






一、背景
项目中需要将某数据显示的内容,提供一个下载 DOCX 与 PDF 功能。在分析阶段发现 docx4j(http://www.docx4java.org/trac/docx4j)提供了转换功能。在调试开发时遇到了 HTML 格式兼容,样式丢失,PDF 中文字体等问题。
二、分析
docx4j-ImportXHTML(https://github.com/plutext/docx4j-ImportXHTML),从名称上一看就知道这个只支持 XHTML。如果是非 XHTML 格式,解析就有问题。
所以在样例中使用了jsoup(http://jsoup.org/)将 HTML 统一转换为 XHTML,并去掉不需要的一些内容(如:script)。这时再调用 docx4j-ImportXHTML 就可以正常解析。
注:这种转换不适用于常规 HTML 页面,转换过程中会丢失样式造成混乱。在这里想要做的是一种以特定 HTML 格式编写页面模板转出 DOCX 与 PDF 的方式。
三、样例程序
样例程序中有很多注释,这理就不再深入描述。该程序支持 Linux 环境。
1、主流程
a、jsoup 抓取指定 URL 的内容
b、使用 jsoup 清理内容,转为 XHTML
c、调用 docx4j-ImportXHTML,生成 WordprocessingMLPackage 对象(docx4j)
d、另存为 DOCX 与 PDF
2、POM 文件
这里使用了 Jetty,主要作用是测试时充当假 HTTP 服务器。
直接运行 mvn clean test 就可以看到转换效果。
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
org.noahx
html2docx
1.0.0-SNAPSHOT
org.docx4j
docx4j-ImportXHTML
3.2.2
slf4j-log4j12
org.slf4j
log4j
log4j
org.jsoup
jsoup
1.8.1
org.slf4j
slf4j-simple
1.7.10
test
org.eclipse.jetty
jetty-server
9.2.9.v20150224
test
3、TestHtmlConverter 单元测试类
该类创建模拟 HTTP 服务器,调用转换类将 HTML 内容转换为 DOCX 与 PDF,并调用操作系统打开文件操作。
出于调试目的,日志输出级别为 DEBUG,会产生大量日志。实际运行时可以提高日志级别。
package org.noahx.html2docx;
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.slf4j.impl.SimpleLogger;
import java.awt.*;
import java.io.File;
/**
* Created by noah on 3/12/15.
*/
public class TestHtmlConverter {
private static HtmlServer htmlServer = new HtmlServer();
@BeforeClass
public static void before() {
System.setProperty(SimpleLogger.DEFAULT_LOG_LEVEL_KEY, "DEBUG");
htmlServer.start();
}
@AfterClass
public static void after() {
htmlServer.stop();
}
@Test
public void test() throws Exception {
HtmlConverter converter = new HtmlConverter();
String url = "http://127.0.0.1:" + htmlServer.getPort() + "/report.html"; //输入要转换的网址
File fileDocx = converter.saveUrlToDocx(url);
File filePdf = converter.saveUrlToPdf(url);
Desktop.getDesktop().open(fileDocx); //由操作系统打开
Desktop.getDesktop().open(filePdf);
}
}
4、HTML 样本文件(report.html)
样式问题请查看注释。
测试标题body {
font-family: SimSun;
}
.tb {
border-collapse: collapse;
empty-cells: show;
width: 100%; /*竖版时100%宽度不正确*/
}
.tb th {
text-align: center;
border: 1px solid #000000; /* pdf 输出时边颜色受 color 影响,所以指定 #000000 */
}
.tb td {
border: 1px solid #000000; /* pdf 输出时边颜色受 color 影响,所以指定 #000000 */
}
p {
/*不支持 text-indent 样式,用中文全角空格( ) */
/*text-indent: 2em;*/
}
标题1:大家好
标题2:大家好
标题3:大家好
这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。这是一个中文段落。
| a |
| 第一列 | 第二列 | 第三列 | 第四列 |
|---|---|---|---|
| abc | efg | efg | efg |
| abc | efg | efg | efg |
表1
| 第一列 | 第二列 | 第三列 | 第四列 |
|---|---|---|---|
| abc | efg | efg | efg |
| abc | efg | efg | efg |
图1
![]()
图2

图3
5、主转换程序(HtmlConverter)
package org.noahx.html2docx;
import org.docx4j.Docx4J;
import org.docx4j.convert.in.xhtml.XHTMLImporterImpl;
import org.docx4j.fonts.IdentityPlusMapper;
import org.docx4j.fonts.Mapper;
import org.docx4j.fonts.PhysicalFont;
import org.docx4j.fonts.PhysicalFonts;
import org.docx4j.jaxb.Context;
import org.docx4j.model.structure.PageSizePaper;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.wml.RFonts;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.nodes.Entities;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.OutputStream;
import java.net.URL;
/**
* Created by noah on 3/10/15.
