






Excel中有一类函数称为“文本函数”,其应用也是非常的广泛,如果与其他函数结合使用,可以发挥大作用哦!
一、Char。
功能:返回与ANSI字符编码对应的字符。
语法结构:=Char(数值)。
注意事项:
Char的参数“数值”表示1-255之间的ANSI字符编码,如果包含小数,则截尾取整,即只保留整数参加计算。
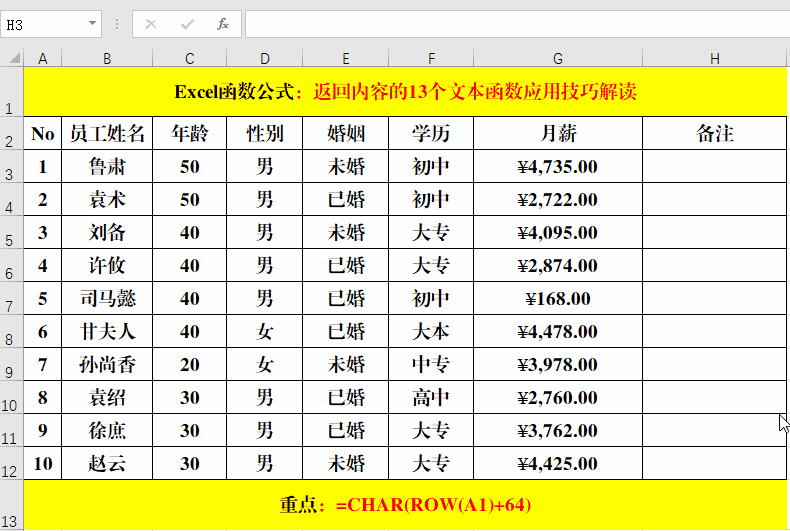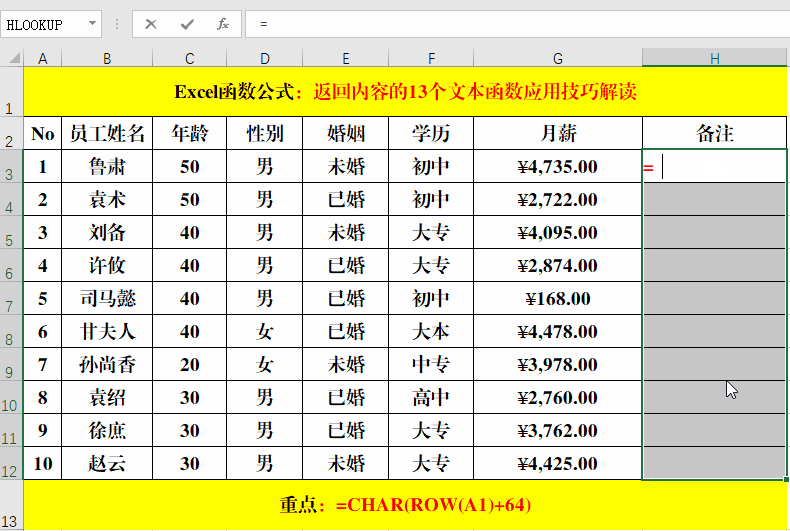