





机器学习数据分析极简思路
机器学习拥有庞大的知识体系,这里对机器学习的数据分析的整个思路和流程作最最简单的归纳。机器学习的步骤大致包括:1)理解和清理数据2)特征选择3)算法建模4)测试评估模型
1)理解和清理数据
理解数据
数据是机器学习大餐的原始食材,对数据分析起着至关重要的作用,理解原始数据的含义将有助于进一步分析。例如,甲基化图谱与年龄有着显著的相关性,而与性别关系不大,因此在数据分析中,对这两个特征(faeature)需要区别对待。更好的理解方式是直接可视化某些数据,例如对于经典的鸢尾花数据集,可以通过python seaborn绘图包可视化各个特征(feature)之间的关系;对于大数据,则可以进行降维分析(PCOA、tSNE),理解数据组成主成分贡献度。
pip install seaborn
import matplotlib.pyplot as pyplot
import seaborn as sb
import pandas as pd
%matplotlib inline
data=pd.read_csv('iris.csv') #pandas 读入数据
data.head(3) #查看数据
data.describe() #数据基本统计
sb.pairplot(data.dropna(),hue='Species')
鸢尾花数据组成

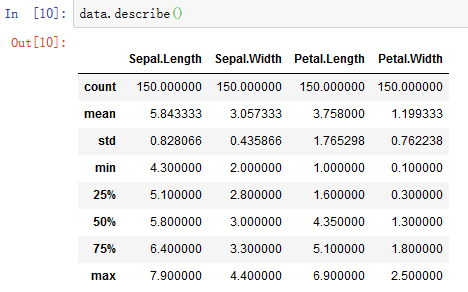
鸢尾花数据所有feature基本数理统计
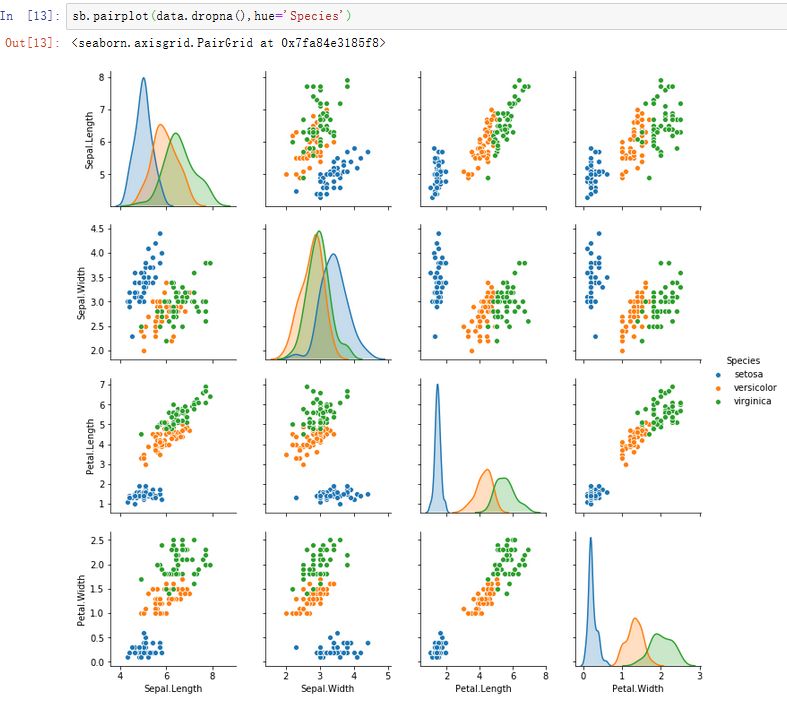
 鸢尾花数据不同feature相互关系
鸢尾花数据不同feature相互关系
剔除异常值
清理数据的目的在于去除原始数据中的异常值和想办法处理缺失值,我们拿到手上的数据不可能尽善尽美,总有一些妖孽作祟,对于异常值我们应当剔除。举个栗子,假设在鸢尾花数据集中,有一个样本显示鸢尾花花瓣长度10m,其他诸如花瓣宽度、花萼长宽值都正常,可以脑补一下这是一朵什么样的花,那么这个样本显然应该剔除。处理缺失值
缺失值在数据分析中很常见,总有一些样本观测值会因为这那的原因缺失,处理缺失值如果样本数量很大,而包含缺失值的样本又少,这个时候果断去掉这些样本,眼不见为净;如果因为样本有限或者缺失值太多,就要想办法补全缺失值(imputation),常常利用逻辑回归建立模型,找出这些数据变化的规律,从而预测缺失值。如何合理推断和填回这些缺失值是一门大学问,哪种方法好,我也不敢妄言。
2)特征选择
工业界广泛流传的一句话是:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征选择是机器学习的关键的关键。特征选择目的在于提取跟目标最为有效的信息,降低数据维度和计算成本,同时防止过拟合(overfitting,训练集特征用的太多太细,以致于在测试集中不适)。要知道,并不是特征越多,结果越好,没有严格意义上的特征累加效应,有时候好的几个特征胜于大量零碎的特征取得的效果。