*/
public class HtmlConverter {
/**
* 输出文件名
*/
public final String OUT_FILENAME = "OUT_ConvertInXHTMLURL";
private final Logger logger = LoggerFactory.getLogger(this.getClass());
/**
* 将页面保存为 docx
*
* @param url
* @return
* @throws Exception
*/
public File saveUrlToDocx(String url) throws Exception {
return saveDocx(url2word(url));
}
/**
* 将页面保存为 pdf
*
* @param url
* @return
* @throws Exception
*/
public File saveUrlToPdf(String url) throws Exception {
return savePdf(url2word(url));
}
/**
* 将页面转为 {@link org.docx4j.openpackaging.packages.WordprocessingMLPackage}
*
* @param url
* @return
* @throws Exception
*/
public WordprocessingMLPackage url2word(String url) throws Exception {
return xhtml2word(url2xhtml(url));
}
/**
* 将 {@link org.docx4j.openpackaging.packages.WordprocessingMLPackage} 存为 docx
*
* @param wordMLPackage
* @return
* @throws Exception
*/
public File saveDocx(WordprocessingMLPackage wordMLPackage) throws Exception {
File file = new File(genFilePath() + ".docx");
wordMLPackage.save(file); //保存到 docx 文件
if (logger.isDebugEnabled()) {
logger.debug("Save to [.docx]: {}", file.getAbsolutePath());
}
return file;
}
/**
* 将 {@link org.docx4j.openpackaging.packages.WordprocessingMLPackage} 存为 pdf
*
* @param wordMLPackage
* @return
* @throws Exception
*/
public File savePdf(WordprocessingMLPackage wordMLPackage) throws Exception {
File file = new File(genFilePath() + ".pdf");
OutputStream os = new java.io.FileOutputStream(file);
Docx4J.toPDF(wordMLPackage, os);
os.flush();
os.close();
if (logger.isDebugEnabled()) {
logger.debug("Save to [.pdf]: {}", file.getAbsolutePath());
}
return file;
}
/**
* 将 {@link org.jsoup.nodes.Document} 对象转为 {@link org.docx4j.openpackaging.packages.WordprocessingMLPackage}
* xhtml to word
*
* @param doc
* @return
* @throws Exception
*/
protected WordprocessingMLPackage xhtml2word(Document doc) throws Exception {
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.createPackage(PageSizePaper.valueOf("A4"), true); //A4纸,//横版:true
configSimSunFont(wordMLPackage); //配置中文字体
XHTMLImporterImpl xhtmlImporter = new XHTMLImporterImpl(wordMLPackage);
wordMLPackage.getMainDocumentPart().getContent().addAll( //导入 xhtml
xhtmlImporter.convert(doc.html(), doc.baseUri()));
