







我们现在知道Linux下一切皆文件,对Linux的操作就是对文件的处理,那么怎么能更好的处理文件呢?这就要用到我们上面的三剑客命令。
在说这三个命令前我们要插入一个小插曲就是“正则表达式”。
转载:https://blog.csdn.net/sj349781478/article/details/82930982
本文的测试文件是 test.log,下面的操作大部分在此基础上进行。
一、正则表达式
所谓的正则表达式我个人理解就是正规的表示方法。他是用简单的方法来实现强大的功能,所以深受计算机爱好者的使用。
三剑客与正则表达式是什么关系呢?
我们可以这样理解,三剑客就是普通的命令,有的把他们叫做工具,在我看来都一样。而正则表达式就好比一个模版。三剑客能读懂这个模版。就这么简单。注意只有三剑客才能读懂这个模版哦!
现在他们的关系和功能都搞懂了,接下来我们就来认识下他们怎么结合的。正则表达式是一个模版,这个模版是由一些普通字符和一些元字符组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义。具体如下
| 元字符 | 功能 | 意思 |
| ^ | 匹配行首 | 表示以某个字符开头 |
| $ | 匹配行尾 | 表示以某个字符结尾 |
| ^$ | 空行的意思 | 表示空行的意思 |
| . | 匹配任意单个字符 | 表示任意一个字符 |
| * | 字符* 匹配0或多个此字符 | 表示重复的任意多个字符 |
| \ | 屏蔽一个元字符的特殊含义 | 表示去掉有意义的元字符的含义 |
| [] | 匹配中括号内的字符 | 表示过滤括号内的字符 |
| .* | 代表任意多个字符 | 就是代表任意多个字符 |
| lele\{n\} | 用来匹配前面lele出现次数。n为次数 | 就是统计前面lele出现的次数 |
| lele\{n,\} | 含义同上,但次数最少为n | 从功能就可以看出 |
| lele\{n,m\} | 义同上,但lele出现次数在n与m之间 | 从功能也可以看出 |
| lele\{n,m\} | 义同上,但lele出现次数在n与m之间 | 从功能也可以看出 |
义同上,但lele出现次数在n与m之间
从功能也可以看出
三剑客的功能非常强大,但我们只需要掌握他们分别擅长的领域即可:grep擅长查找功能,sed擅长取行和替换。awk擅长取列。
二、grep
文本过滤(模式:pattern)工具,grep, egrep
grep [OPTIONS] PATTERN [FILE...]
--color=auto 对匹配到的文本着色显示
-v 显示不被pattern匹配到的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系
grep –e ‘cat ’ -e ‘dog’ file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 相当于fgrep,不支持正则表达式
举例子
1、查找文件test.log内容包含fd的行数
grep -n fd test.log

2、查找文件内容不包含 f 的行
grep -nv f test.log

3、查找以1开头的行(可以是一个字符,也可以是多个字符,比如把1改成12,就只有第12行满足)

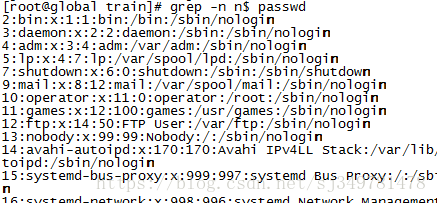
4、查找以n结尾的行(passwd也是一个文件)
三、sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
sed [option]... 'script' inputfile
1、选项
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f /PATH/SCRIPT_FILE: 从指定文件中读取编辑脚本
-r 支持使用扩展正则表达式
-i 直接编辑文件
-i.bak 备份文件并原处编辑2、script 地址定界
1、不给地址:对全文进行处理
2、单地址:
: 指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
3、地址范围:
#,#
#,+#
/pat1/,/pat2/
`#,/pat1/
4、~:步进
1~2 奇数行
2~2 偶数行
3、编辑命令:
d 删除模式空间匹配的行,并立即启用下一轮循环
p 打印当前模式空间内容,追加到默认输出之后
a [\]text1 在指定行后面追加文本,支持使用\n实现多行追加
i [\]text 在行前面插入文本
c [\]text 替换行为单行或多行文本
w /path/somefile 保存模式匹配的行至指定文件
r /path/somefile 读取指定文件的文本至模式空间中匹配到的行后
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
s///:查找替换,支持使用其它分隔符,s@@@,s###
替换标记:
g 行内全局替换
p 显示替换成功的行
w /PATH/TO/SOMEFILE 将替换成功的行保存至文件中举例子:
1、打印出文件第29行