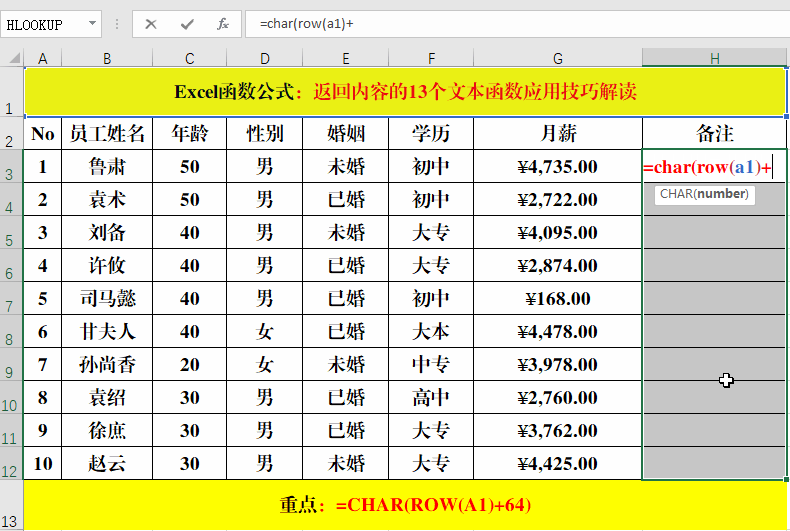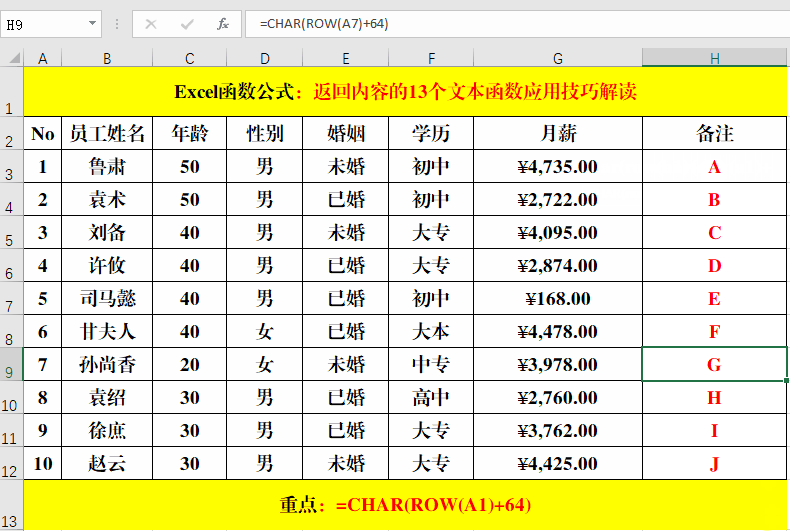
目的:生成大写字母列表。
方法:
在目标单元格中输入公式:=CHAR(ROW(A1)+64)。
解读:
字母A、B、C对应的ANSI码分别为65、66、67,公式中用Row函数获取第一行的行数1,然后+64作为辅助值,最终返回字母A,依次类推。
二、Unichar。
