






中文分词算法大致分为基于词典规则与基于机器学习两大派别,不过在实践中多采用结合词典规则和机器学习的混合分词。由于中文文本是由连续的汉字所组成,因此不能使用类似英文以空格作为分隔符进行分词的方式,中文分词需要考虑语义以及上下文语境。本文主要介绍基于词典规则的中文分词。
基于词典规则的中文分词简单来说就是将中文文本按照顺序切分成连续词序,然后根据规则以及连续词序是否在给定的词典中来决定连续词序是否为最终的分词结果。不同规则对应最终的分词结果是不一样的。
假设现在有段中文文本"网易杭研大厦",并且词典中包含["网易", "杭研", "大厦", "网易杭研", "杭研大厦", "网易杭研大厦"]。基于这个简单的小词典不需要任何的理论知识可以非常容易的分成下面这四种结果:
- 网易 / 杭研 / 大厦
- 网易 / 杭研大厦
- 网易杭研 / 大厦
- 网易杭研大厦
上面这四种分词结果都是正确的,不过在中文中越长的单词所表达的意义越丰富并且含义越明确,所以我们会更倾向于选择"网易杭研大厦"。比如我们更倾向将"北京大学"作为一个完整的单词,而不是划分成"北京"和"大学"两个碎片化的单词,"北京大学"比"北京"和"大学"所表达的意义更加丰富,同时"北京大学"所表达的含义也更加明确。
在中文中越长的单词所表达的意义越丰富并且含义越明确,因此就有了第一条规则:在以某个下标递归查词的过程中,优先输出更长的单词,这种规则也被称为最长匹配算法。根据下标扫描顺序的不同分为:
- 正向最长匹配,下标的扫描顺序从前往后;
- 逆向最长匹配,下标的扫描顺序从后往前;
不过在介绍具体算法之前,先来看看如何使用Python加载HanLP的词典。
1. 加载HanLP词典
为了方便使用HanLP附带的迷你核心词典。这里以Ubuntu系统为例,如果不知道如何在Ubuntu中安装HanLP,可以参考下面这篇文章:
触摸壹缕阳光:一步一步教你在Ubuntu中安装HanLPzhuanlan.zhihu.com
首先需要查看HanLP自带词典的具体路径,可以通过下面命令进行查看(需要进入安装HanLP的虚拟环境中):
hanlp -v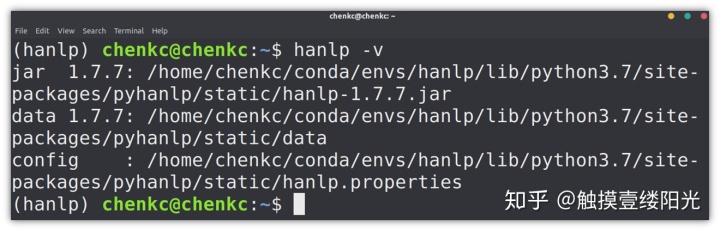
其中data路径中包含HanLP自带的一些数据文件,进入存放词典的"dictionary"文件中:
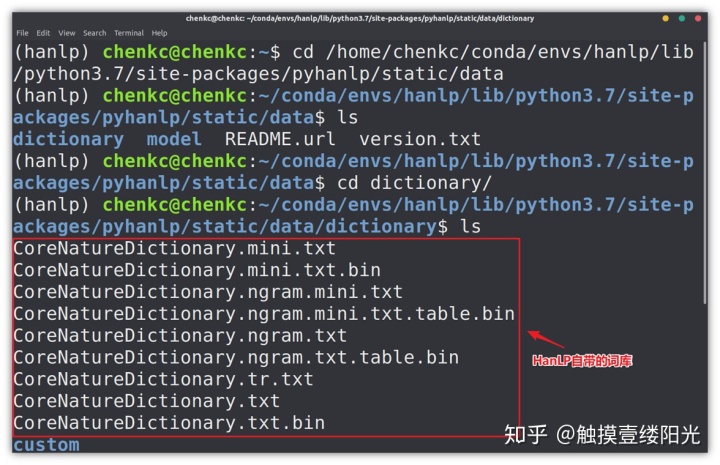
"CoreNatureDictionary.mini.txt"就是我们接下来要使用的迷你核心词典,使用head -n 5 CoreNatureDictionary.mini.txt查看迷你核心词典的前5行。
