






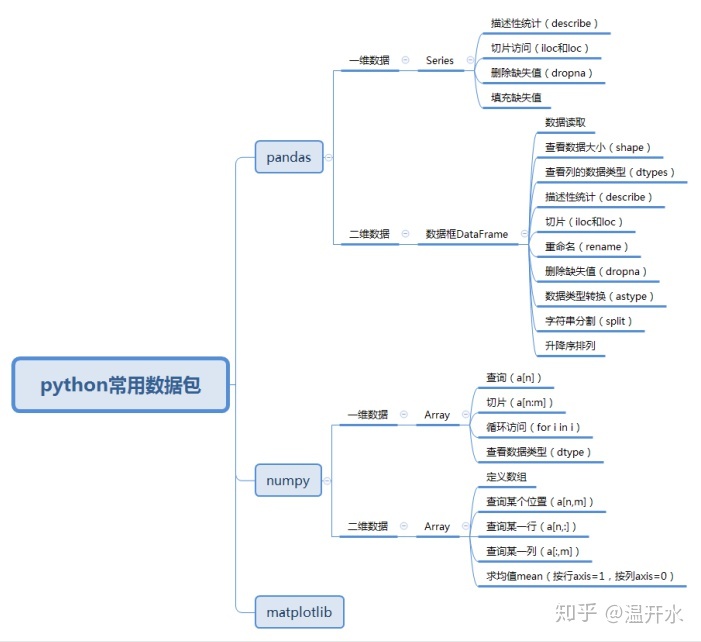
数据分析最常用到的三个包分别是:numpy、pandas和matplotlib,其中numpy用于数学计算,如线性代数中的矩阵计算,pandas是基于numpy的数据分析工具,能更方便的操作大型数据集,pandas中的DataFrame(数据框)方便对于数据表结构中的数据进行分析,matplotlib是专用于数据分析可视化的包。本章主要学习numpy和pandas的基础内容。
本章知识点汇总如下:
【一维数据】
一、Numpy(array)
1.1、数据包的导入及重命名

1.2、定义一维数组
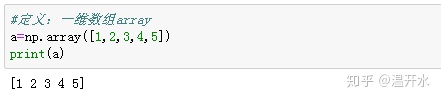
1.3、如何查询数组中的元素
访问数组中的元素时,采用方括号"[]"加想要获取元素所在的位置来获取,且第一个元素是从0开始,a[0]表示第1个元素,以此类推。

1.4、切片访问
当想要获取数组中某几个元素时,采用的冒号间隔的方式,且获取的元素时默认为前闭后开的方式,即a[1:3]表示获取数组中a[1]和a[2](第2和第3个元素),并不包含a[3](第4个)元素。

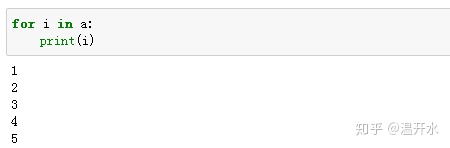
1.5、循环访问
循环访问数组中的每一个元素时采用for i in a 的方式
1.6、查看数据类型

二、Pandas(Series)
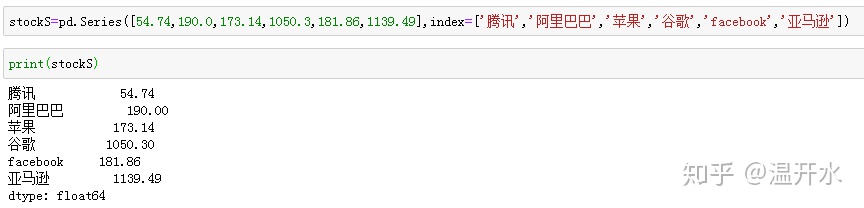
2.1、pandas定义一维数据
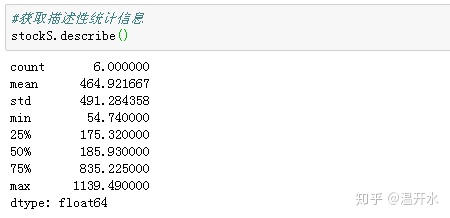
2.2、获取描述性统计信息(describe)
2.3、切片访问(iloc和loc)
iloc通过索引(位置)来获取值,loc通过名称来获取值。

