






C语言系列
一.链表定义
1).引
1.什么是链表
2.为什么要引入链表
3.链表有什么用
4.单向表(带头)优点
2).链表涉及的基本概念
1.头指针
2.头节点;
3.链表存在:
4.链表空:
5.链表尾:
6.带头节点链表,无头节点链表
7.单链表, 双链表,循环链表
3).代码书写
一个普通链表代码
头插法
尾插法
二.链表的创建
头插法
尾插法
三.链表操作
1.创建
2.输入
3.输出
4.查找
5.修改
6.插入,删除
插入
删除
一.链表定义
1).引
1.什么是链表
一串 被 连在一起 的内存空间(链式内存)
2.为什么要引入链表
解决内存不够存放一串连续数据问题
Ps:一般来说,数组能解决大多数问题,但是数组要求开辟一块连续完整的内存空间,使其能够连续存放,对内存空间要求苛刻。若内存不够时,链表的作用便体现出来
链表能够充分利用零碎空间
3.链表有什么用
解决空间不足,但要连续储存问题
4.单向表(带头)优点
将表无数据的判断和表处理结束表尾的判断 形式上做了统一。
2).链表涉及的基本概念
1.头指针
指向(记录)链式存储中第1个节点位置(地址)的指针变量。简称为头指针;
2.头节点;
顾名思义,代表链式存储中一个特殊节点;领头的节点,领队节点;可以有,也可以没有。
3.链表存在:
有头节点的链表,链表存在表明至少头节点是存在的;没有头节点的,那p的内容应该存在且有意义;若P为NULL则表明不存在;
4.链表空:
是指链表数据部分不存在。有头节点的,链表为空,表明链表只有头节点;无头节点的,显然P为NULL;
5.链表尾:
指链表中最后一个节点,称为链表的尾节点。
6.带头节点链表,无头节点链表
有头指针和无头指针的区别
7.单链表, 双链表,循环链表
单链表:只有后继关系
双链表:有后继和前驱关系
循环链表:尾节点又指向的第一个节点
3).代码书写
既然要连起来,那必然有一个扣和一个环,且环和扣得在一起,类似于火车车厢
因此,这里的
int data;就是环
struct Link *next;就是扣
struct Link
{
int data;//记录数据
struct Link *next;//记录位置关系,利用递归的方式
};
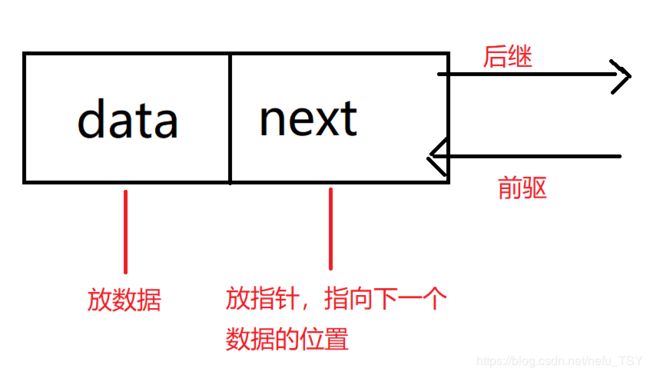
Q:怎么连起来?
A:用指针
Q:为什么用结构体?
