





正则表达式-python:split的用法
在python种split的作用:修改字符串(Modifying a string)
In almost every language, you can find the split operation in strings.
在python3中使用split特别注意两点:
- 正则表达式(pattern)带不带括号的区别
- 第一个字符就与正则表达式匹配,结果中的第一个位置会包含一个空字符(Note that when a group matches the start of the string, the result will contain the empty string as a first result.)
正则表达式(pattern)带不带括号的区别
第一个字符就与正则表达式匹配
参数maxsplit的用法:
需要多个分隔符时用中括号[]
最后附上所有源码:
Modifying a string
- In almost every language, you can find the split operation in strings.
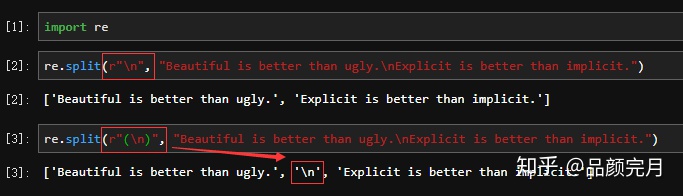
import re- Note that when a group matches the start of the string, the result will contain the empty string as a first result:
re.split(r"n", "Beautiful is better than ugly.nExplicit is better than implicit.")
['Beautiful is better than ugly.', 'Explicit is better than implicit.']
re.split(r"(n)", "Beautiful is better than ugly.nExplicit is better than implicit.")
['Beautiful is better than ugly.', 'n', 'Explicit is better than implicit.']
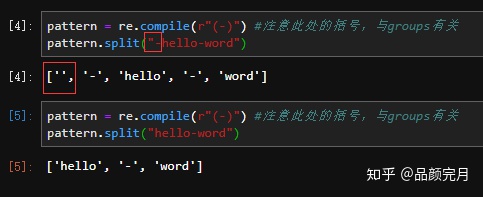
pattern = re.compile(r"(-)") #注意此处的括号,与groups有关
pattern.split("-hello-word")
['', '-', 'hello', '-', 'word']
pattern = re.compile(r"(-)") #注意此处的括号,与groups有关
pattern.split("hello-word")
['hello', '-', 'word']
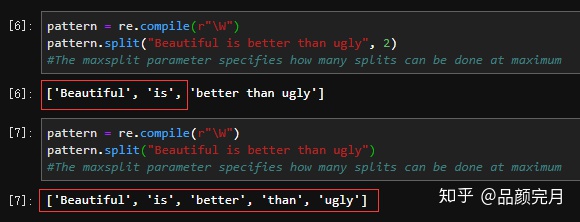
pattern = re.compile(r"W")
pattern.split("Beautiful is better than ugly", 2)
#The maxsplit parameter specifies how many splits can be done at maximum
['Beautiful', 'is', 'better than ugly']
pattern = re.compile(r"W")
pattern.split("Beautiful is better than ugly")
#The maxsplit parameter specifies how many splits can be done at maximum
['Beautiful', 'is', 'better', 'than', 'ugly']
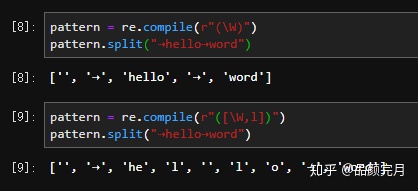
pattern = re.compile(r"(W)")
pattern.split("⇢hello⇢word")
['', '⇢', 'hello', '⇢', 'word']
pattern = re.compile(r"([W,l])")
pattern.split("⇢hello⇢word")
['', '⇢', 'he', 'l', '', 'l', 'o', '⇢', 'word']















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









