






前言
接着上一篇,我们这篇将从loss角度出发,来解析FasterRCNN的精髓。
4.从loss到全局解析
实战上面已经说过了,不知各位老爷有没有成功跑起来,(什么?没有跑起来?那我就不知道了,要不你们私信我吧,我“有时间”看看)。
不知道各位老爷们曾经有过类似于VGG、Inception v3物体分类模型的实战?(没有也没关系),大致流程是这样的:
- 图片数据集准备
- 搭建网络
- 定义损失函数,优化器,学习率,train_op等
- [run,产生错误,修改错误] for _ in range(10000000)
其实关于FasterRCNN论文解读的相关文章已经够多了,大多数读者思路已经较为清晰了吧。如果不清楚,我推荐下面文章:
https://zhuanlan.zhihu.com/p/31426458
这位老兄说的已经非常清楚了。Anchor我在上一章也说过了。接下来我们就从代码中解读Faster RCNN的一些细节和逻辑结构。
话说FasterRCNN的代码几千行,又是跳来跳去的,这可咋办?从哪儿读?从头读的话我相信大多数人脑壳一会儿就晕了,经我读了大概两三遍的经验,不妨我们先来看loss函数定义(咱们不走寻常路,我们从后向前解析)
Loss函数定义在lib/nets/network.py文件中的函数_add_losses中,上面的一些语句意思我已经注释出来了。
def 老爷们,看懂没?没有吗?没关系,我来解读一下,就是loss函数中定义了四个小loss,这不正好对应了论文中的四个损失嘛,分别是
(1) RPN层的两个损失:1.是否为前景背景的二分类交叉熵损失 2. bbox的第一次修正损失
(2) 最后全连接层分类的两个损失:1.num_classes分类损失 2.第二次bbox修正损失
好,现在我们进入每个小loss的定义过程中(慢慢抽丝剥茧):
第一个小loss(是否为前景背景的二分类交叉熵损失)是这样定义的:
rpn_cls_score 我们从sparse_softmax_cross_entropy_with_logits的两个输入来看,一个是rpn_cls_score,一个是rpn_label,咦,好像有点感觉了,这rpn_cls_score应该是网络前向过程的结果,预测的得分,这rpn_label应该是人为定义的label,和咱们学的图像分类有点像哦。
那这个rpn_cls_score是啥,从哪儿来的结果嘞。不断地追溯,终于追到了lib/net/vgg16.py中了(虽说这个py文件是vgg16命名的,但是可不要被他蛊惑了,他是network的子类,是我们最核心的网络模型搭建脚本)。
我们发现,这个rpn_cls_score是函数build_rpn的输出,追溯到build_rpn中(原来这里在搭建RPN层呀),这个rpn_cls_score就是特征图经过3*3卷积后,再经过一个1*1,通道为18卷积后的结果,如图6所示。

再看看rpn_cls_score的shape=(1,h,w,18),想想看咱们有多少锚,总共(h*w*9),那就是每个锚有两个位置放score,一个是前景fg的score,一个是背景fg的score,若有所悟!
那我们根据函数build_rpn代码(在该层搭建RPN层)完善下图6,获得图7
rpn_cls_score 图7如下,rpn_cls_score_reshape (shape=(1,9*h,w,2),腾出一个维度大小为2,用来进行softmax) 是rpn_cls_score通过reshape层的结果,rpn_cls_prob_shape 则是rpn_cls_score_reshape通过softmax层后的结果,我们知道 ,通过softmax层输出的就是分类问题的概率值。自然而然地,通过softmax层,shape大小不变,所以rpn_cls_prob_shape的shape仍然是(1,9*h,w,2),后面我们再次通过一个reshape,将rpn_cls_prob_shape变为rpn_cls_prob,这样一看,rpn_cls_score和rpn_cls_prob的shape一样,都是(1,h,w,18)。
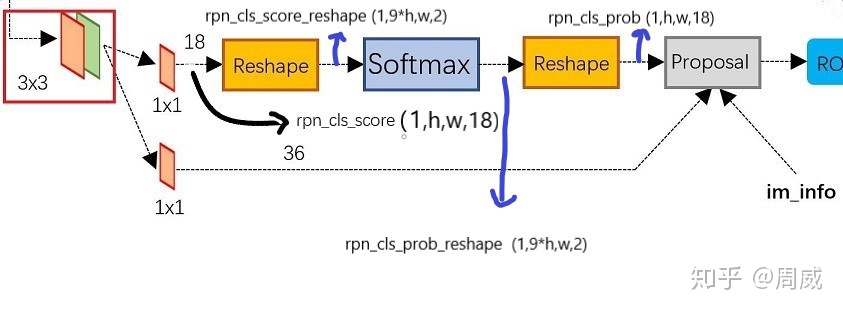
那应该就有人问了,既然这条支路输入输出维度一样,为何还要经过两次reshape?那是因为我们softmax用于二分类问题,必须要有个单独维度为2!