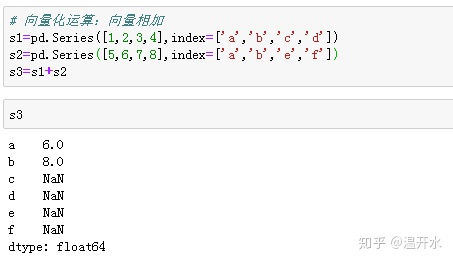
2.4、向量化运算:向量相加
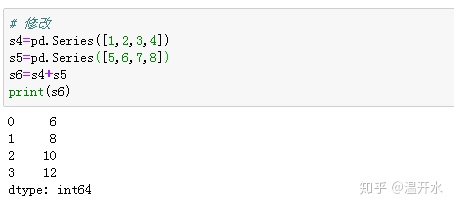
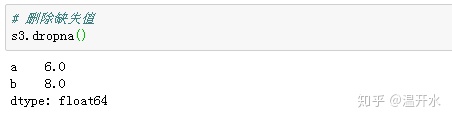
2.5、删除缺失值(dropna)
s3中的元素如下:
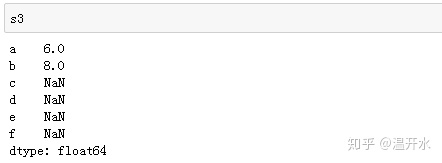
s3中存在缺失值,删除s3中的缺失值的方法:
2.6、填充缺失值

【二维数据】
三、Numpy(array)
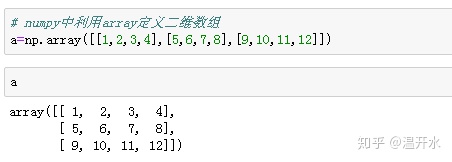
3.1、Numpy定义二维数组
3.2、查询元素

3.3、查询某一行或某一列所有元素

3.4、求平均值
axis=1按行计算每一行元素的均值,axis=0按列计算每一列元素的均值。

四、Pandas(DataFrame)
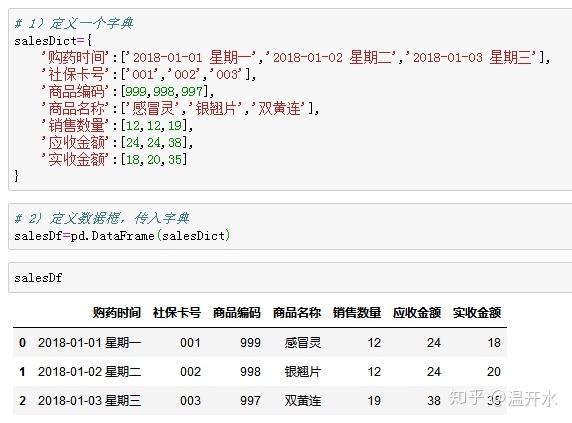
4.1、定义一个字典salesDict,将字典传入数据框salesDf
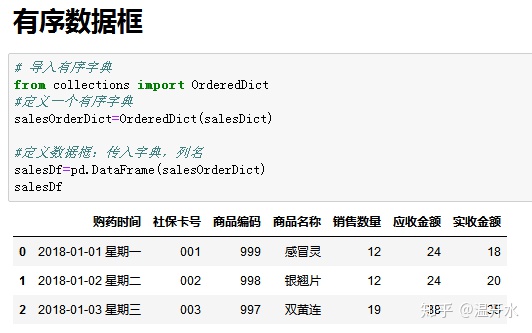
4.2、有序数据框
4.3、平均值

4.4、查询——iloc和loc
iloc查询代码:

loc查询代码:

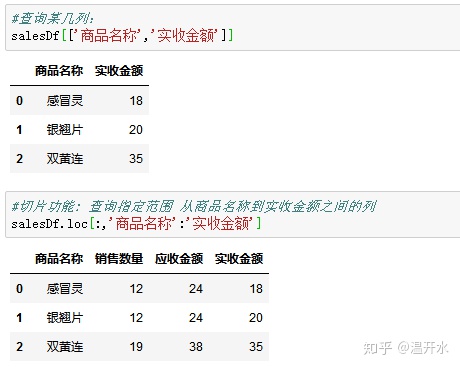
4.5、查询某几列
4.6、通过条件判断筛选
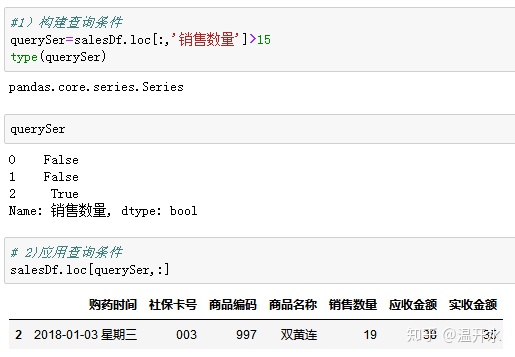
五、数据分析实践案例
数据分析基本过程:①提出问题,②理解数据需求 ,③数据清洗, ④构建模型 。⑤数据可视化;
数据清洗的基本过程:①选择子集,②列名重命名,③缺失数据处理,④数据类型转换,⑤数据排序,⑥异常值处理。
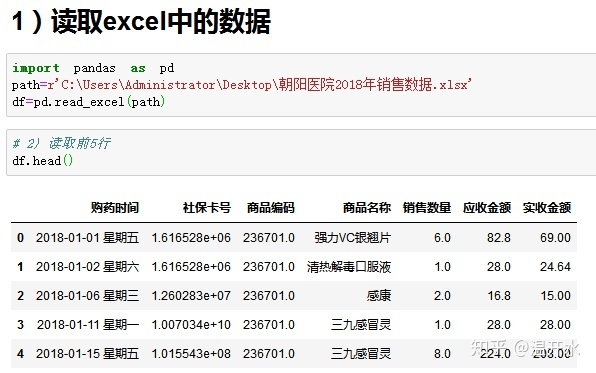
5.1、读取excel中的数据
5.2、查看数据大小(shape)

