





本文是目前为止最简单,也不需要配Hadoop环境之类的教程,但是如果是xjtlu的小伙伴,可能就不太合适,因为老师好像是要求写出hdfs的操作的代码的,这儿可以参考阿里云第二弹。
loner:从阿里云轻量服务器安装Hadoop及环境配置zhuanlan.zhihu.com我们今天这篇文章是等价于以下这篇文章,来运行wordcount.java这个文件的
loner:阿里云Hadoop第二弹(运行WordCount)zhuanlan.zhihu.com在第二弹里面,核心的思路就是,在HDFS上创建文件,本地上传文件,连同你的script,然后在服务器里用javac compile出你的classes,然后打包成一个jar包,然后在Hadoop上运行jar包,然后同样也是用Hadoop命令查看你的结果。步骤显得非常繁琐
但是,在我注册完(白嫖完)IntelliJ IDEA的专业版后,他会提醒你需不需要装big data tools这个第三方插件,然后我巨盯着下面这行菜单栏陷入沉思,肯定可以有那种一键run,然后生成output的方式。

至于为什么不用eclipse,因为它实在太丑了(谁还不是个颜狗呢 )
我首先总结下Hadoop的三种运行模式
1。 单机模式
2。 伪分布模式
3。 完全分布模式
之前的三篇文章其实搭建的都是伪分布模式Hadoop的安装。但实际上基于Hadoop的MapReduce程序在本地程序上就完全可以运行,并不一定需要伪分布模式,甚至连Hadoop都不一定需要安装。在单机模式下,可以将MapReduce的程序当成一个普普通通的java程序。在这里我们需要借助项目管理工具Maven。这里就不用导入各种依赖,只需要一键导入pom文件(其中制定了Hadoop依赖包的名字和版本号),就不需要在花额外的时间纠缠在各种依赖上,只需要专门focus在你的代码编写上了
这里插一句:有很多小伙伴问我阿里云教程一步步做了,为啥还是装不上,各种找不到啊,或者报错。
1。代码一行行运行,不要全部复制,因为terminal里面毕竟是一行行运行的,若复制几行,很有可能会出错,比如某一行忘记运行了
2。如果是阿里云,记住,重置系统花的时间远比debug要的花的时间少,如果你只是完成作业,请大胆重置,如果你有很多时间,且很有兴趣,可以大胆的去搜去研究,对Linux环境的理解会很有帮助
进入正题,我们首先需要创建一个project,并且选择maven。
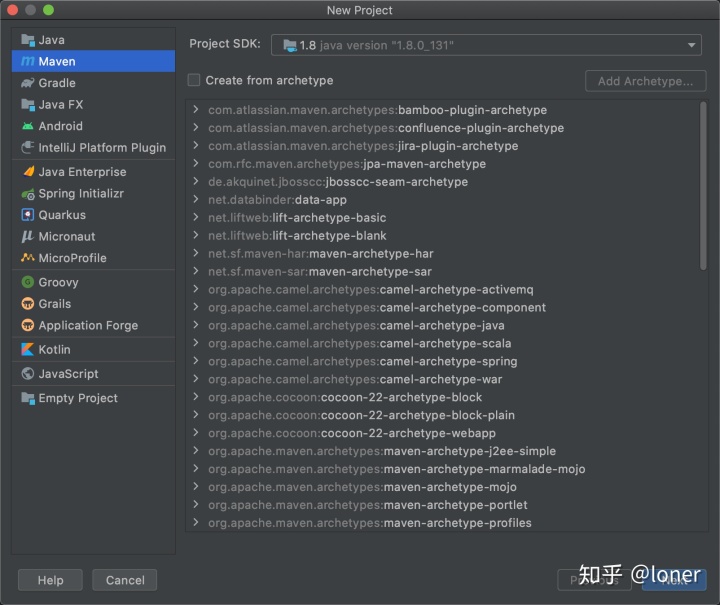
什么是maven,可以在下面链接查看,以及我当时参考的教程。这里非常感谢给予帮助的郭同学,因为之前完全没接触过这些只是,啥都不懂,非常感谢他手把手教我,然后重新看下面的操作,就很好理解(PS:xml的格式一定要完全复制,我之前配置Hadoop环境的时候碰到一个问题就是它xml格式上下不是完全相同的,/做区分)

输入名称后继续,什么都不要改,然后进入新创建的project,初始状态如下