功能:返回与Unicode字符编码对应的字符。
语法结构:=Unichar(数值)。
注意事项:
Unichar的参数“数值”表示要转换为Unicode字符编码的数字,如果包含小数,则截尾取整,即只保留整数参加计算,如果参数为0,则返回错误值#VALUE! 。
目的:输入带双圆圈的数字。
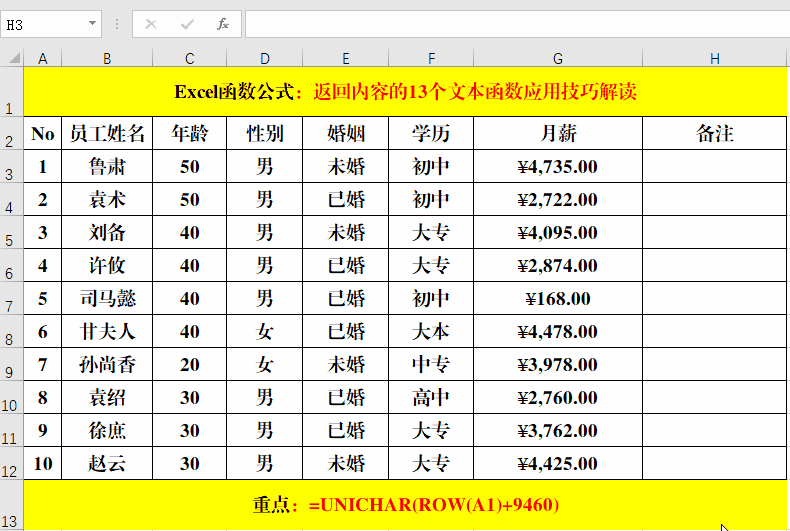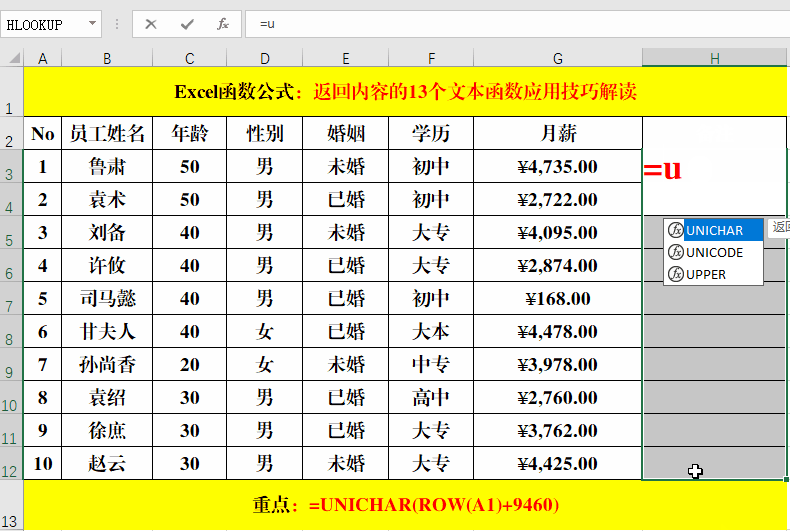