在许多大数据挖掘竞赛中(国内的阿里天池和国外的kaggle平台),最复杂的过程莫过于特征工程建立阶段,大概占据了整个竞赛过程的70%的时间和精力,最终建立的模型的好坏大多也取决于特征工程建立的好坏。遗憾的是,特征工程不像模型建立的过程有着固定的套路,特征工程的建立凭借的更多的是经验,因此没有统一的方法。这里抛砖引玉介绍一些常见的办法,更为详细的内容请参考文后链接。a)特征过滤法
比较简单,它按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或者待选择阈值的个数,选择合适特征。例如,我们可以简单的计算出每个feature的方差,方差越大说明这个feature在样本中变异大,即有区分性;而越小的(极端时方差为0),即表示在所有样本中一样,特征选择时则可不考虑这些特征。我们可以选择方差最大的前n个feature用于建模,这就是最为简单的方差筛选法。b)包装法
根据目标函数,通常是预测效果评分,每次选择部分特征,或者排除部分特征。c)嵌入法
则稍微复杂一点,它先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小来选择特征。类似于过滤法,但是它是通过机器学习训练来确定特征的优劣,而不是直接从特征的一些统计学指标来确定特征的优劣。踩雷说:特征选择之后,需要从原始数据矩阵提取相应的特征重构矩阵,那么训练集和测试集的特征经过你各种变换之后,应当保持一一对应,类别和顺序在矩阵中都应该一致。
目前,已经有一些套路化的特征选择工具,例如python的FeatureSlector包,见链接。
3)算法建模
针对具体的问题,是分类问题?回归问题?还是其他?选择合适的模型,或者使用集成的算法模型。常见的算法模型包括:对于回归问题:
a)线性回归(回归,LinearRegression)
b)岭回归(回归,Ridge)Ridge是线性回归加L2正则平方,以防止过拟合
c)拉索回归(Lasso),加入惩罚函数L1正则绝对值,防止过拟合
d)弹性网络回归(回归),同时使用L1和L2正则。
e)K近邻(回归和分类,KNeighborsRegressor)
f)决策树(回归和分类,DecisionTreeRegressor)
g)支持向量机(回归和分类,SVR)
对于分类问题:
a)支持向量机(回归和分类,SVC)
b决策树(回归与分类,DecisionTreeClassifier)
c)逻辑回归(分类,LogisticRegression)
d)LDA线性判别分析(分类,LinearDiscriminantAnalysis)
e)K近邻(分类,KNeighborsClassifier)
值得一提的是无论是分类还是回归问题,基于决策树和SVM的算法都有比较好的表现。
4)测试评估模型
测试评估模型的目的在于,解决模型的欠拟合(under-fitting)和过拟合(over-fitting)问题,通过即时的反馈不断调整模型、优化模型,使得模型更加稳健。
实际上,测试评估模型应该在你建模之前就考虑,例如是否需要设置纯粹的外部数据验证集,若没有这样的数据,你怎样划分数据进行建模预测?