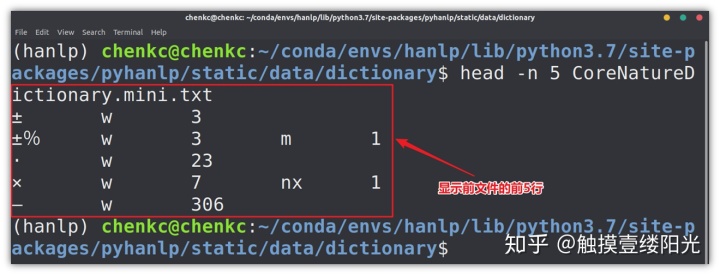
HanLP中的词典格式是一种以空格分隔的表格形式,第一列为单词本身,之后的两列分别表示词性和单词表示当前词性时的词频,单词可能不止一种词性,因此后面的列依次类推表示词性和单词表示当前词性时的词频。比如"x w 7 nx 1"表示"x"这个词以标点符号(w)的身份出现了7次,以字母专名(nx)的身份出现了1次,当然这里的词频是在某个语料库上进行统计的。不过在基于词典分词的过程中,词性和词频没有太大的用处,可以暂时忽略。
使用Python加载HanLP自带的迷你核心词典"CoreNatureDictionary.mini.txt"词典代码如下:
from 注意:
- JClass函数是连通Java和Python的桥梁,可以根据Java路径名获得Python类;
- HanLP默认配置的词典是"CoreNatureDictionary.txt",如果想要使用迷你的"CoreNatureDictionary.mini.txt"只需要将配置文件中的".txt"替换成"mini.txt";
加载好了词典,在具体介绍正向最长匹配、逆向最长匹配以及双向最长匹配之前,先来看看什么是最长匹配?
最长匹配算法是基于词典进行匹配,首先选取词典中最长单词的汉字个数作为最长匹配的起始长度。比如现在词典中的最长单词中包含5个汉字,那么最长匹配的起始汉字个数就为5,如果与词典匹配不成功就减少一个汉字继续与词典进行匹配,循环往复,直至与词典匹配且满足规则或者剩下一个汉字。
2. 正向最长匹配
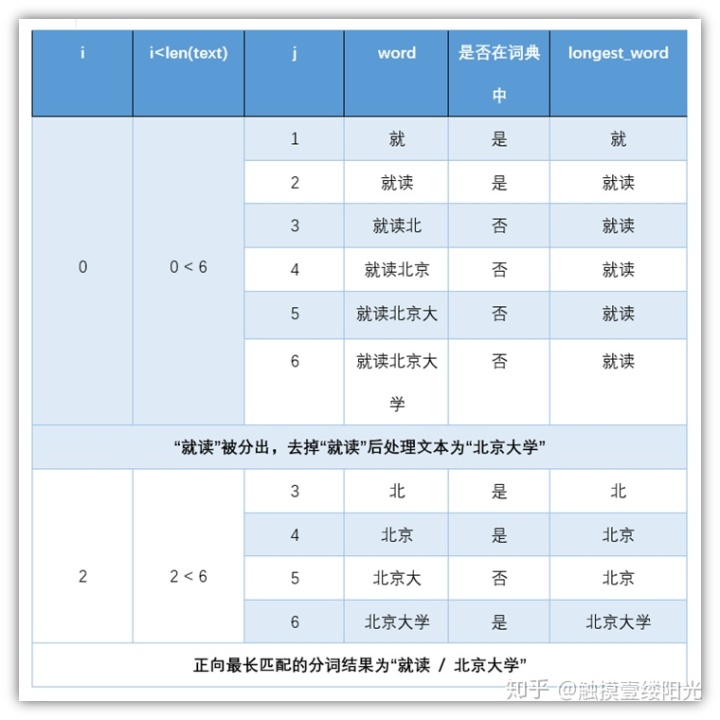
正向最长匹配简单来说就是从前往后进行取词,假设此时词典中最长单词包含5个汉字,对"就读北京大学"进行分词,正向最长匹配的基本流程:
- 第一轮
- 正向从前往后选取5个汉字。"就读北京大",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"就读北京",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"就读北",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"就读",词典中有对应的单词,匹配成功;
扫描终止,输出第1个单词"就读",去除第1个单词开始第二轮扫描。
- 第二轮
- 去除"就读"之后,依然正向选择5个汉字,不过由于我们分词句子比较短,不足5个汉字,所以直接对剩下的4个汉字进行匹配。"北京大学",词典中有对应的单词,匹配成功;
