





前段时间阅读了一篇名为《[Python]网络爬虫(八):糗事百科的网络爬虫(v0.3)源码及解析(简化更新) 》的博客,基于Python2.7编写,我用Python3将其重构,在前几篇内容的基础上加入了多线程并且用类实现。以下是程序源代码,并对源代码进行解读:
#!/usr/bin/env python3
import queue
import urllib.request as request
import re
import threading
import socket
import time
import urllib.error
class SpiderModel:
def __init__(self):
socket.setdefaulttimeout(5)
self.queue_url=queue.Queue()
self.queue_text=queue.Queue()
myUrl = "http://www.qiushibaike.com"
self.queue_url.put(myUrl)
self.visited=set()
#从url队列中取出一个url,放如已访问
def Get_Page(self):
#弹出一个队列元素,加入已访问set中
#取出该url指向的数据,String
myUrl=self.queue_url.get()
self.visited |={myUrl}
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = request.Request(myUrl, headers = headers)
time.sleep(2)
try:
myResponse = request.urlopen(req,timeout=3)
except:
print('urlopen出问题了')#对于Timeout问题我真的是无语了,查了很多资料也没得到结果
try:
myPage = myResponse.read()
except:
print('urllib request read出问题了')
unicodePage = myPage.decode("utf-8",'ignore')
return unicodePage
def Get_Text(self):
while True:
PageString=self.Get_Page()
#获取每个页面的所有url链接,放入队列queue_url
linkre = re.compile('href=\"(.+?)\"')
for x in linkre.findall(PageString):
if 'http' in x and x not in self.visited:
self.queue_url.put(x)
#print(x)
#获取每个页面的文章内容,放入队列queue_text中
myItems = re.findall('
(.*?)',PageString,re.S)for item in myItems:
self.queue_text.put(item[0]+item[1])
#print(item[0]+item[1])
def Show_Text(self):
while self.queue_text.not_empty:
text_one=self.queue_text.get()
print(text_one)
def Start(self):
print ('正在加载中请稍候......' )
threads=[]#创建线程列表,用于存放需要执行的子线程
threading.Thread(target=self.Get_Text).start()
threading.Thread(target=self.Show_Text).start()
#----------- 程序的入口处 --------------#
print ("""
---------------------------------------
程序:糗百爬虫
版本:1.0
作者:baluw
日期:2015-04-04
语言:Python 3.4
功能:抓取糗事百科,同步显示
---------------------------------------
""" )
print ('请按下回车浏览今日的糗百内容:' )
input(' ')
myModel = SpiderModel()
myModel.Start()
#--------------程序入口-----------------#
程序创建了两个队列(queue)queue_url和queue_text分别存储抓取的网站网址和捕获的文本,一个集合(set)存储已访问的网站。关于利用正则表达式活取URL链接和网站文本内容,在前面文章中也已经介绍了,如果有疑问,可查看前面内容。
最主要的内容,在Start()这个函数,创建两个线程,一个线程活取url和文本并存入队列,另一个线程同步显示已经活取的内容。
但是系统存在问题,一直没法解决,运行了几秒钟,小程序就挂掉了。
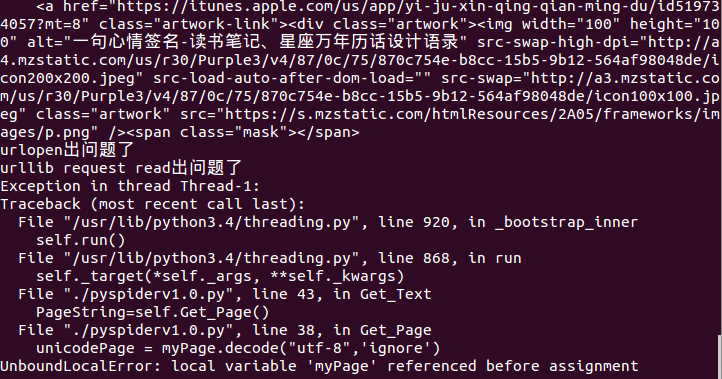















 3360
3360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









