





1.基本概念_Collection_Set_List接口介绍
容器:
基于数组并不能满足我们对于“管理和组织数据的需求”,所以我们需要一种更强大、更灵活、容量随时可扩的容器来装载我们的对象。也叫集合。
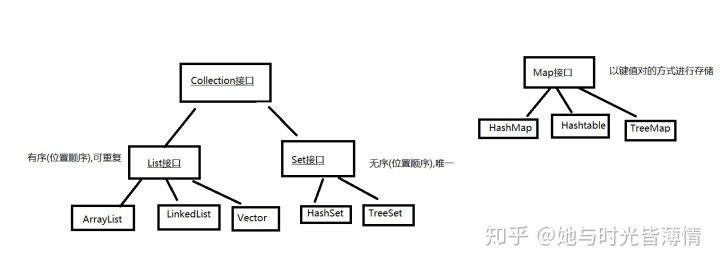
Collection接口
Collection 表示一组对象,它是集中、收集的意思。Collection接口的两个子接口是List、Set接口。
Collection接口中定义的方法

Collection、Set、List接口的特征
Collection 接口存储一组不唯一(可添加重复数据),无序的对象 。
List 接口存储一组不唯一,有序(索引顺序)的对象 。
Set 接口存储一组唯一,无序的对象。
2.List特点和常用方法
List是有序、可重复的容器。
有序:List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问元素,从而精确控制这些元素。
可重复:List允许加入重复的元素。更确切地讲,List通常允许满足 e1.equals(e2) 的元素重复加入容器。
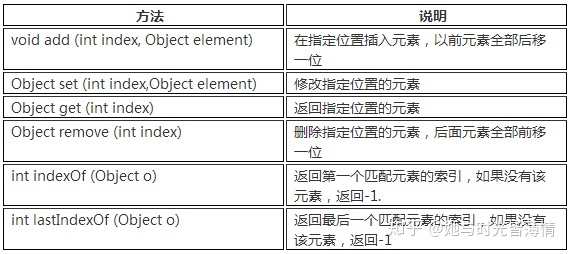
List接口中定义的方法
List接口常用的实现类有3个:ArrayList、LinkedList和Vector。
3.ArrayList特点和底层实现
ArrayList底层是用数组实现的存储。 特点:查询效率高,增删效率低,线程不安全。我们一般使用它。
ArrayList底层使用Object数组来存储元素数据。所有的方法,都围绕这个核心的Object数组来开展。
常用的构造方法:
1)ArrayList():构造- - 个初始容量为十的空列表。
2)ArrayList(int initialCapacity) :构造 具有指定初始容量的空列表。
3)public ArrayList(Collection<? extends E> c)构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
常用方法:
1)add(0bject obj) :将指定的元素追加到此列表的末尾。
2)add(int index, 0bject obj) :在此列表中的指定 位置插入指定的元素。
3)size():获取容器中元素的个数
4)get(int index) 返回此列表中 指定位置的元素。下标的取值 范围[0,size()-1]
5)sEmpty():判断容器是否为空。
6)contains(object o) :如果此列表包含指定的元素,则返回true。
7)index0f(0bject o) :返回此列表中指定元素的第- - 次出现的索引,如果此列表不包含元素,则返回-1.