至此,通过正向最大匹配对"就读北京大学"的匹配结果为:"就读 / 北京大学"。不过书中实现的正向最长匹配没有考虑设置最长匹配的起始长度,而是以正向逐渐增加汉字的方式进行匹配,如果此时匹配成功还需要进行下一次匹配,保留匹配成功且长度最长的单词作为最终的分词结果。
不过为了提升效率在实际使用中倾向于设置最长匹配的起始长度,如果想更进一步提升分词的速度,可以将词典按照不同汉字长度进行划分,每次匹配的时候搜索相对应汉字个数的词典。虽然代码和讲解有所不同,但是本质和结果都是一样的,越长单词的优先级越高,这里注意一下即可。
from 使用上面的代码对"就读北京大学"进行分词,具体代码流程如图所示:
使用正向最长匹配对"就读北京大学"的分词效果很好,但是如果对"研究生命起源"进行分词的话,正向最大匹配分词的结果为"研究生 / 命 / 起源",产生这种误差的原因在于,正向最长匹配中"研究生"的优先级要大于"研究"("研究生"长度长)。正向匹配出的"研究生"优先级要高,很自然的想法从后往前进行匹配,这样就可以先将"生命"划分出来,避免从前到后先把"研究生"划分出来的错误。
3. 逆向最长匹配
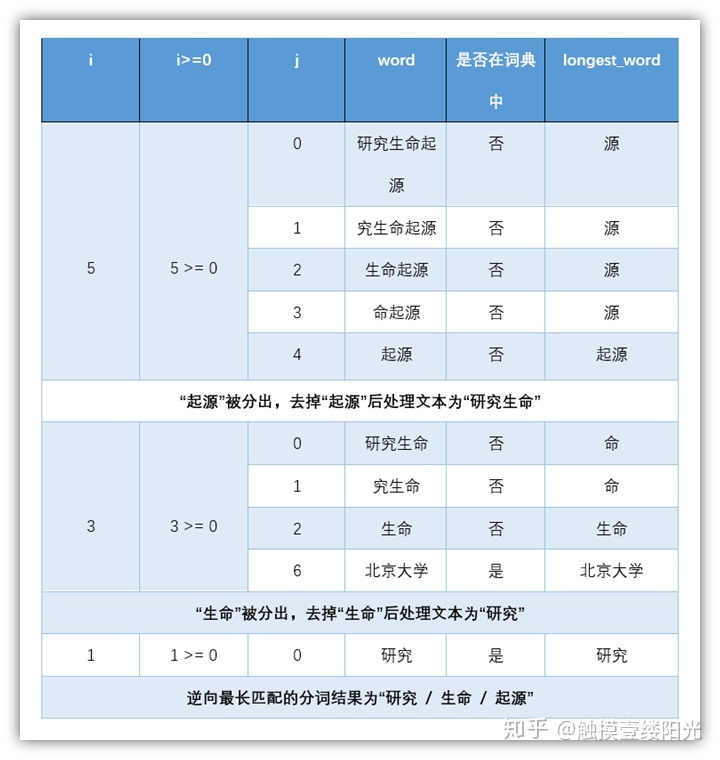
逆向最长匹配顾名思义就是从后往前进行扫描,保留最长单词,逆向最长匹配与正向最长匹配唯一的区别就在于扫描的方向。逆向最长匹配简单来说就是从后往前进行取词,假设此时词典中最长单词包含5个汉字,对"研究生命起源"进行分词,逆向最长匹配的基本流程:
- 第一轮
- 正向从后往前选取5个汉字。"究生命起源",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"生命起源",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"命起源",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"起源",词典中有对应的单词,匹配成功;
扫描终止,输出第1个单词"起源",去除第1个单词开始第二轮扫描。
- 第二轮
- 去除"起源"之后,依然反向选择5个汉字,不过由于我们分词句子比较短,不足5个汉字,所以直接对剩下的4个汉字进行匹配。"研究生命",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"究生命",词典中没有对应的单词,匹配失败;
- 减少一个汉字。"生命",词典中有对应的单词,匹配成功;