好嘞,说了这么多支路信息,现在我们第一个小loss的logit知道了,我们还需要一个label,就能做损失了。
回到上面,第一个loss的logit= rpn_cls_score,他的label=rpn_label。我们知道了rpn_cls_score,现在我们要找的就是rpn_label。我们仍然在vgg16.py中找到了他的身影(所以为啥说vgg16.py是fasterRCNN的主体嘞),rpn_label藏在函数build_proposals中。
rpn_labels 我们进入函数_anchor_target_layer中,他是这样定义的:
def 我们在这里留个疑惑,大家注意到了为啥rpn_label需要输入rpn_cls_score呢?我们平时做图片分类的时候,label是人为定义的,和网络输出logit有什么关系呢?这里留个悬念,后面会有说明。
我们可以看到rpn_label又是函数anchor_target_layer中得到的输出,这里我们就看到了,得到rpn_label不仅仅需要上面的rpn_cls_score,还需要最重要的gt_boxes,这是图片中给出的信息,我们的思路应该是从gt_boxes中获取rpn_labels,而不是rpn_cls_score。
好了,我们进入正题,进入anchor_target_layer函数
发现原来输入的rpn_cls_score只是为了提取特征图的h和w(有点想笑)
# map of shape (..., H, W)
height, width = rpn_cls_score.shape[1:3]anchor_target_laye函数有点长,不过我做了些标注,便于大家理解。
def 大家阅读代码后,发现这段代码做了一下几件事:
(1) 去除越界的anchor
(2) 将与gt boxes拥有最大重叠的anchor或者与gt boxes的IOU>0.7的anchor设为前景(fg)
(3) 将与gt boxes的 IOU<0.3的anchor设为背景(bg),其余全部设为-1(不是前景也不是背景)
(4) 进行降采样,从选择出来的fg和bg中随机选择出128个fg和128个bg,其他设为-1
(5) 将上述的128个fg(1)和128个bg(0)放入长度为(1*h*w*9,)的全部值为-1的列表,然后reshape成和rpn_cls_score一样的形状(1,h,w,9)
我们可以看出,rpn_cls_score是网络通过RPN层前向传播的结果,就和我们接触图片分类的logit一样。rpn_label是人为设置的将与gt boxes关系(重叠面积)最大和最小的anchor映射到形状(1,h,w,9)上,然后求rpn_cls_score(1,h,w,18)和rpn_label(1,h,w,9)的交叉熵(等等,你们没发现我说错了一个小点呢吗)
我们跳回第一个loss的定义
rpn_cls_score 这里有个
rpn_select = tf.where(tf.not_equal(rpn_label, -1)) #找到rpn_label不等于-1的位置,就是128个fg和128个bg这是找到rpn_label中前景fg和背景bg的索引,根据索引在rpn_cls_score和rpn_label
找到256个对应位置,然后求交叉熵(对吧,要找到256个前景背景后再求交叉熵,这里就没错了)!
说了这么多,第一个损失是不是看懂了?如果看懂了,后面其他损失就很easy了。
接着我们来看第二个loss:
rpn_bbox_pred 第二个loss的计算需要四个输入rpn_bbox_pred,rpn_bbox_targets,rpn_bbox_inside_weight,rpn_bbox_outside_weights。我们还是在计算loss的时候,还是分一下label和logit,很显然,这里的rpn_bbox_pred是预测的,是logit,而label= rpn_bbox_targets,另外两个应该就是来计算loss的权重了,后面遇到了定义在进行详细说明。
现在我们去看看rpn_bbox_pred和rpn_bbox_targets的定义。
老样子,我们进入vgg16.py文件中,找到了
rpn_cls_prob, rpn_bbox_pred, rpn_cls_score, rpn_cls_score_reshape = self.build_rpn(net, is_training, initializer)所以是这样子的,RPN层不是有两个支路嘛,上面一个是预测前景背景的,下面一个就是对anchor进行第一次框回归,那么特征图通过1*1卷积,输出维度为(1,h,w,36)的就是rpn_bbox_pred。如图8
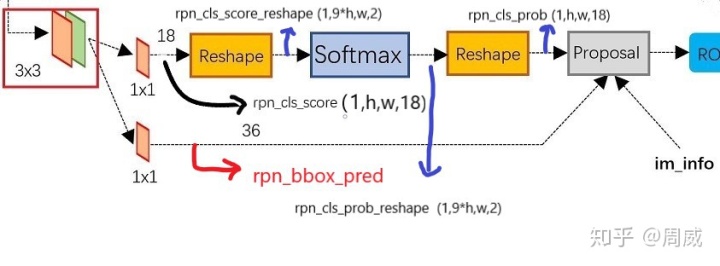
我们的anchor有h*w*9个,rpn_bbox_pred的维度为(1,h,w,36),所以rpn_bbox_pred包含了每个anchor的坐标变换(dx,dy,dw,dh),如果不懂,这里不妨温故下坐标变换(dx,dy,dw,dh)的知识。
接着我们来看rpn_bbox_target,按理来说,这个是人为设定的label值,我们进入vgg16.py的父类network.py中,找到函数_anchor_target_layer,他是这么定义的:
def 虽然这个函数的返回值与rpn_bbox_target无关,但是他将rpn_bbox_target以字典表的形式进行了存储(好像也发现了rpn_bbox_inside_weights和rpn_bbox_outside_weights)。产生rpn_bbox_target, rpn_bbox_inside_weights, rpn_bbox_outside_weights代码如下:
rpn_labels我们进入函数anchor_target_layer中,妈耶,好熟悉的过程呀(不是我们上面求第一个loss的时候也进来过嘛)
此处省去函数anchor_target_layer一万行代码。。。。。。
我们提取anchor_target_layer中关于生成rpn_bbox_target的代码。
overlaps 以上代码中的overlaps求所有的anchor(共h*w*9个,这里的h,w是特征图的高和宽)与gt_boxes的重叠IOU。然后嘞,argmax_overlaps是求overlaps每行中最大的索引,这句话是什么意思呢?