在实际训练中,模型通常对训练数据好,但是对训练数据之外的数据拟合程度差。用于评价模型的泛化能力(即模型普适性)。交叉验证的基本思想是把在某种意义下将原始数据进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对模型进行训练,再利用验证集来测试模型的泛化误差。另外,现实中数据总是有限的,为了对数据形成重用,比较常用的是k-fold交叉验证法。测试评估模型的时候,常常结合AUC曲线判断模型好坏。
sklearn 算法小试
实现目的
sklearn是python中一个强大的机器学习模块,拥有众多的机器学习算法和功能。这里,通过sklearn的datasets构建一个数据集,并用4种常用算法:逻辑回归(LogisticRegression)、支持向量机(SVM)、决策树(DecisionTree)和集成算法(VotingClassifier)对训练集建模,然后对测试集预测,最终通过得分看一下4种算法的差异。
步骤
1)构建本次使用的数据集
2)将数据拆分成训练集和测试集
3)用4种算法分别建模、预测
代码环境
python版本:python3
1)如果不想被python各种安装包困扰,推荐Jupyter在线python,Jupyter官网,点击"Try Jupyter with Python",点击“+”号即可。安装包的时候直接pip install packages_name,例如pip install sklearn,点击“Run”,提示“Successfully installed sklearn-0.0”即安装完成。
2)Pycharm,专业、高效、强大的python开发端。
源码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets #built-in datasets
#make_moons,generated datasets
X,y = datasets.make_moons(n_samples=500,noise=0.3,random_state=42)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show() #plot for datasets
#split datasets for train and test part
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42)
#1.logistic regression model
from sklearn.linear_model import LogisticRegression
log_clf=LogisticRegression() #create LR classifer
log_clf.fit(X_train,y_train) #train and fit the model
log_score=log_clf.score(X_test,y_test) #test the model
#2.svm model
from sklearn.svm import SVC
svm_clf=SVC()
svm_clf.fit(X_train,y_train)
svm_score=svm_clf.score(X_test,y_test)
#3.decision tree model
from sklearn.tree import DecisionTreeClassifier
dt_clf=DecisionTreeClassifier()
dt_clf.fit(X_train,y_train)
dt_score=dt_clf.score(X_test,y_test)
#4.ensemble method
from sklearn.ensemble import VotingClassifier
voting_clf=VotingClassifier(estimators=
[('log_clf',LogisticRegression()),
('svm_clf',SVC()),
('dt_clf',DecisionTreeClassifier())
],voting="hard")
voting_clf.fit(X_train,y_train)
voting_score=voting_clf.score(X_test,y_test)
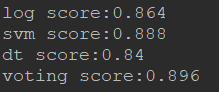
print("log score:%s"%log_score)
print("svm score:%s"%svm_score)
print("dt score:%s"%dt_score)
print("voting score:%s"%voting_score)
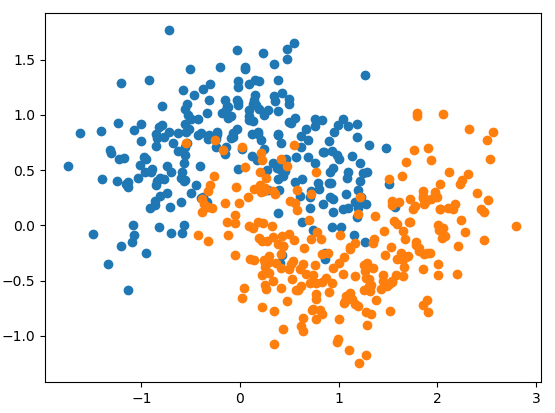
构建数据集:
 4种算法预测结果:
4种算法预测结果:
参考
机器学习中,有哪些特征选择的工程方法?
FeatureSlector:一个可以进行机器学习特征选择的python工具
机器学习中的交叉验证

















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









