






前言
分布式系统领域里总共有三大块:存储、计算和通信。之前的Redis的系列相当于分布式存储的一个案例研究,研究了两个月之后自己从中受益匪浅。所以也想从这篇文章开始再开一个分布式计算框架的研究系列。刚好最近在同时上我校的分布式系统课程和MIT6.824, 两个课程的Lab1都是MapReduce实现,所以借此机会也尝试研究一下MapReduce。这篇文章假定读者对MapReduce有基本的认识,不会去介绍MR的基础概念,同时本篇不研究如何使用Hadoop来进行编程, 更专注于如何开发一个类似于Hadoop的分布式计算系统。当然了,这么大的问题不可能被我一周研究明白,也不可能在一篇文章中说清楚。本次系列地文章大概会写三篇。第一篇介绍MR中地执行地整体流程。第二篇介绍MRAppMaster、MapTask和ReduceTask的执行细节。第三章介绍FalutTolerence以及其他的一些问题。本篇文章主要是源码阅读了,Hadoop的源码本身比较庞大。希望这篇博客对大家读MR相关部分的代码能有些帮助。
同时还是比较推荐MIT6.824课程的, 我看B站上有人搬运了课程视频。这里放给大家连接,大家可以去学习。
https://www.bilibili.com/video/av87684880?p=4www.bilibili.comMapReduce总览介绍
一、《MapReduce: Simplified Data Processing on Large Clusters》概要介绍
MapReduce把并行、容错、负载均衡以及数据分布的细节隐藏了起来,提升了用户的使用友好性,进而得到了广泛的使用。下面这张图整体描述了MapReduce的流程,想必大家都不陌生。我们首先引用MR的原文来概述每一步都发生了什么。强烈建议大家仔细读一下下面的内容,对整体了解MR的工作流程非常有好处。
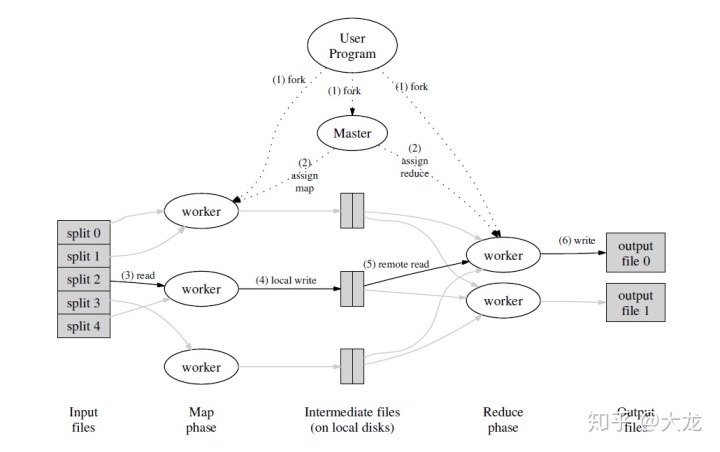
1. The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (controllable by the user via an optional parameter). It then starts up many copies of the program on a cluster of machines.