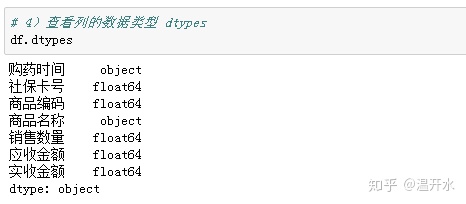
5.3、查看列的数据类型(dtypes)
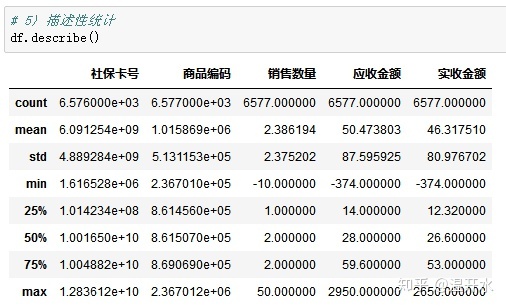
5.4、描述性统计
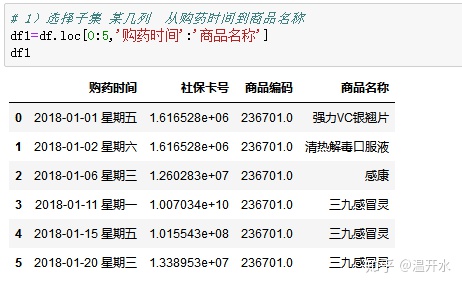
5.5、查看某几列内容
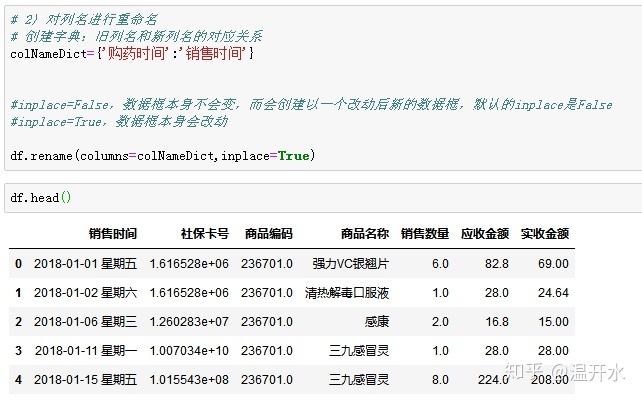
5.6、重命名(rename)
5.7、缺失值处理

5.8、数据类型转换(astype)

5.9、字符串分割(split)
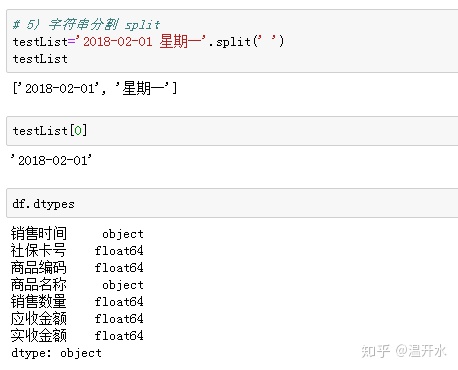
对数据集中的购药时间(2018-01-01 星期五)以空格进行分列得到只有日期的结果:
定义分割函数splitSalestime,对购药时间进行分列:
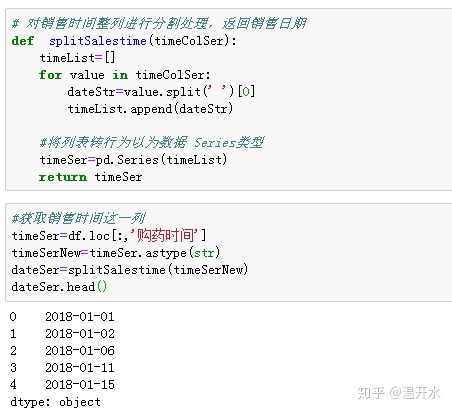
5.9.1、将分割后的销售日期重新赋值给新的列名销售日期5.9.2
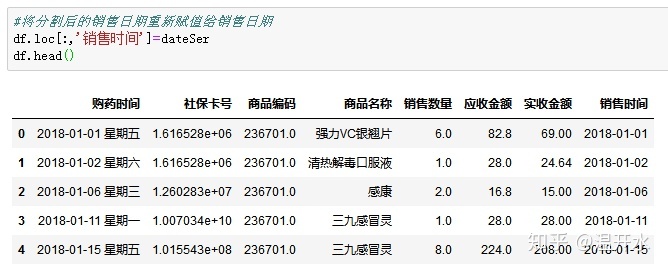
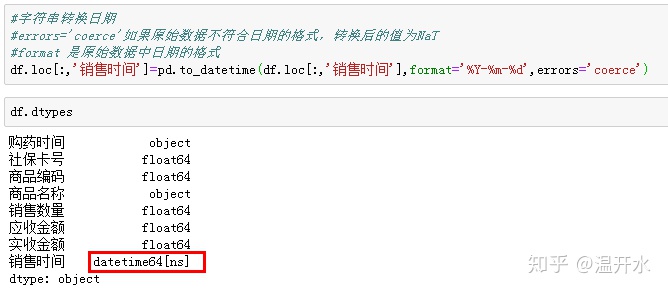
5.10、将字符串类型转换为日期格式(to_datetime)
5.11、排序(sort_values,ascending=True表示升序,ascending=False表示降序)