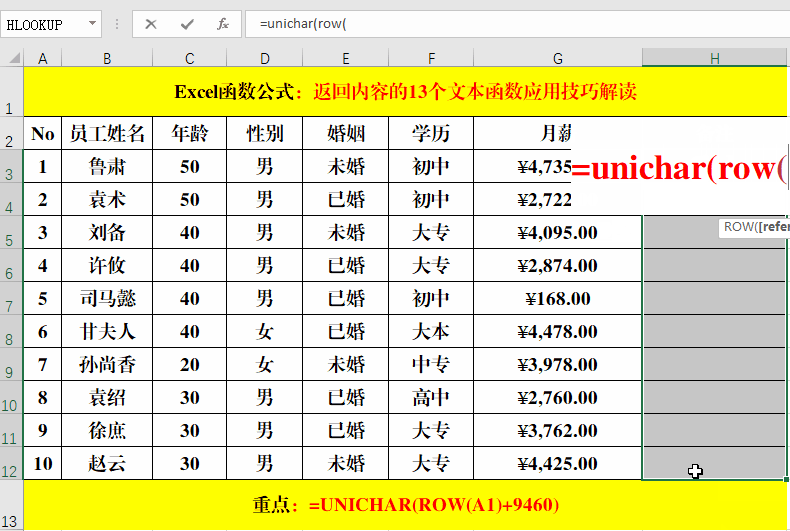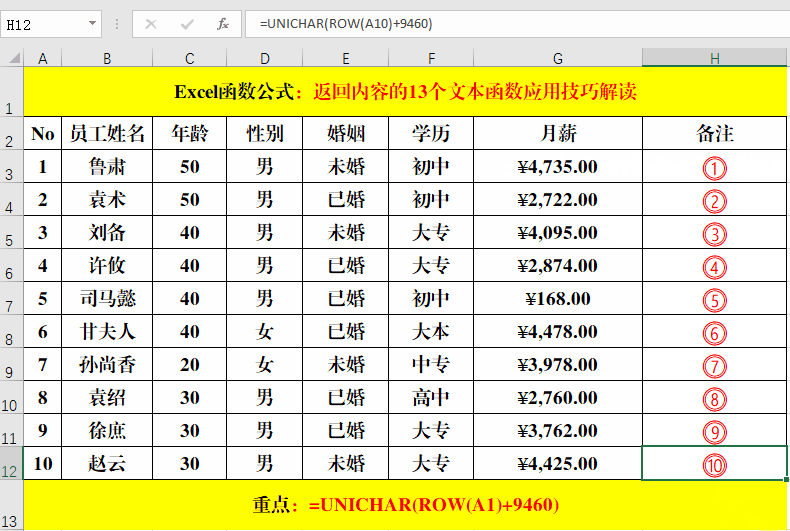
方法:
在目标单元格中输入公式:=UNICHAR(ROW(A1)+9460)。
三、Code。
功能:返回与字符对应的ANSI字符编码。
语法结构:=Code(文本)。
注意事项:
Code的参数“文本”的长度如果>1,Code函数将返回第一个字符的ANSI字符编码。
目的:返回字母对应的ANSI编码。
