



 本文介绍了贝壳采集器,一个无需编程的Chrome插件,用于网页数据提取。通过可视化操作,用户能轻松抓取定制区域的数据,实现自动化提取。文章详细描述了如何使用该工具从烯牛数据网站提取人工智能公司的信息,包括登录、配置和采集步骤,强调其在简单页面内容提取中的实用性。
本文介绍了贝壳采集器,一个无需编程的Chrome插件,用于网页数据提取。通过可视化操作,用户能轻松抓取定制区域的数据,实现自动化提取。文章详细描述了如何使用该工具从烯牛数据网站提取人工智能公司的信息,包括登录、配置和采集步骤,强调其在简单页面内容提取中的实用性。
想分享的这款工具是个Chrome下的插件叫:贝壳采集器
贝壳采集器是一款可以从网页中提取数据的Chrome网页数据提取插件。在某种意义上,你也可以把它当做一个爬虫工具。
也是因为最近在梳理36氪文章一些标签,打算看下别家和创投相关的网站有什么标准可以参考,于是发现一家名叫:“烯牛数据”的网站,想看下人工智能的公司,如下图红字部分:
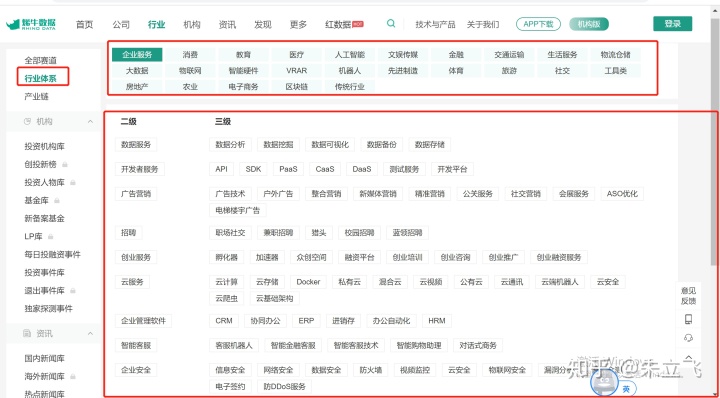
如果是规则展示的数据,还能用鼠标选择后复制粘贴,但这种嵌入页面中的,还是要想些办法。这时想起之前安装过贝壳采集器,就用下试试,还挺好用的,一下子提高了收集效率。也给大家安利下~