A:结构体能整合不同的数据类型
Q:为什么要用struct Link定义指针
A:因为每一个节点必须是一样的,用struct Link来递归,指向下一个节点
Ps:个人见解,当程序执行到struct Link *next;这一行时,就已经开辟了一个和自己一样的节点。
这是一个套娃。
C语言支持指针的递归。
一个普通链表代码
头插法
#include
#include
#include
struct Link
{
int data;
struct Link *next;
};
int main()
{
int i,n;
struct Link *p,*q;
scanf("%d",&n);
p=(struct Link *)malloc(sizeof(struct Link));
p->next=NULL;
for(i=0;i
{
q=(struct Link *)malloc(sizeof(struct Link));
scanf("%d",&q->data);
//q->next=NULL;//因为是接到头节点后,所以空不空都行
q->next=p->next;//把环记下来(保留原有关系)
p->next=q;//指向下一个数据
}
q=p->next
while(q!=NULL)
{
printf("%d",q->data);
q=q->next;
}
return 0;
}
当一个数据输入时,指针q[0]的next=头指针的next,然后头指针的next指向了q[0]的数据
下一个数据输入时,指针q[1]的next=头指针的next,然后头指针的next指向了q[1]的数据。
Q:为什么是倒序的
A:因为头指针的next已经指向了q[0]的数据,当指针q[1]的next=头指针的next时,头指针的next已经记录了q[0]的数据,所以指针q[1]的next=头指针的next后,q[0]就接在了q[1]的后面
尾插法
#include
#include
#include
struct Link
{
int data;
struct Link * next;
};
int main()
{
int i,n;
struct Link *p,*q,*r;
scanf("%d",&n);
p=r=(struct Link *)malloc(sizeof(struct Link));
p->next=NULL;
for(i=0;i
{
q=(struct Link *)malloc(sizeof(struct Link));
scanf("%d",&q->data);
q->next=NULL;
r->next=q;//新建一个节点,充当胶水,先给要接入的环抹上。
r=r->next;//然后移动r到下一个节点,黏上
//这里的r,先让其next指向q的数据,然后挪动r,完成对接
}
q=p->next;
while(q!=NULL)
{
printf("%d",q->data);
q=q->next;
}
return 0;
}
Q:怎么理解
A:新建一个临时节点,当数组输入时,让r的next指向q,再让r移动到其next,也就指向了q,所以r的next也就是q的next。当输入下一个时,r->next=q这里的next是上一个q 的next
Q:头指针没用了吗?
A:相当于,另起一个串,这个串串好了,然后才连到头指针上
以下以单向有头链表举例
以动态链表为例
二.链表的创建
头插法
顾名思义,输入的数据是接在头指针的后面,每一个都找头指针对接(扣环)
解释,见上。
输入的数据是倒序的,见上。
尾插法
按节点顺序生成
新节点接在上一个节点的后面,而不是头指针的后面
相关解释,见上。
三.链表操作
1.创建
struct Link
{
int data;
struct Link * next;
};
2.输入
头插和尾插,见上
3.输出
q=p->next;
while(q!=NULL)
{
printf("%d",q->data);
q=q->next;
}
4.查找
目的是找到要求的数据
查找区间在[1,n]之间
找不到返回NULL,找到返回相应指针
struct Link * search(struct Link*p,int n)
{
int i;
struct Link *q;
while(i
{
i++;
q=q->next;
}
if(i!=n)
return NULL;
else
return q;
}
5.修改
给出要修改节点的位置,对应修改即可
这里为了防止手误修改,记录了修改前的内容
struct Link modify(struct Link*p,struct Link y)
{
int i;
struct Link t;
t=*q;
*q=y;
q->next=t->next;
return t;//返回的就是未修改前的内容
}
6.插入,删除
插入和删除,都需要找到要插入或者删除的前一个节点,修改前一个节点的next
插入的节点区间是[0,n+1]
删除的节点区间是[1,n]
插入
必须维护原有的关系,所以要记录原有的关系,再进行插入
因为要找到前一个节点的位置,所以区间是[0,n]
插入点的前驱节点不能为空
采用计数原理,找到要修改的位置
void insert(struct Link *p,struct Link *q,int i)
{
int j=0;
struct Link *r;
r=p;//新建一个链表,用链表找
while(j
{
j++;
r=r->next;
}
if(r!=NULL)//如果找到了
{
//先保留关系
q->next=r->next;//插入节点得和上一个节点的next相等
//在此,新节点的next就把后面的剩余节点保存下来了
//再赋值
r->next=q;//让上一个节点的next指向新节点的值
}
}
删除
同插入
要找到前一个节点的位置,所以区间是[0,n-1]
另外,待删除的节点也不能为空
同样,这里为了防止手误删除,记录了为删除的数据
void delete1(struct Link *p,int i)
{
int j=0;
struct Link *r,*q,t;
r=p;//新建一个链表,用链表找
while(jnext!=NULL)
{
j++;
r=r->next;
}
q=r->next;//找到待删除节点
if(q!=NULL)//如果待删除节点不为空
{
//先保留关系
t=*q;//保留历史记录
//只需将待删除节点的next与上一个节点的next对接上,待删除节点就会被跳过
//也就是完成了删除
r->next=q->next;//完成对接
//这里的q就是待删除节点,让r.next等于待删除节点q.next,就把该节点的数据跳过了
}
free(q);//清除q
return t;
}
写在最后,如果没看懂的,建议动手画一画就明白了~
点赞呀~















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