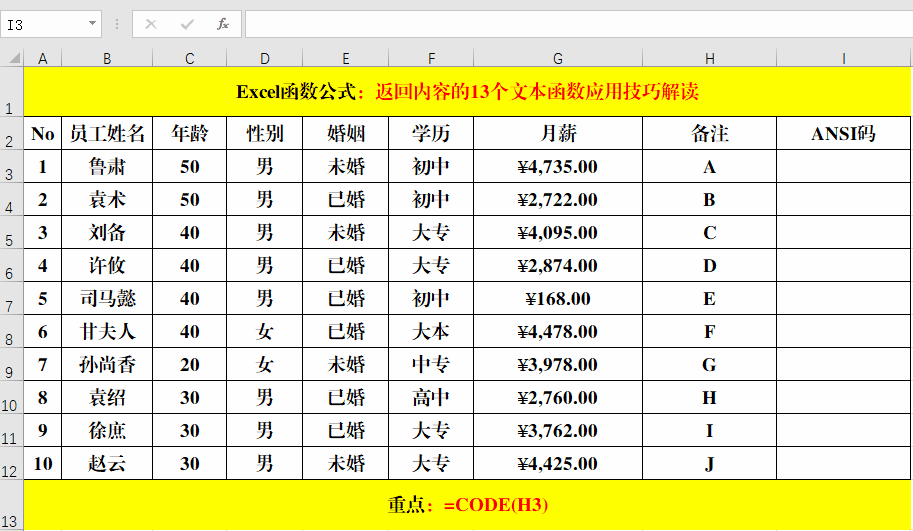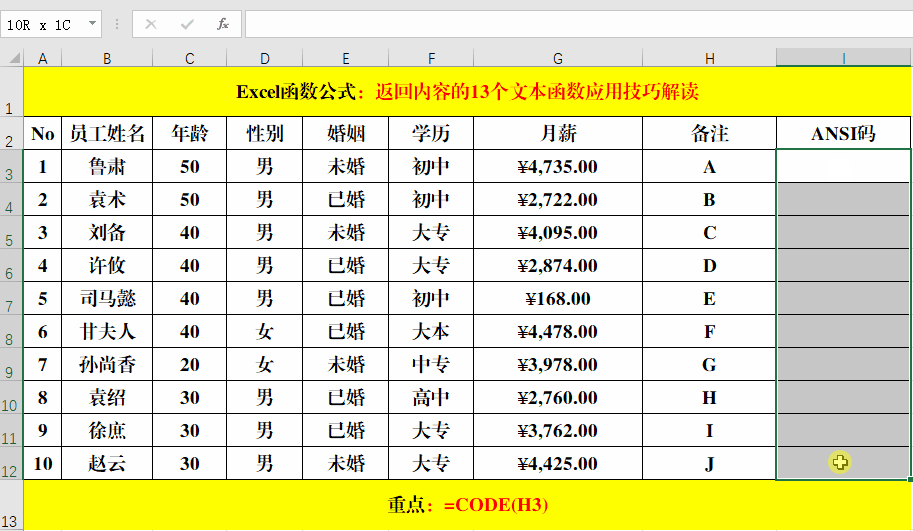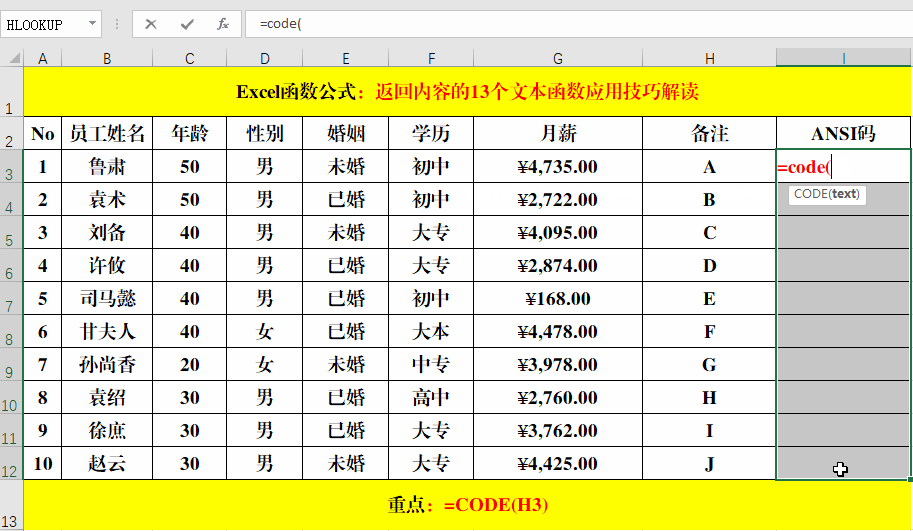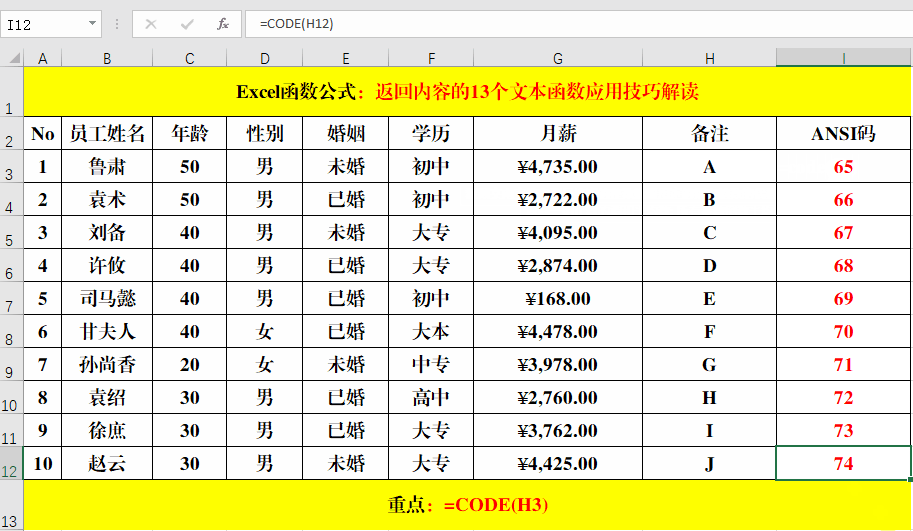
方法:
在目标单元格中输入公式:=CODE(H3)。
解读:
Code函数和Char函数的作用正好相反,Code根据文本返回ANSI编码,而Char根据ANSI编码返回对应的字符。