贝壳采集器这个Chrome插件,我是在B站科技视频上看到的,号称不用懂编程也能实现爬虫抓取的黑科技。简单来说,贝壳采集器是个基于Chrome的网页元素解析器,自动化识别主体内容,可以通过可视化点选操作,实现某个定制区域的数据/元素提取。同时它也提供定时自动提取功能,活用这个功能就可以当做一套简单的爬虫工具来用了。
这里再顺便解释下网页提取器抓取和真正代码编写爬虫的区别,用网页提取器自动提取页面数据的过程,有点类似模拟人工点击的机器人,它是先让你定义好页面上要抓哪个元素,以及要抓哪些页面,然后让机器去替人来操作;而如果你用Python写爬虫,更多是利用网页请求指令先把整个网页下载下来,再用代码去解析HTML页面元素,提取其中你想要的内容,再不断循环。相比而言,用代码会更灵活,但解析成本也会更高,如果是简单的页面内容提取,我也是建议用贝壳采集器就够了。
关于贝壳采集器的具体安装过程,以及完整功能的使用方法,我不会在今天的文章里展开说。第一是我只使用了我需要的部分,第二也是因为市面上讲贝壳采集器的教程很丰富,大家完全可以自行查找。
这里只以一个实操过程,给大家简单介绍下我是怎么用的。
第一步 登录贝壳采集平台后台
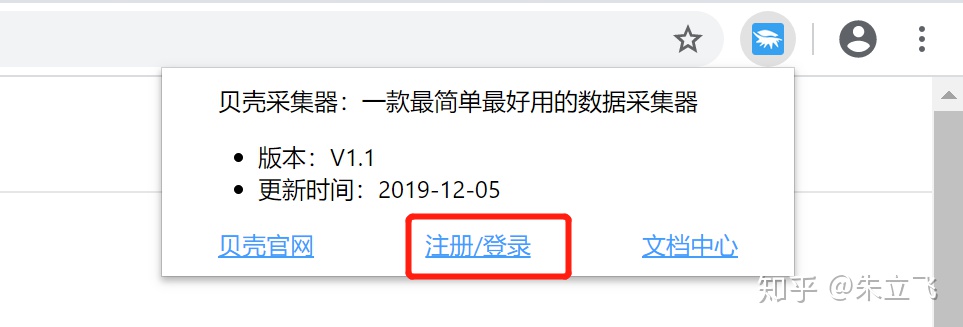
1. 打开Chrome浏览器,在浏览器中右上角会出现其图标按钮标记。点击该按钮注册/登录按钮跳转到贝壳采集平台后台登录页,输入用户名密码登录后就能使用了
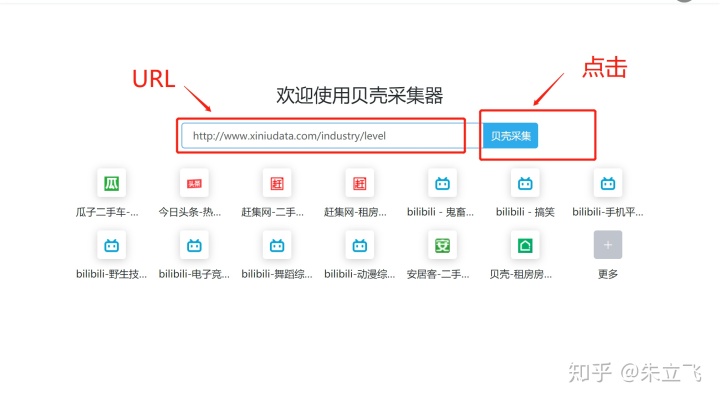