2. One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.
3. A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory.
4. Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
5. When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used.
6. The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
7. When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user program returns back to the user code.
二、MapReduce整体架构介绍
在Yarn引入之后,MR的架构变得复杂了许多,整体结构即工作流程如下图。原本1.0中JobTracker的功能被分成了资源管理和任务管理两部分。资源管理由ResourceManager管理,任务管理由MRAppMaster负责。MapTask/ReduceTask 和MRAppMaster都运行在容器(Container)中,而Containter的启动和管理都由NodeManager来负责。
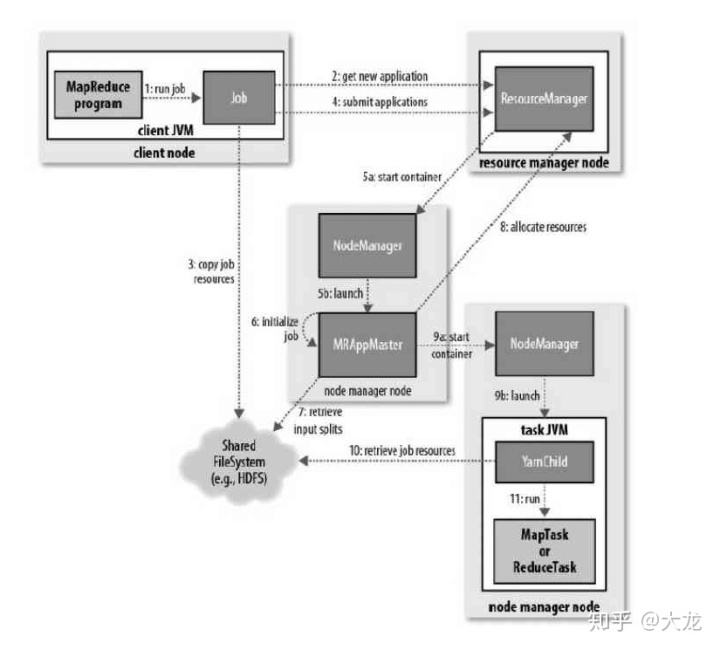
图中描述了启动一个Job流程的11步。我们重点介绍作业初始化部分,即从第五步开始的过程。在2.0版本之后,作业的初始化细化为了两个部分,分别为过程5a和5b。由上面所说的任务提交申请资源调用,将其请求给调度器处理,可以看到,调度器分配Container,同时在管理节点上启动一个ApplicationMaster进程。Application Master的主要执行者 MRAppMaster会初始化一定数量的记录对象来跟踪Job的运行进度,并收取task的进度和完成情况(过程6)。此时Master会决定如何组织运行MapReduce Job。如果Job很小,能在同一个JVM和同一个Node运行的话,则用uber模式运行。
对于运行任务的分配,如果不再uber模式下运行,则AppMaster会为所有的Map和Reduce Task向RM请求Container。 所有的请求都通过heartbeat传递。心跳中也传递其他信息,例如关于Map数据本地化的信息、分片所在的主机和机架地址信息等。这些信息帮助调度器做出调度的决策,调度器尽可能地遵循数据本地化或者机架本地化地原则分配Container。
而对于任务地执行来说,分配给Task任务Container后,NodeManager上地Application Master就启动Container, 最后Task被一个称为“YarnChild”地main类执行。不过在此之前,各个资源文件已经从分布式缓存拷贝下来,这样才能运行MapTask或者ReduceTask。
对于进程和状态地更新,当Yarn运行时,Task和Container会将他们地进度和状态报告给AppMaster。如下图所示:
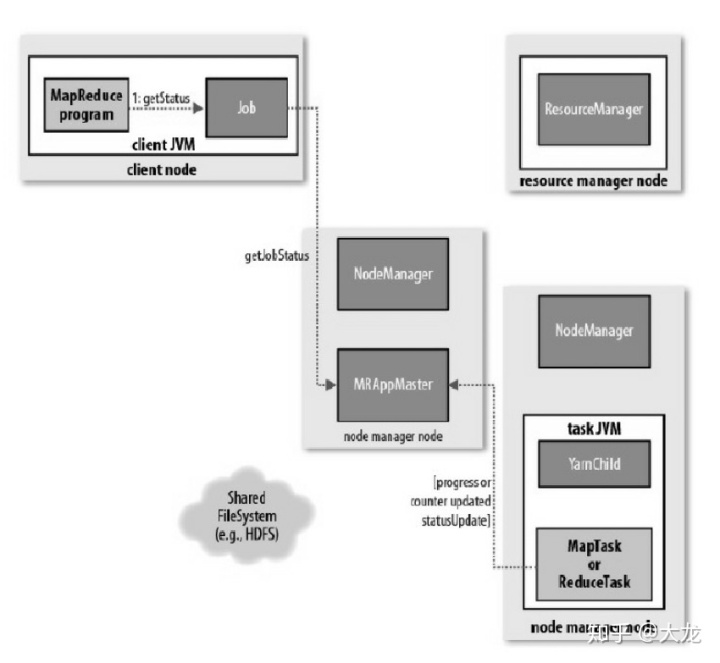
接下来我们按照执行的流程去看每一步都发生了什么。
Split数据
我们知道MapReduce是依赖分布式文件系统的(HDFS或GFS)的。当我们提交任务的时候,MR首先把整个数据逻辑切分成一个个的split。一定注意这里是逻辑切分,并不是真正的物理切分。切分后的split是什么样呢?我们以FileSplit为例进行展示。
// 一个FileSplit主要包含文件路径、该Split的数据开始部分在该文件中的偏移以及该Split的长度
假如我们把一个64G的文件word_count.txt分割为1024个split,即每个split大小是64M。那么第1个Split和第2个Split的参数如下:
// 第一个Split
当一个worker拿到这样一个Split,就可以根据Split中的信息从HDFS中去直接读取数据了。Split懂了之后,Split的分割就很容易懂了,话不多说,直接放代码。需要提一句的是splitSize大小的计算。从计算公式中我们也可以看出splitSize最小为minSize(一般16M),最大为blockSize(一般为64M)。所以这也是为什么原文说每个splitSize在16-64M之间了。