2、打印出2-29行的内容

3、将文件中的root全部替换为abc
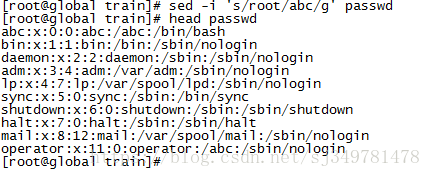
直接修改读取的文件内容,而不是输出到终端。
s :取代,可以直接进行取代的工作。
g: 是全局的意思。其中#是格式符,他也可以是@或者别的/。
sed替换格式是:sed -i ‘s/要替换的内容/替换成的内容/g' 文件名。
四、awk
报告生成器,格式化文本输出,有多种版本:New awk(nawk),GNU awk( gawk)
awk [options] 'program' file…
1、program:pattern{action statements;..}
pattern部分决定动作语句何时触发及触发事件
BEGIN,END
action statements对数据进行处理,放在{}内指明
print, printf
2、选项:
-F 指明输入时用到的字段分隔符
-v var=value 自定义变量
3、分割符、域和记录
awk执行时,由分隔符分隔的字段(域)标记1,1,2..n称为域标识,n称为域标识,0为所有域。
省略action,则默认执行 print $0 的操作。
4、变量
FS:输入字段分隔符;OFS:输出字段分隔符;RS:输入记录分隔符;ORS:输出记录分隔符;NF:字段数量;NR:记录号;NFR:各文件分别计数,记录号。FILENAME:当前文件名;ARGC:命令行的参数;ARGV:数组,保存的是命令行所给定的各参数。
注意:以上都是内置变量,在引用时不需要前面加$,每新建一个变量,都需要加个-v,与变量名之间有无空格都可以,变量可以在引用之后再声明,但那一行的输出会输出空行。
5、printf命令
printf “FORMAT” , item1, item2, ... 不会自动换行,FORMAT中需要分别为后面每个item指定格式符。
格式符
格式符 item表现形式
%c 显示字符的ASCII码
%d, %i 显示十进制整数
%e, %E 显示科学计数法数值
%f 显示为浮点数
%g, %G 以科学计数法或浮点形式显示数值
%s 显示字符串
%u 无符号整数
%% 显示%自身
修饰符
格式符 item表现形式
#[.#] 第一个数字控制显示的宽度;第二个#表示小数点后精度,%3.1f
- 左对齐(默认右对齐) %-15s
+ 显示数值的正负符号 %+d
6、操作符
算术操作符:x+y, x-y, x*y, x/y, x^y, x%y
-x: 转换为负数
+x: 转换为数值
比较操作符:==, !=, >, >=, <, <=
模式匹配符:~:左边是否和右边匹配包含 !~:是否不匹配
逻辑操作符:与&&,或||,非!
函数调用:function_name(argu1, argu2, ...)
条件表达式(三目表达式):selector?if-true-expression:if-false-expression
7、PATTERN:根据pattern条件,过滤匹配的行,再做处理
如果未指定:空模式,匹配每一行
/regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来
relational expression: 关系表达式,结果为“真”才会被处理
line ranges:行范围 startline,endline:/pat1/,/pat2/不支持直接给出数字格式
BEGIN/END模式
8、awk控制语句
{ statements;… } 组合语句
if(condition) {statements;…}
if(condition) {statements;…} else {statements;…}
while(conditon) {statments;…}
do {statements;…} while(condition)
for(expr1;expr2;expr3) {statements;…}
break
continue
delete array[index]
delete array
exit
awk [-F|-v] '行数筛选{XXX;XXX;printf “”,XXX,XXX}'
举例子:
1、打印文件第一列
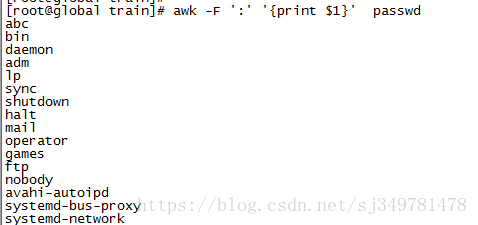
这里的分隔符是冒号 ,然后print打印第一列
2、打印passwd文件中的第1,2,3列,每列左对齐(如果没有 OFS="\t" ,则不会对齐)
root@VM-0-3-ubuntu:/etc# awk -F ':' '{print $1,$2,$3}' OFS="\t" passwd
root x 0
daemon x 1
bin x 2
sys x 3
sync x 4
games x 5
man x 6
lp x 7
mail x 8
news x 9
uucp x 10
proxy x 13
www-data x 33
backup x 34
list x 38
irc x 39
gnats x 41
nobody x 65534
systemd-network x 100
systemd-resolve x 101
syslog x 102
messagebus x 103
_apt x 104
lxd x 105
uuidd x 106
dnsmasq x 107
landscape x 108
sshd x 109
pollinate x 110
ubuntu x 500
ntp x 111cat一下看看原文件长什么样
cat /etc/passwd
root@VM-0-3-ubuntu:~# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/var/run/ircd:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
systemd-network:x:100:102:systemd Network Management,,,:/run/systemd/netif:/usr/sbin/nologin
systemd-resolve:x:101:103:systemd Resolver,,,:/run/systemd/resolve:/usr/sbin/nologin