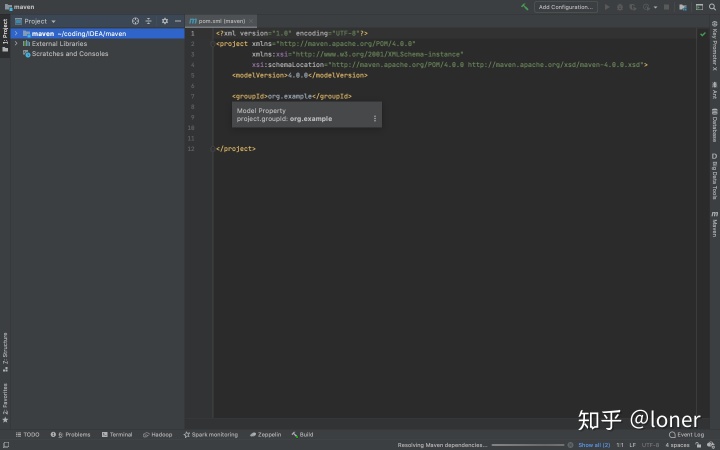
然后下面导入我们的pom文件,路径依赖
<?xml version="1.0" encoding="UTF-8"?>
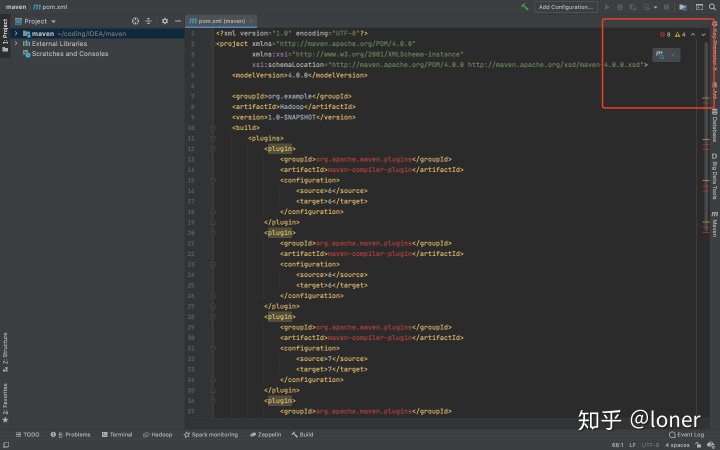
会在右上角红框内出现这个,点击loade pom change,然后Hadoop会自动帮你配置完成,第一次可能需要点时间,等它compile完,你就完成一大半了。
下来书写你的WordCount.java
首先创造一个java,路径是在src/main/java底下new 一个java,class name 叫WordCount,然后这里导入我之前写的WordCount.java
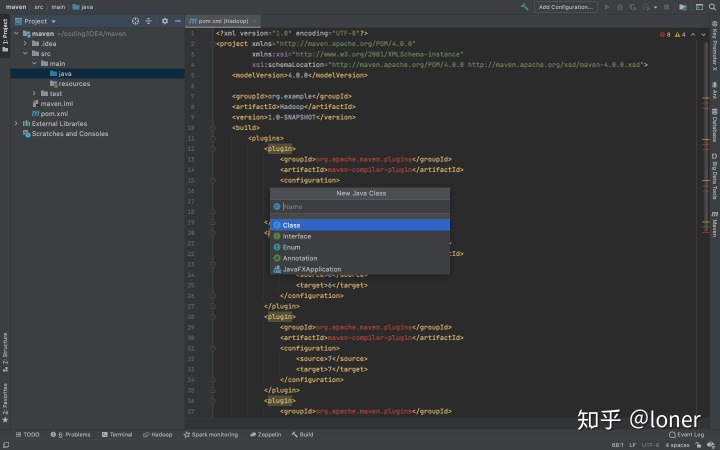
import 下来需要配置运行,选择application
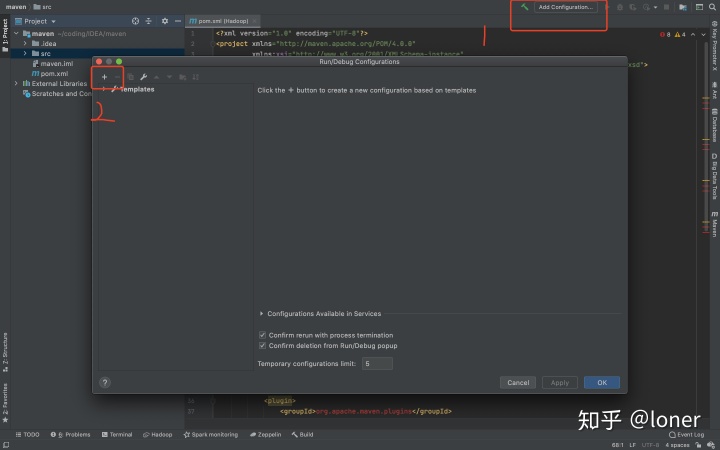
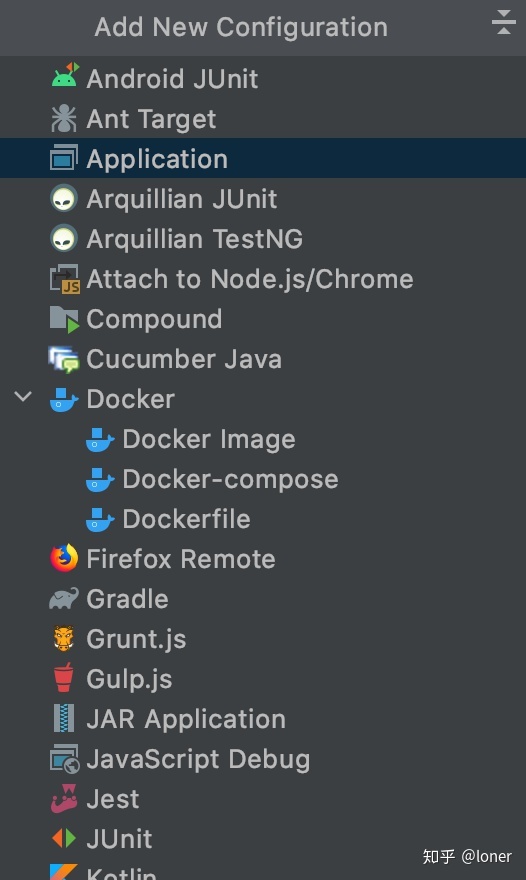
选择application后需要配置如下,name随意,最重要的是Main class: 保证名字和你new的java文件名字一致,input和output是等会要放入的文件,输入和输出
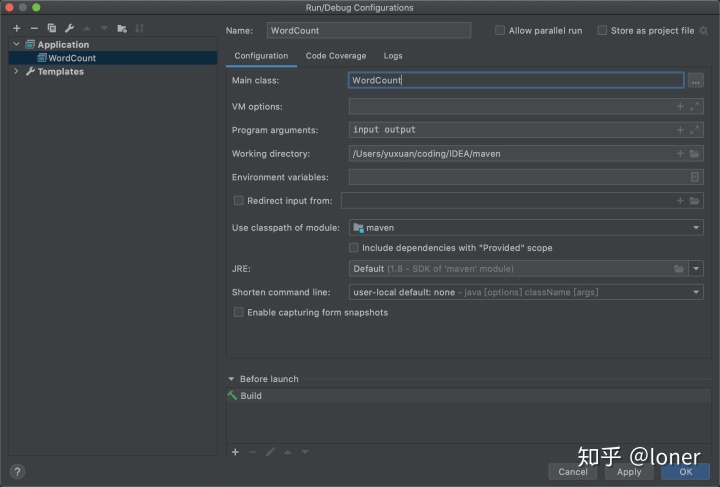