扫描终止,输出第2个单词"生命",去除第2个单词开始第三轮扫描。
- 第三轮
- 去除"生命"之后,依然反向选择5个汉字,不过由于我们分词句子比较短,不足5个汉字,所以直接对剩下的2个汉字进行匹配。"研究",词典中有对应的单词,匹配成功;
至此,通过逆向最大匹配对"研究生命起源"的匹配结果为:"研究 / 生命 / 起源"。
在书中实现的逆向最长匹配没有考虑设置最长匹配的起始长度,其余与上面的具体流程一致。
from 使用上面的代码对"研究生命起源"进行分词,具体代码流程如图所示:
4. 双向最长匹配
对"项目的研究"进行分词:
- 正向最长匹配:"项目 / 的 / 研究"
- 逆向最长匹配:"项 / 目的 / 研究"
对"研究生命起源"进行分词:
- 正向最长匹配:"研究生 / 命 / 起源"
- 逆向最长匹配:"研究 / 生命 / 起源"
通过上面的例子可以看出,有时候正向最长匹配正确,而有的时候逆向匹配的更好,当然也有可能正向最长匹配和逆向最长匹配都无法消除歧义的情况。清华大学孙茂松教授做过统计,在随机挑选的3680个句子中,正向匹配错误而逆向匹配正确的句子占比9.24%,正向匹配正确而逆向匹配错误的情况则没有被统计到。
因此有人提出了融合正向最长匹配和逆向最长匹配的双向最长匹配,双向最长匹配简单来说就是同时执行正向最长匹配和逆向最长匹配,然后在给定的一些规则中选择最优,本质上就是在正向最长匹配和逆向最长匹配中进行二选一。
择优规则:
- 最长的单词所表达的意义越丰富并且含义越明确。如果正向最长匹配和逆向最长匹配分词后的词数不同,返回词数更少结果;
- 非词典词和单字词越少越好,在语言学中单字词的数量要远远小于非单字词。如果正向最长匹配和逆向最长匹配分词后的词数相同,返回非词典词和单字词最少的结果;
- 根据孙茂松教授的统计,逆向最长匹配正确的可能性要比正向最长匹配的可能性要高。如果正向最长匹配的词数以及非词典词和单字词都相同的情况下,优先返回逆向最长匹配的结果;
双向最长匹配的代码如下:
from 通过观察双向最长匹配对"项目的研究"的分词结果,发现即使是融合了正向最长匹配和逆向最长匹配的双向最长匹配也不一定得到正确的分词结果,甚至有可能正确率比逆向最长匹配还要低,由此,规则系统的脆弱可见一斑,规则集的维护有时是拆东墙补西墙,有时是帮倒忙。不过基于词典分词的核心价值不在于精度,而在于速度。
参考:《自然语言处理入门》 本文代码来自《自然语言处理入门》















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