// 分布式文件系统中的blocksize, 如GFS中为64M
YarnChild
当NodeManager启动一个Container运行YarnChild时,首先不断尝试从AppMaster中获取一个Task直到获取成功。获取后再进行一些Task的环境信息的设置后,调用Task.run()函数开始执行该Task。
class Task
Task主要有两种, ReduceTask和MapTask,这两种Task都继承了Task基类。Task中保存了任务的状态信息,同时还实现了一个YarnChild中调用的run()方法来启动执行task。我们接下来以MapTask为例进行介绍。
初始化一个MapTask,需要JobFile路径、 这个Task的ID、reduceTask的数目以及分配给这个mapTask的Split数据相关信息。
public splitIndex里面包含的是该MapTask执行所需要的数据信息。我们看一下源码,splitIndex中包含了split再整个文件系统中的位置,以及该split的开始读取的起始偏移位置。(但是为啥这里没有这个split的数据长度信息呢?)
public 好,言归正传,我们继续回到task.run()的话题。MapTask整个过程实际上分为两个阶段(phase): MapPhase和SortPhase,前者就是调用我们在用Hadoop的时候写的map函数,后者是对MapTask产生的中间文件进行排序,把归属于同一个Reducer的KV排到一起。这样等MapTask执行结束之后,Task需要向AppMaster返回R个类似于(intermeidateFile, startOffset, length)这样的三元组,标识每个partition的数据的存储位置。task.run()的代码如下,代码不长,就直接全部放过来:
@Override
在上面的代码中,根据是否使用新的API选择调用NewMapper还是OldMapper。我们以调用NewMapper为例来看里面发生了什么。
private 我们发现在NewMapper里面获取了split的信息, 获取了读取split的RecorderReader , 同时获取了mapper输出的结果收集器OutputCollector,同时获取了一个向AppMaster报告任务信息的TaskReporter,创建了一个mapper。获取这些之后建立一个mapper的执行环境mapperContext,最终调用了mapper.run(mapperContext)
接着我们来看看mapper.run()中又发生了什么。胜利就在前方了同志们,坚持住。
通过下面的代码我们发现run()方法里很简单,就是不停的获取Key,Value,然后把这些Key,Value传给用户自定义的map()函数进行处理。
public 最后的最后,我们来看看map函数又发生了什么。map就是我们使用hadoop的时候编写的map函数,在函数的最后我们把处理的结果通过context类写入到我们刚才在MapTask中定义的输出数据收集器中。
/**
至此,我们走完了从YarnChild进程启动,到最后我们定义的map/reduce函数的执行流程。我们看到实现中一步步的封装。
总结
本篇文章主要是代码阅读了。由于我也才是开始读Hadoop的代码, 上周写完作业读了一下,然后就是今天为了写博客认真读了一遍,我自己对这个也比较陌生,所以写起来可能没法举重若轻。我今天上午读MR的代码的时候都快崩了,感觉找不到头,很乱。直到下午才开始找到主线,最后能一路顺藤摸瓜似地找到整个链条上地调用关系。也希望大家能读完这篇文章后,对读Hadoop地代码能有所帮助。这篇文章没有讲MapTask执行的过程中的中间文件生成、ReduceTask执行过程中的数据获取(Shuffle)、数据排序以及数据计算过程。这些内容放在下周的博客里面研究吧。
后记
终于写完了,太不容易了。















 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