每行的数据是某个特定的anchor与一张图片所有gt_bboxes的IOU,求最大索引,就是找每个anchor最近的gt_bboxes的标号。
bbox_targets 这里就是计算每个anchor转换到该anchor最近的gt_bboxes的(dx,dy,dw,dh)值。
哦,恍然大悟。
接着我们来看产生rpn_bbox_inside_weights 和rpn_bbox_outside_weights两个权重的代码。
bbox_inside_weights 上面代码有点长,主要就两个意思:
(1) rpn_bbox_inside_weights是一个(1,h,w,36)的数组,其中在所有anchor中,有128个positive的anchor,这128个positive的anchor对应位置权重设为1,因为是和坐标对应的,所以是(1.0,1.0,1.0,1.0),其余所有anchor 的权重设为(0.0,0.0,0.0,0.0)
(2) rpn_bbox_outside_weights也是一个(1,h,w,36)的数组,其中在所有anchor中,有256个positive+negative的anchor,这256个anchor对应位置权重设为(1/256,1/256,1/256,1/256),其余所有anchor 的权重设为(0.0,0.0,0.0,0.0)
了解了rpn_bbox_target, rpn_bbox_inside_weights, rpn_bbox_outside_weights后,我们跳回原来定义的loss中,他是这样定义的:
rpn_loss_box = self._smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, rpn_bbox_inside_weights,
rpn_bbox_outside_weights, sigma=sigma_rpn, dim=[1, 2, 3])
他将以上rpn_bbox_target, rpn_bbox_inside_weights, rpn_bbox_outside_weights作为smooth_L1损失的输入。我们回顾下smooth_L1损失。
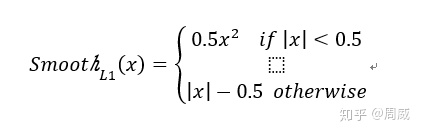
接着我们根据代码来看下具体loss定义:
def 这段代码中的
smoothL1_sign = tf.stop_gradient(tf.to_float(tf.less(abs_in_box_diff, 1. / sigma_2)))smoothL1_sign是找到满足smoothL1判断条件的|x|<0.5中x的位置。
然后根据位置进行损失函数的定义:
in_loss_box = tf.pow(in_box_diff, 2) * (sigma_2 / 2.) * smoothL1_sign + (abs_in_box_diff - (0.5 / sigma_2)) * (1. - smoothL1_sign)后面再根据rpn_bbox_outside_weights给上面定义的损失定义权重
out_loss_box = bbox_outside_weights * in_loss_box #对于所有fg和bg(共256)乘1/256后面再求和取平均即可!
至此,第二个loss的定义就结束了,后面还有两个loss和上面的两个loss基本是相同的定义,这里不再赘述。
既然已经将loss定义看懂了,那我觉得后面不管是tensorflow框架还是caffe框架,做的事情都是比较easy的了,具体的一些train_op操作就在train.py中看吧。
我们的FasterRCNN 就讲到这里了,其实包括数据处理,模型搭建,loss定义,train_op定义,FasterRCNN还是有很多细节之处比较精妙,我个人认为,熟读FasterRCNN代码,不仅可以掌握对FasterRCNN的理解,还能提高个人的代码水平。
当然了,初学者还是要自己仔仔细细地看一下代码,不能想着急于求成,我的博客只能作为一个参考和辅助作用,更多的需要读者自己进行领悟。















 4717
4717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