return wordMLPackage;
}
/**
* 将页面转为{@link org.jsoup.nodes.Document}对象,xhtml 格式
*
* @param url
* @return
* @throws Exception
*/
protected Document url2xhtml(String url) throws Exception {
Document doc = Jsoup.connect(url).get(); //获得
if (logger.isDebugEnabled()) {
logger.debug("baseUri: {}", doc.baseUri());
}
for (Element script : doc.getElementsByTag("script")) { //除去所有 script
script.remove();
}
for (Element a : doc.getElementsByTag("a")) { //除去 a 的 onclick,href 属性
a.removeAttr("onclick");
a.removeAttr("href");
}
Elements links = doc.getElementsByTag("link"); //将link中的地址替换为绝对地址
for (Element element : links) {
String href = element.absUrl("href");
if (logger.isDebugEnabled()) {
logger.debug("href: {} -> {}", element.attr("href"), href);
}
element.attr("href", href);
}
doc.outputSettings()
.syntax(Document.OutputSettings.Syntax.xml)
.escapeMode(Entities.EscapeMode.xhtml); //转为 xhtml 格式
if (logger.isDebugEnabled()) {
String[] split = doc.html().split("\n");
for (int c = 0; c < split.length; c++) {
logger.debug("line {}:\t{}", c + 1, split[c]);
}
}
return doc;
}
/**
* 为 {@link org.docx4j.openpackaging.packages.WordprocessingMLPackage} 配置中文字体
*
* @param wordMLPackage
* @throws Exception
*/
protected void configSimSunFont(WordprocessingMLPackage wordMLPackage) throws Exception {
Mapper fontMapper = new IdentityPlusMapper();
wordMLPackage.setFontMapper(fontMapper);
String fontFamily = "SimSun";
URL simsunUrl = this.getClass().getResource("/org/noahx/html2docx/simsun.ttc"); //加载字体文件(解决linux环境下无中文字体问题)
PhysicalFonts.addPhysicalFont(fontFamily, simsunUrl);
PhysicalFont simsunFont = PhysicalFonts.get(fontFamily);
fontMapper.put(fontFamily, simsunFont);
RFonts rfonts = Context.getWmlObjectFactory().createRFonts(); //设置文件默认字体
rfonts.setAsciiTheme(null);
rfonts.setAscii(fontFamily);
wordMLPackage.getMainDocumentPart().getPropertyResolver()
.getDocumentDefaultRPr().setRFonts(rfonts);
}
/**
* 生成文件位置
*
* @return
*/
protected String genFilePath() {
return System.getProperty("user.dir") + "/" + OUT_FILENAME;
}
}
四、转换效果
1、DOCX转换效果
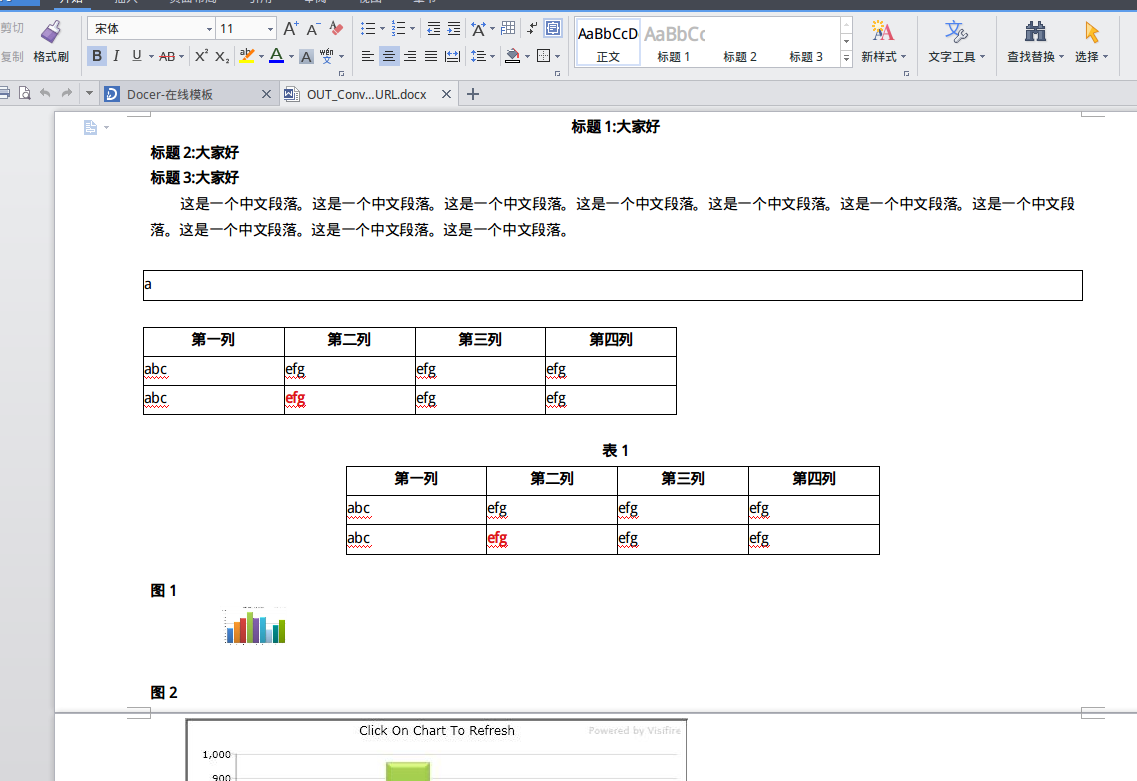
2、PDF转换效果

五、源码下载















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









