





Python Selenium实例之自动填写调查问卷和获取网易云歌单信息
一、自动填写问卷
调查问卷网址
问卷星是一个使用率很高的问卷调查网站,在问卷星贴吧有很多调查问卷的链接。https://www.wjx.cn/jq/89038106.aspx
实例化一个浏览器对象,并访问目标网站
from selenium.webdriver import Chrome
import random # 后面随机选择答案
#没有添加无头参数
webdriver = Chrome(executable_path=r"E:\python学习\python爬虫\chromedriver.exe")
webdriver.get(url)
解析网页结构
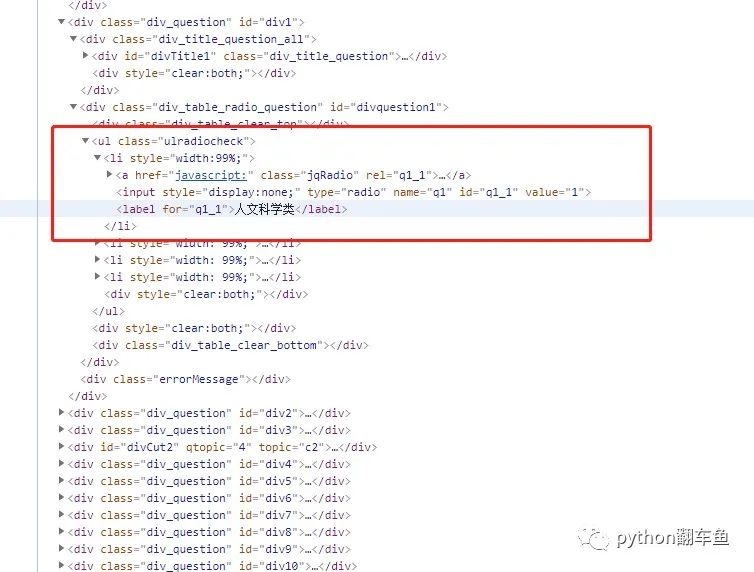
根据网页html节点,使用xpath查找自己需要的信息。
# 将特殊问题的答案保存为列表,通过列表索引随机取值
subject_list=['人文科学类','社会科学类','自然科学类','工程技术类']
num = random.randint(1, 3)
#找到网页中文本为列表中值的label节点,再找同级的a节点,然后再点击
ele = webdriver.find_element_by_xpath(f"//label[text()='{subject_list[num]}']/preceding-sibling::a")
#选中
ele.click()
grade_list = ['大一','大二','大三','大四','硕士生','博士生']
num = random.randint(1, 6)
ele = webdriver.find_element_by_xpath(f"//label[text()='{grade_list[num]}']/preceding-sibling::a")
ele.click()
# 找到所有问题的ul节点(切掉前两个特殊的问题)
eles = webdriver.find_elements_by_xpath("//ul[@class='ulradiocheck']")[2:]
for ele in eles:
num = random.randint(1,5)
a_ele = ele.find_element_by_xpath("./li[{}]/a".format(num))
a_ele.click()
# 找到每个选项下的label节点,获取label节点的文本和属性
label_ele = ele.find_element_by_xpath("./li[{}]/label".format(num))
print(label_ele.text, label_ele.get_attribute("for"))
# 后面的多选,选项也超过了五个,我当单选处理了。
# 找到提交按钮,点击提交,下面三行先注释可以看到结果
# 提交数据
ele = webdriver.find_element_by_id("submit_button")
ele.click()
# 关闭网页
webdriver.close()
二、网易云歌单信息获取
实例化浏览器对象,并访问目标网页
from selenium.webdriver import Chrome
# 实例化一个浏览器对象
webdriver = Chrome(executable_path=r"E:\python学习\python爬虫\chromedriver.exe")
# 访问目标网页
webdriver.get("https://music.163.com/#/discover/playlist/")
输入想要获取的页数
pages = int(input("请输入要爬取的页数: "))
切换iframe
该网页里面有iframe标签,里面有嵌套一个网页。因此在提取信息前,需要切换iframe,可以传索引,也可以传iframe的id,只用切换一次,不需要每次for循环翻页都去切换。
webdriver.switch_to.frame('g_iframe')
获取信息
# 翻页有两种方法:1.找url的规律,修改url
# 2.模拟点击下一页(我们这里使用的)
for _ in range(pages):
# 解析网页结构,找到页面中所有歌单的li节点列表
nodes = webdriver.find_elements_by_xpath('//ul[@id="m-pl-container"]/li')
print(len(nodes))
for node in nodes: # node是每个歌单的li节点
song_name = node.find_element_by_xpath("./p[1]/a").text # 找歌单名称
author_name = node.find_element_by_xpath("./p[2]/a").get_attribute("title") # 找作者名称
print(song_name, author_name)
# 找到下一页的a节点,模拟点击
next_node = webdriver.find_element_by_link_text('下一页')
next_node.click()















 1971
1971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









