






提前说明一下,大数据的搭建环境都是在Linux系统下构建,可能针对一些没有Linux编程基础的同学来说会有一些吃力,请各位客官放心,小店伙计后期会专门有几期来讲解Linux编程基础。绝对保证零基础完成大数据环境的构建。今天大数据环境构建后会暂停其他组件(hue、flume、kafka、oozie等)的构建,后面的文章就是基于该环境讲解大数据的应用。
一
安装zookeeper
参考:大数据开发|Hadoop分布式集群环境构建(1)
二
安装spark

2.2
安装scala
spark的底层是基于scala语言编写,对于spark的计算程序也可以通过scala语言来编写。
并解压scala:
tar -zxvf scala-2.10.4.tar.gz

2.3
spark安装配置
下载spark安装包
并解压:tar -zxvf spark-1.5.0-cdh5.5.1.tar.gz
如果你对大数据开发感兴趣,想系统学习大数据的话,可以戳我加入大数据技术学习交流群,私信管理员即可免费领取开发工具以及入门学习资料
配置spark-env.sh
内容如下:
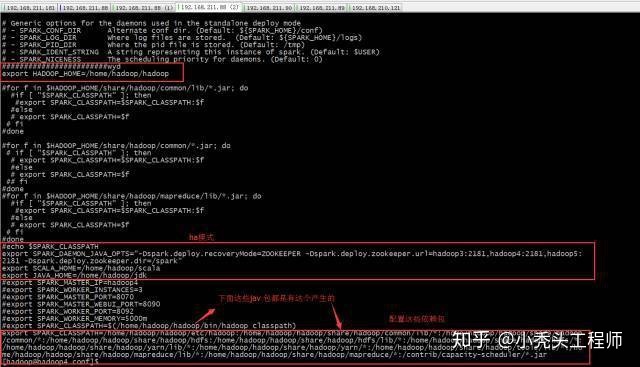
export SPARK_CLASSPATH=/home/hadoop/hadoop/etc/hadoop:/home/hadoop/hadoop/share/hadoop/common/lib/*:/home/hadoop/hadoop/share/hadoop/common/*:/home/hadoop/hadoop/share/hadoop/hdfs:/home/hadoop/hadoop/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop/share/hadoop/hdfs/*:/home/hadoop/hadoop/share/hadoop/yarn/lib/*:/home/hadoop/hadoop/share/hadoop/yarn/*:/home/hadoop/hadoop/share/hadoop/tools/lib/*:/home/hadoop/hadoop/share/hadoop/mapreduce/lib/*:/home/hadoop/hadoop/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop3:2181,hadoop4:2181,hadoop5:2181 -Dspark.deploy.zookeeper.dir=/spark"
export SCALA_HOME=/home/hadoop/scala
export JAVA_HOME=/home/hadoop/jdk
export HADOOP_HOME=/home/hadoop/hadoop
配置slaves
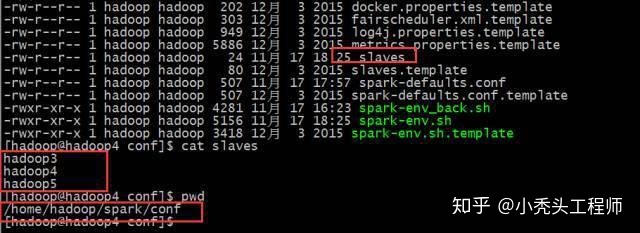
2.4
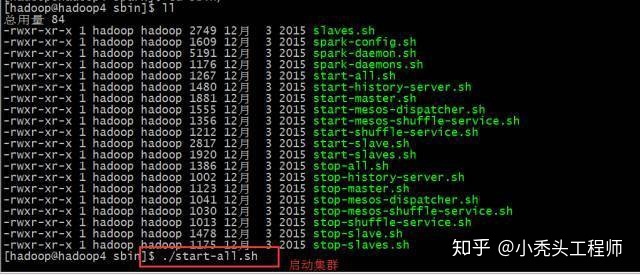
启动集群
./start-all.sh
结果
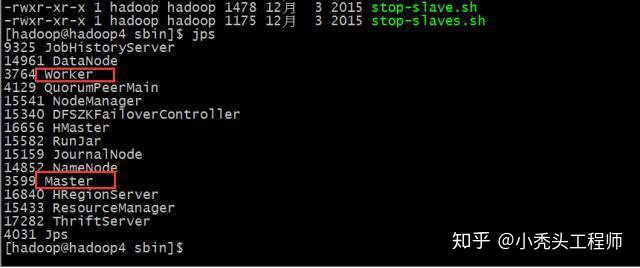
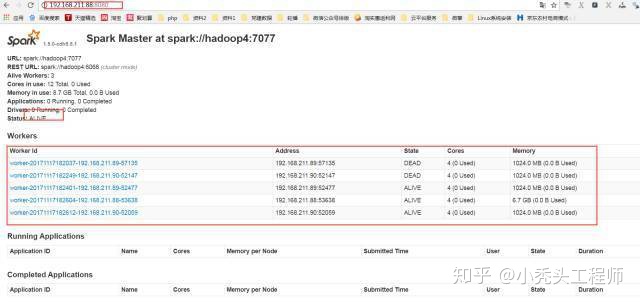
因为采用的是HA模式
就需要在备用机子上启动master
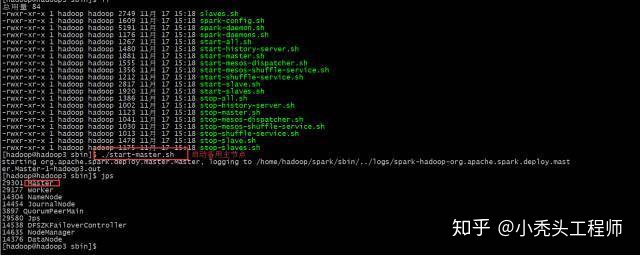
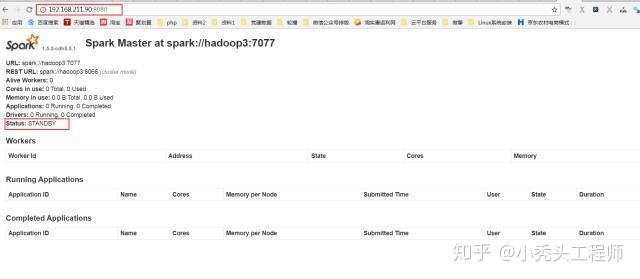
至此spark HA集群就搭建成功了
三
测试
./spark-shell
例子:
统计文字的长度
代码:
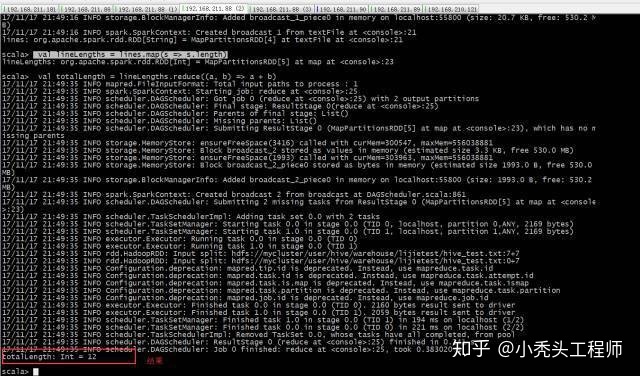
val lines = sc.textFile("hdfs://mycluster/user/hive/warehouse/lijietest/hive_test.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b)
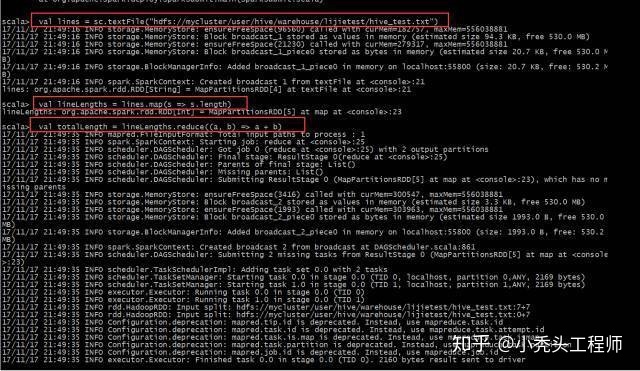
运行结果:















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









