(favorite_languages.keys):
print(name.title + ", thank you for taking the poll.")
# 输出结果如下:
Edward, thank you for taking the poll.
Jen, thank you for taking the poll.
Phil, thank you for taking the poll.
Sarah, thank you for taking the poll.
根据key找value
d = {'a' : [1, 2, 3], 'b' : [4, 5],'c':[1,2,3,4] }
key = ['a','c']
value=[]
for k in key:
value.append(d[k])
value # [[1, 2, 3], [1, 2, 3, 4]]
根据value找key
#根据value找key
d = { 'a' : [1, 2, 3], 'b' : [4, 5],'c':[1,2,3] }
value = [1,2,3]
t=[k for k,v in d.items if v == value]
print(t) # ['a', 'c']5.集合
集合是无序的不可重复的元素的集合。
5.1 创建集合
可以通过以下方法来创建集合
# 两种方式创建集合:
# 通过set函数
s1 = set([2, 2, 2, 1, 3, 3])
# 或使用尖括号{}
s2 = {2, 2, 2, 1, 3, 3}
print(s1) # {1, 2, 3}
print(s2) # {1, 2, 3}5.2 添加元素
使用add方法可以将元素添加到集合中
set1 = set(('a', 'bb', 'ccc'))
set1.add('dddd')
set1 # {'a', 'bb', 'ccc', 'dddd'}
除了add方法外,还可以使用update方法来添加元素,且参数可以是列表,元组,字典等
set1.update({5,6})
set1 # {5, 6, 'a', 'bb', 'ccc', 'dddd'}5.3 删除元素
使用remove方法将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
set1.remove('a')
set1 # {5, 6, 'bb', 'ccc', 'dddd'}
discard方法同样移除集合中的元素,且如果元素不存在,不会发生错误。
set1.discard('h') # 不存在的元素,但不会报错
set1 # {5, 6, 'bb', 'ccc', 'dddd'}
最后,还可以使用pop方法随机删除集合中的一个元素
set1.pop
set1 # {5, 6, 'bb', 'ccc'}5.4 集合运算
集合支持合并、交集、差分和对称差等数学集合运算
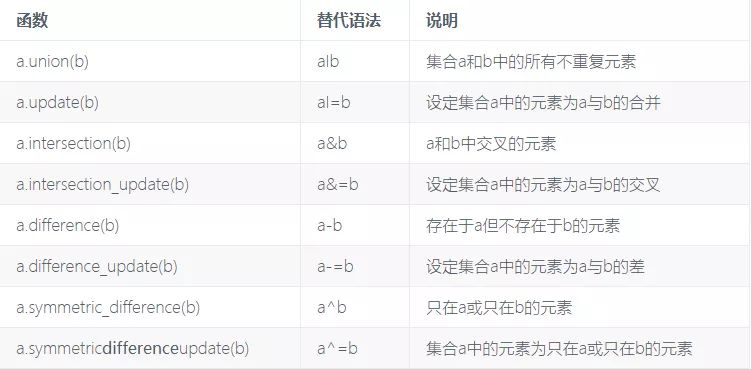
下面举一些例子
a = {1, 2, 3, 4, 5}
b = {3, 4, 5, 6, 7, 8}
print(a.union(b)) # {1, 2, 3, 4, 5, 6, 7, 8}
print(a.intersection(b)) # {3, 4, 5}
c = a.copy
c |= b
print(c) # {1, 2, 3, 4, 5, 6, 7, 8}
d = a.copy
d &= b
print(d) # {3, 4, 5}6.常用序列函数 6.1 enumerate函数
enumerate 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
seasons = ['Spring','Summer','Fall','Winter']
for i,ele in enumerate(seasons):
print(i,ele)
# 结果如下:
0 Spring
1 Summer
2 Fall
3 Winter6.2 sorted函数
sorted函数可以从任意序列的元素返回一个新的排好序的列表
print(sorted([7, 1, 2, 6, 0, 3, 2])) # [0, 1, 2, 2, 3, 6, 7]
print(sorted('horse race')) # [' ', 'a', 'c', 'e', 'e', 'h', 'o', 'r', 'r', 's']6.3 zip函数
zip可以将多个列表、元组或其它序列成对组合成一个元组列表.zip可以处理任意多的序列,元素的个数取决于最短的序列。
seq1 = ['foo', 'bar', 'baz']
seq2 = ['one', 'two', 'three']
zipped = zip(seq1, seq2)
print(list(zipped)) # [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
zip的常见用法之一是同时迭代多个序列,可能结合enumerate使用
for i, (a, b) in enumerate(zip(seq1, seq2)):
print('{0}: {1}, {2}'.format(i, a, b))
# 结果如下:
0: foo, one
1: bar, two
2: baz, three6.4 reversed函数
reversed 函数返回一个反转的迭代器。
aa = range(10)
rr = reversed(aa)
print(list(rr)) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
至此,本次分享已结束如果你喜欢的话,可以转发或者点个“在看”支持一下~点击原文链接,可以下载《Python工具代码速查手册》,可以点个star支持一下哦~简介:浩彬老撕 好玩的数据炼丹师, 曾经的IBM数据挖掘攻城狮, 还没开始就过气数据科学界的段子手, 致力于数据科学知识分享,不定期送书活动 返回搜狐,查看更多
责任编辑:














 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