8)remove(object 0) :从列表中删除指定元素的第一一个出现(如果存在)。
9)addAll(cCollection c):指定集合中的所有元素追加到此列表的末尾。
代码示例:
import 
ArrayList底层实现
import 
4.LinkedList特点和底层实现
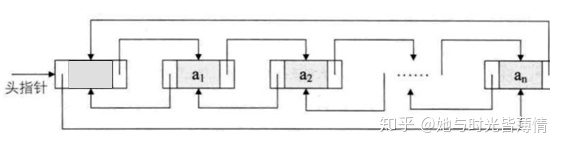
LinkedList底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
双向链表也叫双链表,是链表的一种,它的每个数据节点中都有两个指针,分别指向前一个节点和后一个节点。 所以,从双向链表中的任意一个节点开始,都可以很方便地找到所有节点。
LinkedList的存储结构图
构造方法:
LinkedList():构造一个空列表。
常用方法:
add(E e)将指定的元素追加到此列表的末尾。
add(int index, E element):在此列表中的指定位置插入指定的元素。
以下是LinkedList特有的方法:
addFirst(E e):在该列表开头插入指定的元素。
addLast(E e):将指定的元素追加到此列表的末尾。
getFirst():获取列表中第一个元素。
getLast():获取列表中最后一个元素
removeFirst():移除第一个元素
removeLast():移除最后一个元素
代码示例:
import 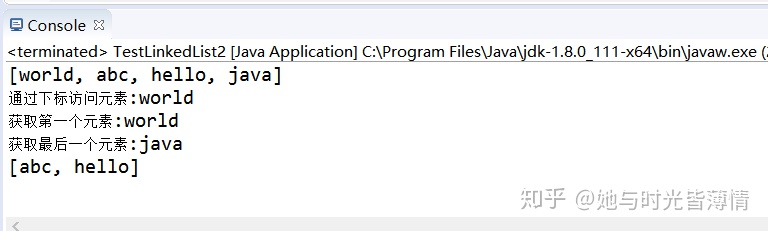
5.Vector向量
Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。
Vector的特有方法:
1.addElement()
2.setElement()
3.removeElement()
4.capacity() 返回容器的容量
Vector与ArrayList的区别(面试题)
1.ArrayList底层采用是数组进行实现的,实现了数组的动态扩容,其查找效率较高,添加删除效率较低,非线程安全,
2.LinkedList底层采用双向链表进行实现,查找效率较低,添加删除效率高,非线程安全。
3.Vector与ArrayList底层实现相同,Vector是线程安全的,效率较低但更适合在多线程程序中使用。
import 
如何选用ArrayList、LinkedList、Vector?
1. 需要线程安全时,用Vector。
2. 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)。
3. 不存在线程安全问题时,增加或删除元素较多用LinkedList。
6.Map接口
Map就是用来存储“键(key)-值(value) 对”的。 Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
Map 接口的实现类有HashMap、TreeMap、HashTable、Properties等。
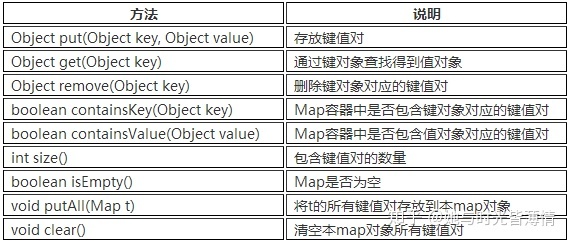
Map接口中常用的方法
HashMap和HashTable
HashMap采用哈希算法实现,是Map接口最常用的实现类。 由于底层采用了哈希表存储数据,我们要求键不能重复,如果发生重复,新的键值对会替换旧的键值对。 HashMap在查找、删除、修改方面都有非常高的效率。
Map接口中HashMap代码示例
import 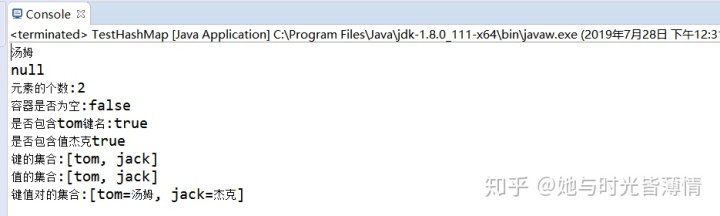
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashTable代码示例
import 
HashMap与HashTable的区别
1. HashMap: 线程不安全,效率高。允许key或value为null。
2. HashTable: 线程安全,效率低。不允许key或value为null。
7.HashMap底层实现详解
HashMap底层实现采用了哈希表,这是一种非常重要的数据结构。对于我们以后理解很多技术都非常有帮助(比如:redis数据库的核心技术和HashMap一样),因此,非常有必要让大家理解。
数据结构中由数组和链表来实现对数据的存储,他们各有特点。
(1) 数组:占用空间连续。 寻址容易,查询速度快。但是,增加和删除效率非常低。
(2) 链表:占用空间不连续。 寻址困难,查询速度慢。但是,增加和删除效率非常高。
Hashmap基本结构讲解
哈希表的本质就是“数组+链表”。
其中的Entry[] table 就是HashMap的核心数组结构,我们也称之为“位桶数组”。
一个Entry对象存储了:
1. key:键对象 value:值对象
2. next:下一个节点
3. hash: 键对象的hash值
显然每一个Entry对象就是一个单向链表结构。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









