






今天给大家分享三个极实用的Python爬虫案例。
1
爬取美图网站
爬取图片是最常见的爬虫入门项目,不复杂却能很好地熟悉Python语法、掌握爬虫思路。当然有两个点要注意:
不要侵犯版权
要注意营养
思路流程:
获取网址的response,分页内容,解析后提取图集的地址
下载图片(也就是获取二进制内容,然后在本地复刻一份)
部分代码:
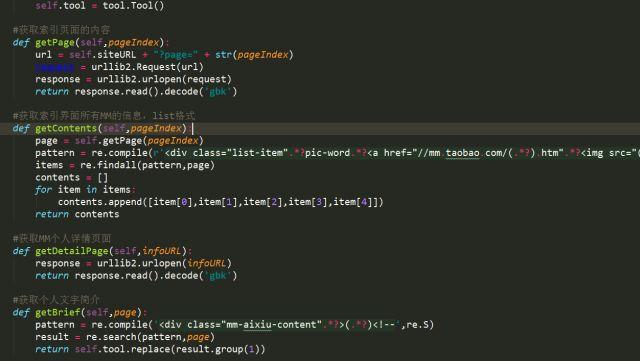
运行结果:
2
爬取微博数据
爬虫的最大功能之一就是整合数据,能弄到更全面的信息,真正做好大数据的分析,在这个数据说话的年代,影响是决定性的。(注意别侵权)
思路流程:
利用chrome浏览器,获取自己的cookie
获取你要爬取的用户的微博User_id
将获得的两项内容填入到weibo.py中,替换代码中的YOUR_USER_ID和#YOUR_COOKIE,运行代码
部分代码:
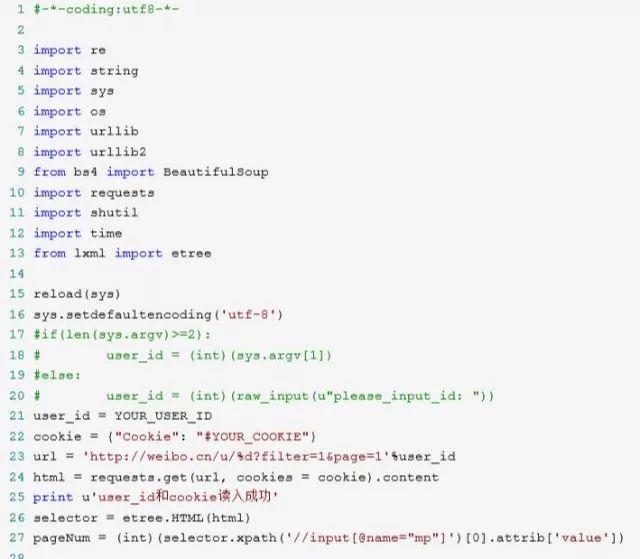
用wordcloud等软件生成词云,它会根据信息的频率、权重按比列显示关键字的字体大小。

3
爬取王者荣耀全套皮肤
怎么获取全套皮肤?用钱买,或者用爬虫爬取下来~虽然后者不能穿。这个案例稍微复杂一点,但是一个非常值得学习的项目。
思路流程:
首先进入所有英雄列表,你会看到下图
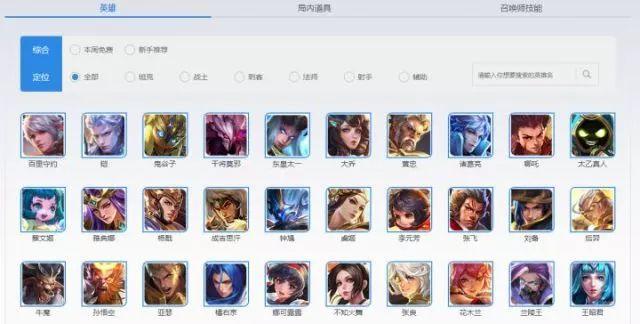
在这个网页中包含了所有的英雄名称。点击其中一个英雄例如“百里守约”,进去后如下图:

△网址为
https://pvp.qq.com/web201605/herodetail/196.shtml
网址中196.shtml以前的字符都是不变的,变化的只是196.shtml。而196是“百里守约”所对应的数字,要想爬取图片就应该进入每个英雄图片所在的网址,而网址的关键就是对应的数字。那么这些数字怎么找呢?
在所有英雄列表中,打开浏览器的开发者工具,刷新,找到一个json格式的文件,如图所示:
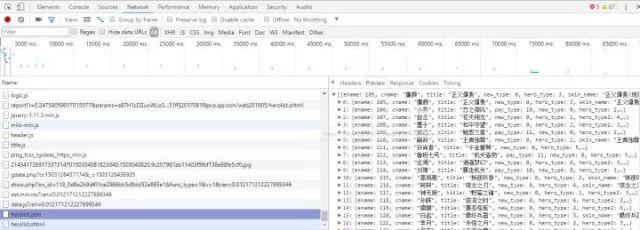
这时就会看到所有英雄对应的数字了。在上图所示的Headers中可以找到该json文件对应的网址形式。将其导入Python,把这些数字提取出来,然后模拟出所有英雄的网址即可。
小节代码:
#爬取王者荣耀英雄图片#导入所需模块import requestsimport reimport os#导入json文件(里面有所有英雄的名字及数字)url= http://pvp.qq.com/web201605/js/herolist.json #英雄的名字jsonhead={ User-Agent : 换成你自己的head }html = requests.get(url,headers = head)html=requests.get(url)html_json=html.json#提取英雄名字和数字hero_name=list(map(lambda x:x[ cname ],html_json)) #名字hero_number=list(map(lambda x:x[ ename ],html_json)) #数字
下载图片
现在可以进入所有英雄的网址并爬取网址下的图片了。进入一个英雄的网址,打开开发者工具,在NetWork下刷新并找到英雄的皮肤图片。如图所示:
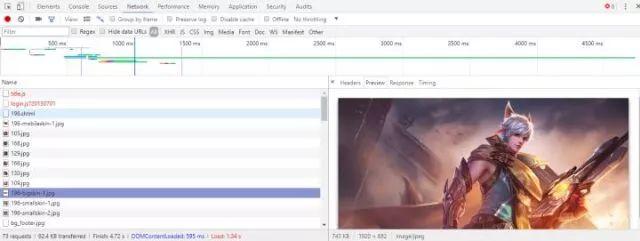
然后在Headers中查看该图片的网址。会发现皮肤图片是有规律的。我们可以用这样的方式来模拟图片网址
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(v)+'/'+str(v)+'-bigskin-'+str(u)+'.jpg ,在该网址中只有str(v)与str(u)是改变的(str( )是Python中的一个函数),str(v)是英雄对应的数字,str(u)只是图片编号,例如第一个图片就是1,第二个就是2,第三个……而一个英雄的皮肤应该不会超过12个(可以将这个值调到20等)。接着就是下载了。
下载代码:

执行完上面的代码后只需要执行main函数就行了

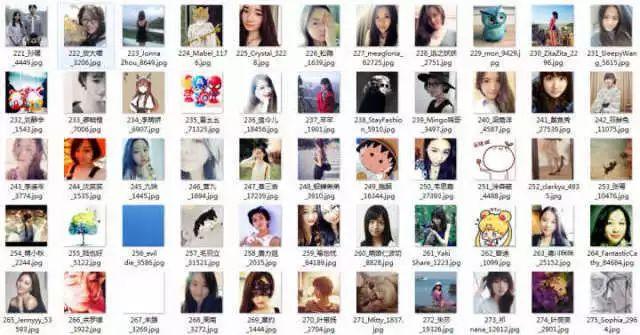
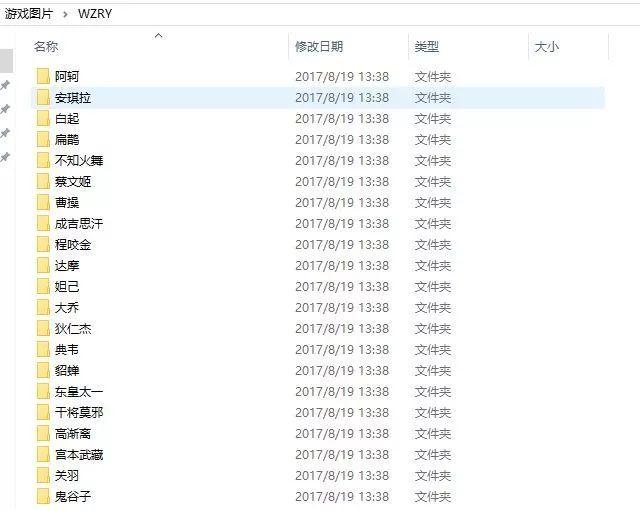
爬取下来的图片是这样,每个文件夹里面是该英雄对应的图片,如下图:
End.
来源:CSDN
深圳线下·零基础Python爬虫入门
利用Python自带库以及第三方库获取网站数据并存储下来,同时可以大规模爬取数据。让你零基础入门Python爬虫。
适合人群:
1. Python零基础学员
2. 即将毕业的大学生
3. 频繁手工获取数据录入员
活动时间:12.28日 星期六
下午13:00-17:00















 4459
4459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