四、Unicode。
功能:返回与字符对应的Unicode字符编码。
语法结构:=Unicode(文本)。
注意事项:
如果Unicode函数的参数“文本”的长度>1,则返回第一个字符的Unicode字符编码。
目的:返回双圆圈数字对应的Unicode编码。
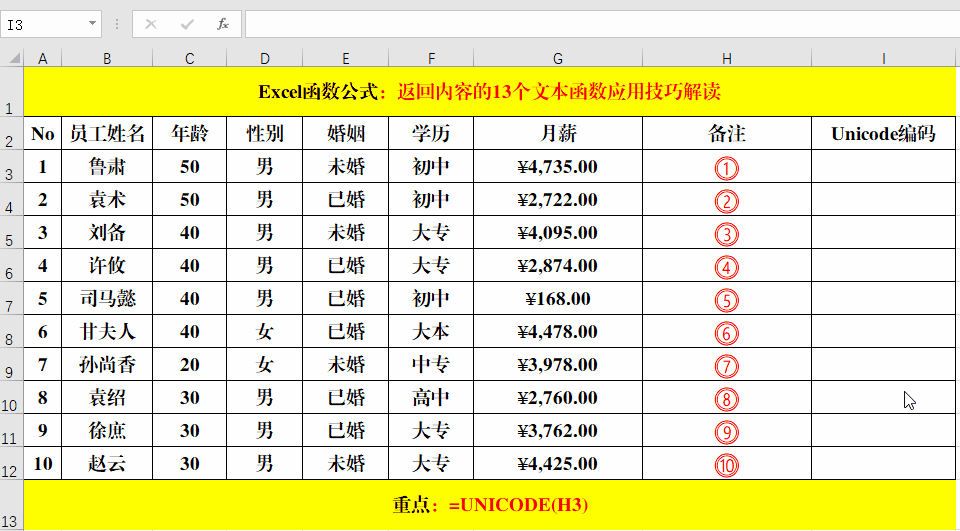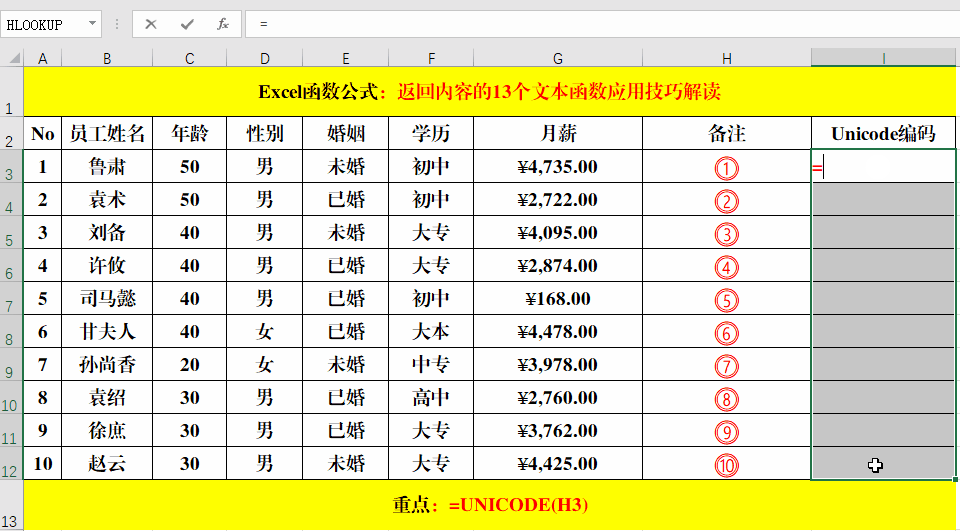