syslog:x:102:106::/home/syslog:/usr/sbin/nologin
messagebus:x:103:107::/nonexistent:/usr/sbin/nologin
_apt:x:104:65534::/nonexistent:/usr/sbin/nologin
lxd:x:105:65534::/var/lib/lxd/:/bin/false
uuidd:x:106:110::/run/uuidd:/usr/sbin/nologin
dnsmasq:x:107:65534:dnsmasq,,,:/var/lib/misc:/usr/sbin/nologin
landscape:x:108:112::/var/lib/landscape:/usr/sbin/nologin
sshd:x:109:65534::/run/sshd:/usr/sbin/nologin
pollinate:x:110:1::/var/cache/pollinate:/bin/false
ubuntu:x:500:500:ubuntu,,,:/home/ubuntu:/bin/bash
ntp:x:111:115::/nonexistent:/usr/sbin/nologin3、取出最近登录的5名用户
[root@www ~]# last -n 5 <==仅取出前五行
root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in
root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41)
root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48)
dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00)
root tty1 Fri Sep 5 14:09 - 14:10 (00:01)如果只取出用户名(即只取第一列,就需要用到awk)
last -n 5 | awk '{print $1}'
#last -n 5 | awk '{print $1}'
root
root
root
dmtsai
root4、其他应用
应用1
awk -F: '{print NF}' helloworld.sh //输出文件每行有多少字段
awk -F: '{print $1,$2,$3,$4,$5}' helloworld.sh //输出前5个字段
awk -F: '{print $1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //输出前5个字段并使用制表符分隔输出
awk -F: '{print NR,$1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //制表符分隔输出前5个字段,并打印行号
应用2
awk -F'[:#]' '{print NF}' helloworld.sh //指定多个分隔符: #,输出每行多少字段
awk -F'[:#]' '{print $1,$2,$3,$4,$5,$6,$7}' OFS='\t' helloworld.sh //制表符分隔输出多字段
应用3
awk -F'[:#/]' '{print NF}' helloworld.sh //指定三个分隔符,并输出每行字段数
awk -F'[:#/]' '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12}' helloworld.sh //制表符分隔输出多字段
应用4
计算/home目录下,普通文件的大小,使用KB作为单位
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",sum/1024,"KB"}'
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}'//int是取整的意思
应用5
统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少
netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'
应用6
统计/home目录下不同用户的普通文件的总数是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}'
mysql 199
root 374
统计/home目录下不同用户的普通文件的大小总size是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'
应用7
输出成绩表
awk 'BEGIN{math=0;eng=0;com=0;printf "Lineno. Name No. Math English Computer Total\n";printf "------------------------------------------------------------\n"}{math+=$3; eng+=$4; com+=$5;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n",NR,$1,$2,$3,$4,$5,$3+$4+$5} END{printf "------------------------------------------------------------\n";printf "%-24s %-7s %-9s %-20s \n","Total:",math,eng,com;printf "%-24s %-7s %-9s %-20s \n","Avg:",math/NR,eng/NR,com/NR}' test0
[root@localhost home]# cat test0
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62














 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