配置输入文件
这里我刚刚在configuration里面写了我的输入文件叫input,需要配置输入路径,这里在(src同级目录下)新建一个文件夹input,并且把你需要输入的文件放进去,这儿还是之前的pg100.txt
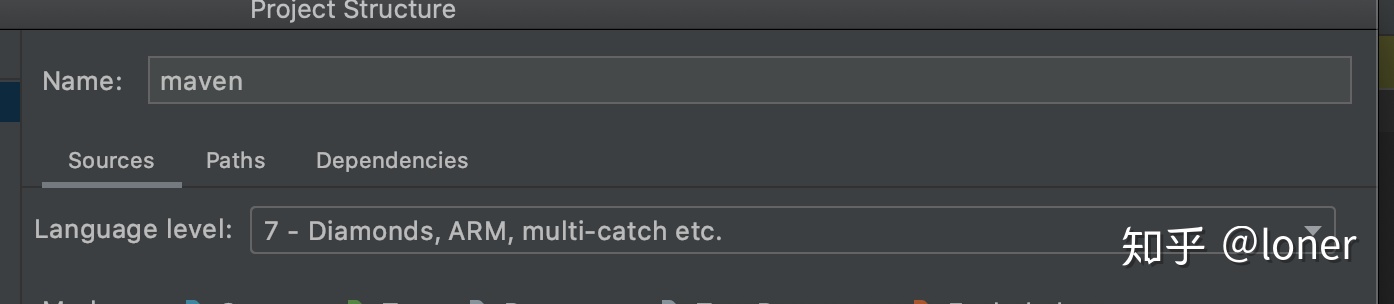
额外,我们需要在File->Project Structure(或者mac快捷键command+;)将language level调整为7,然后点右下角ok
运行和调试
直接点右上角的run

会出现如下情况
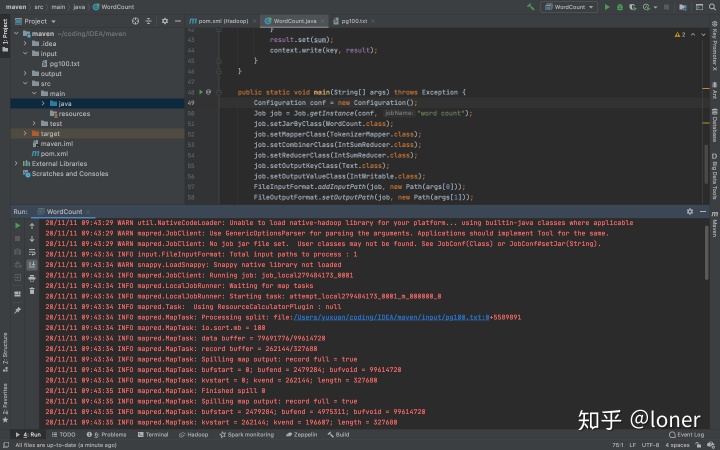
注意:这里的红字不是报错,不要慌!
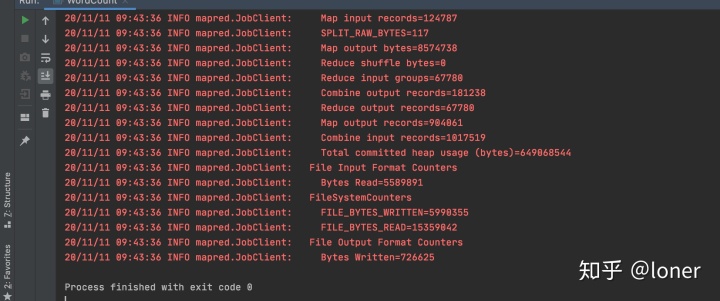
运行成功后,你的文件会出现一个output的文件,由于output的先天特性,它无法覆盖,所以下次运行的时候请删除之前的那个,或者你改个名字(我后来好像看见这个可以用其他方法覆盖的,这里就不做涉及)
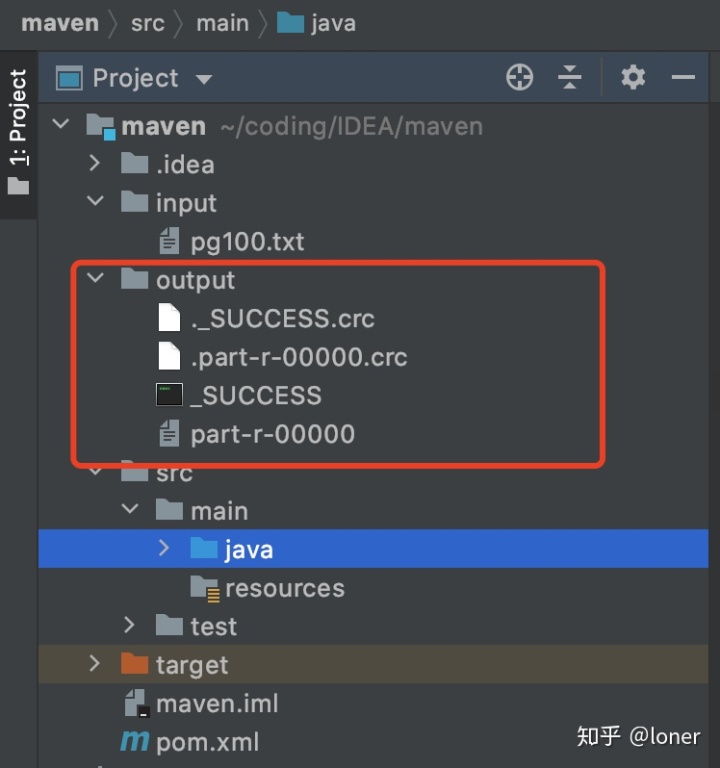
打开part-r-00000,会出现你Hadoop运行的结果

到现在为,用IDEA配置Hadoop已经全部完成了。















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