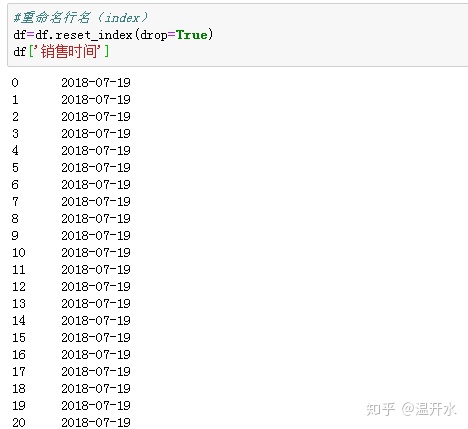
但是排序后的行号依然是之前的索引值,重新修改行名(index)
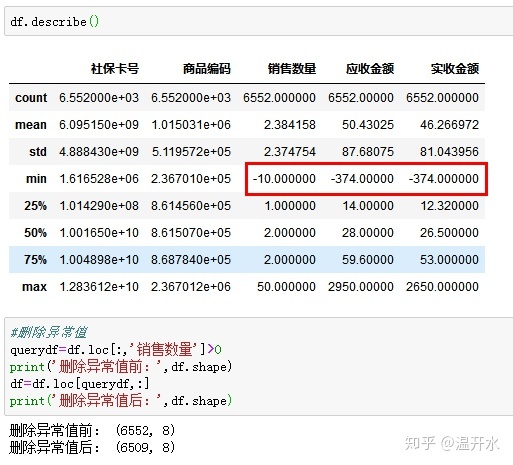
5.12、删除异常值
对df做描述性统计发现销售数量出现负值(异常),对异常值进行删除处理如下:
第二步:构建模型(理解业务指标的含义,并清楚数据计算统计口径)
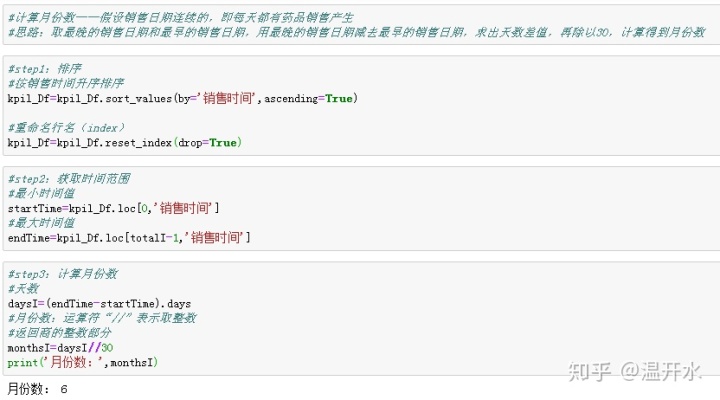
指标1:月均消费次数=总消费次数/月份数,其中总消费次数计算时,同一天内,同一个人发生的所有消费算作一次消费
总消费次数:

月份数:
月均消费次数:

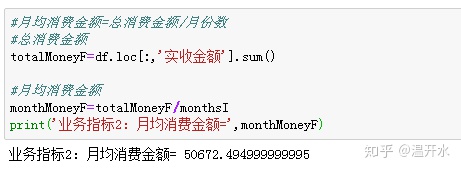
指标2:月均消费金额=总消费金额/月份数
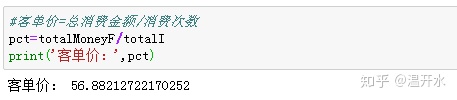
指标3:客单价=总消费金额/总消费次数














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