首先输入你想抓取的网站URL,比如我想抓取的是:烯牛数据的行业标签,URL是:http://www.xiniudata.com/industry/level,然后在贝壳采集器后台输入URL点击贝壳采集按钮就会出现配置页了
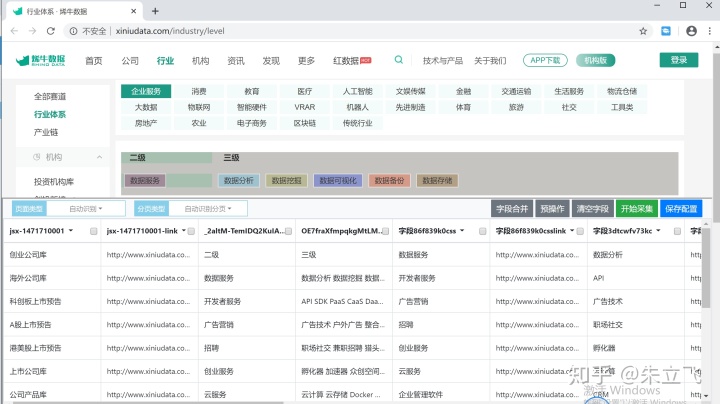
识别出了主体内容 但是我想要的是人工智能下边的公司,所以需要重新配置下。
第二步 配置需要提取的大类信息
1. 首先点击清空字段按钮先清空所有数据,
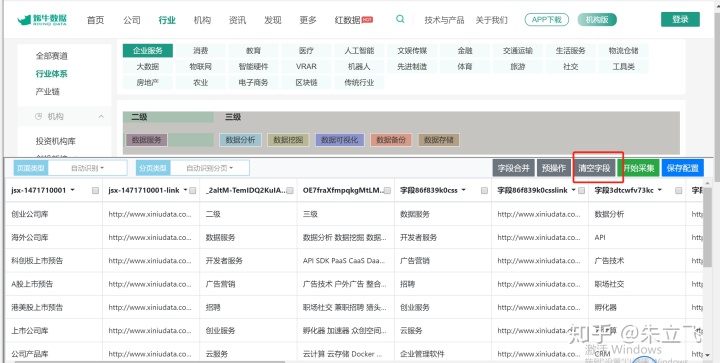
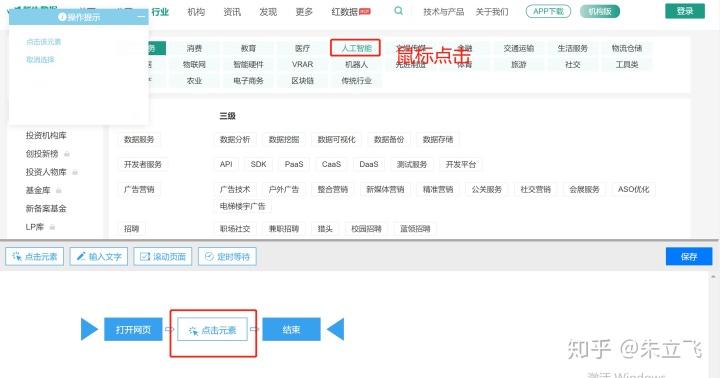
2. 执行预操作,点击人工智能标签,然后保存预操作
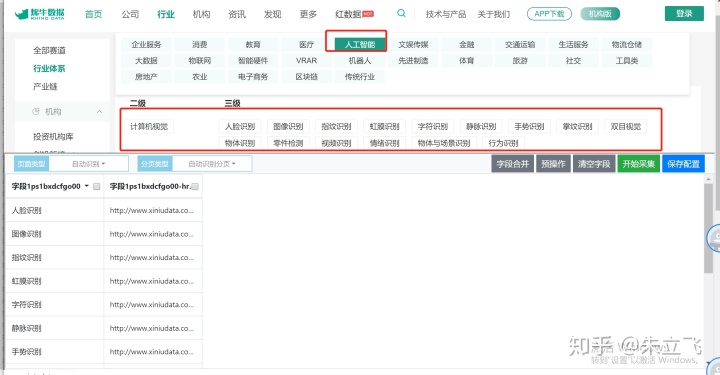
点击提取到的连接提取公司的详情
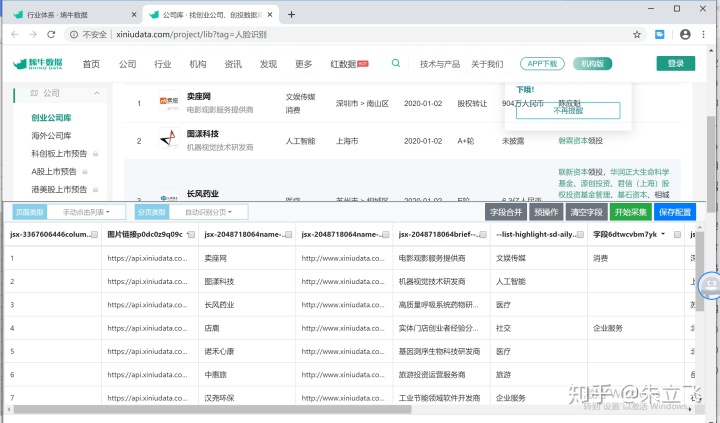
第三步 开始采集
完成基础配置的创建后,点击开始采集按钮,就开始采集数据了,你还可以直接看到数据采集的过程,嫌慢的话那就点击立即加速。
以上就是对贝壳采集器使用过程的简单介绍。这篇文章主要是想和你普及下这款工具,不算教程,更多功能还是要根据你的需求自行摸索~
怎么样,是否有帮到你?贝壳采集器还有大量的采集模板免费使用哟。。。

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