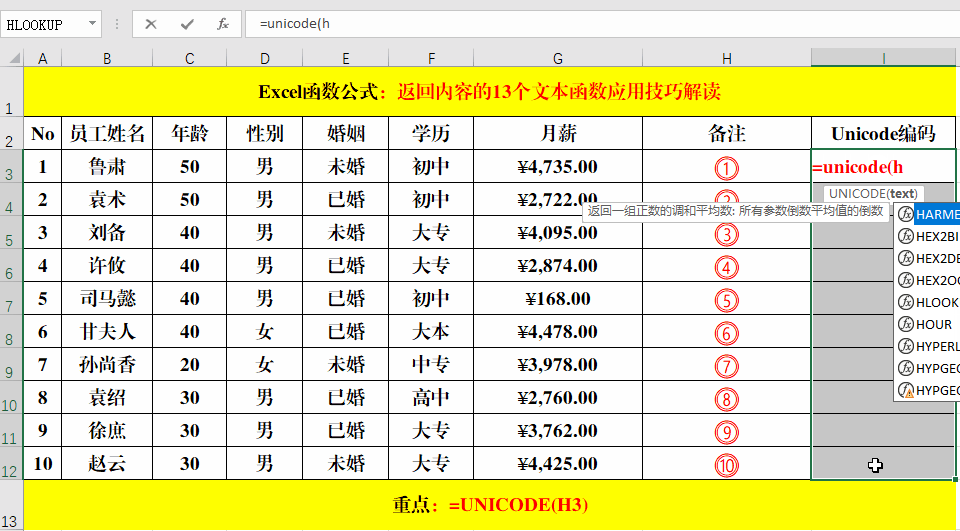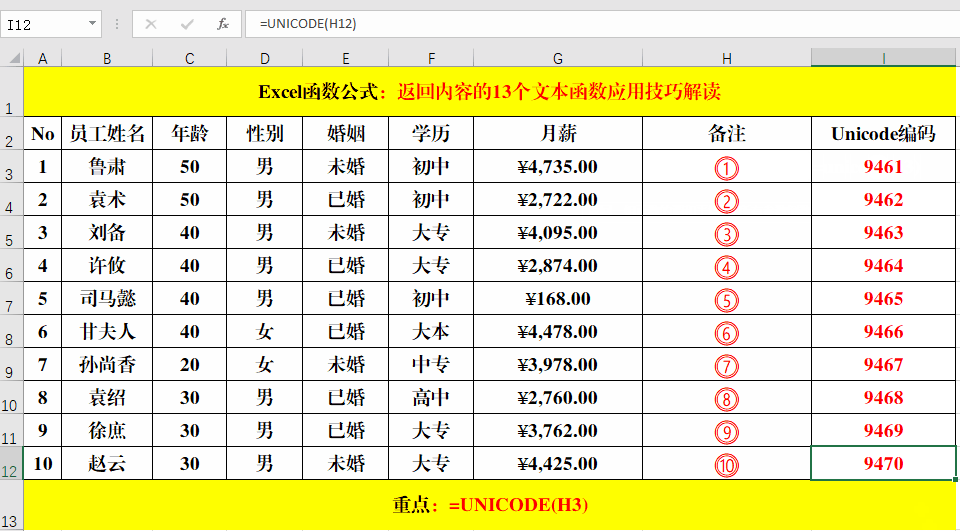
方法:
在目标单元格中输入公式:=UNICODE(H3)。
解读:
Unicode函数和Unichar函数的作用正好相反,Unicode根据文本返回Unicode编码,而Unichar根据Unicode编码返回对应的字符。
五、Left。
功能:从文本左侧起提取指定个数的字符。
语法结构:=Left(文本,[字符个数])。
注意事项:
1、参数“字符个数”必须大于或等于0,如果小于0,Left函数将返回“#VALUE!”。
2、参数“字符个数”等于0时,返回空文本,省略时,默认值为1。
3、参数“字符个数”大于文本的总长度,Left函数将返回全部文本。
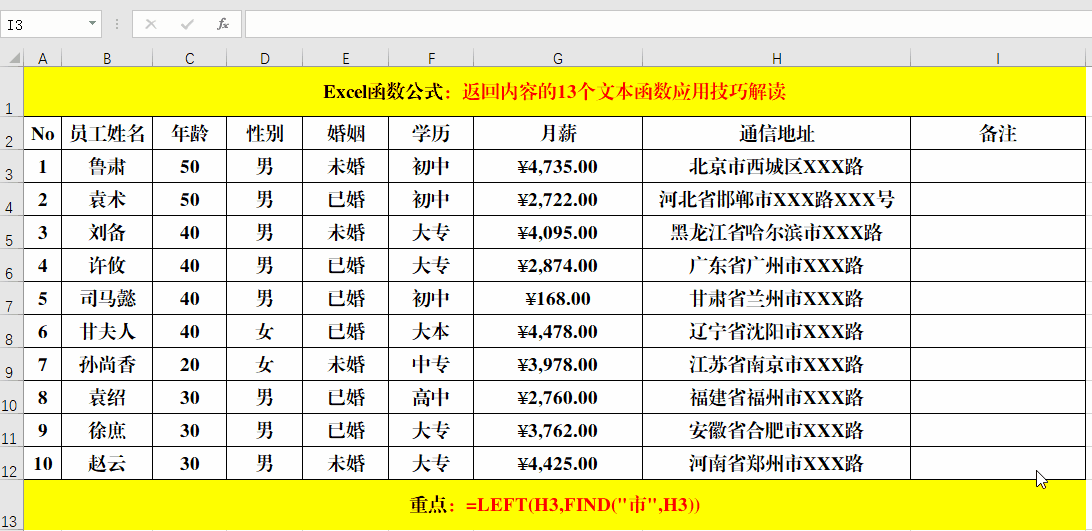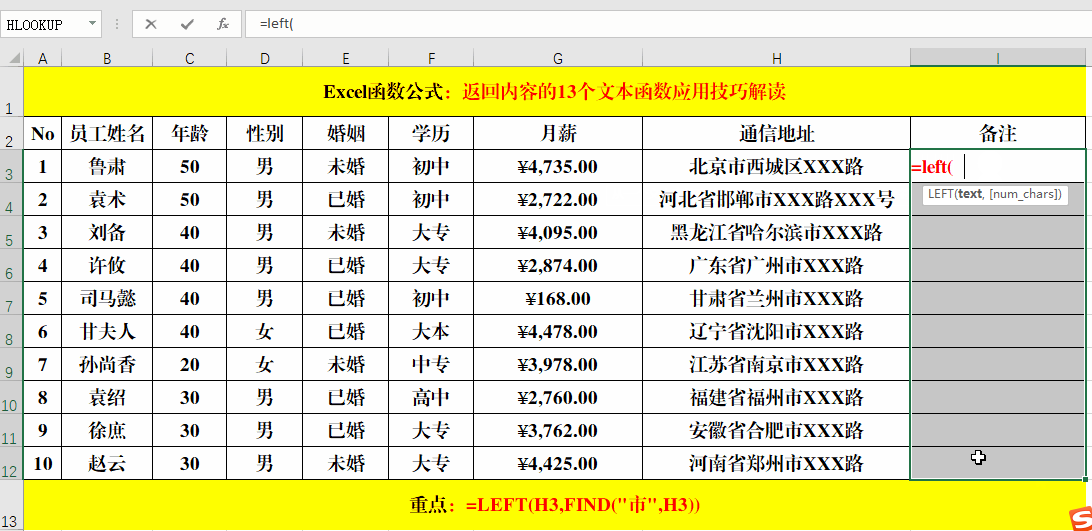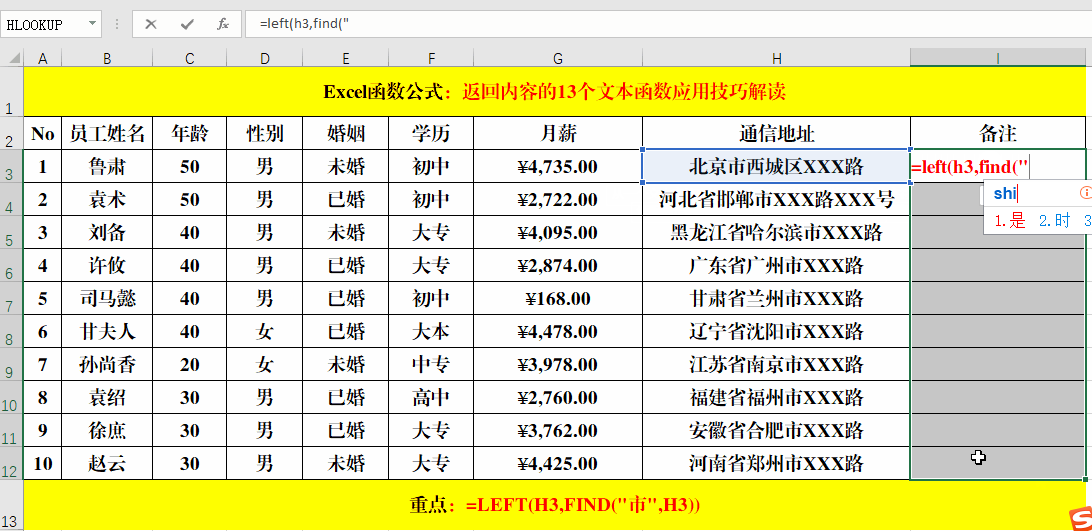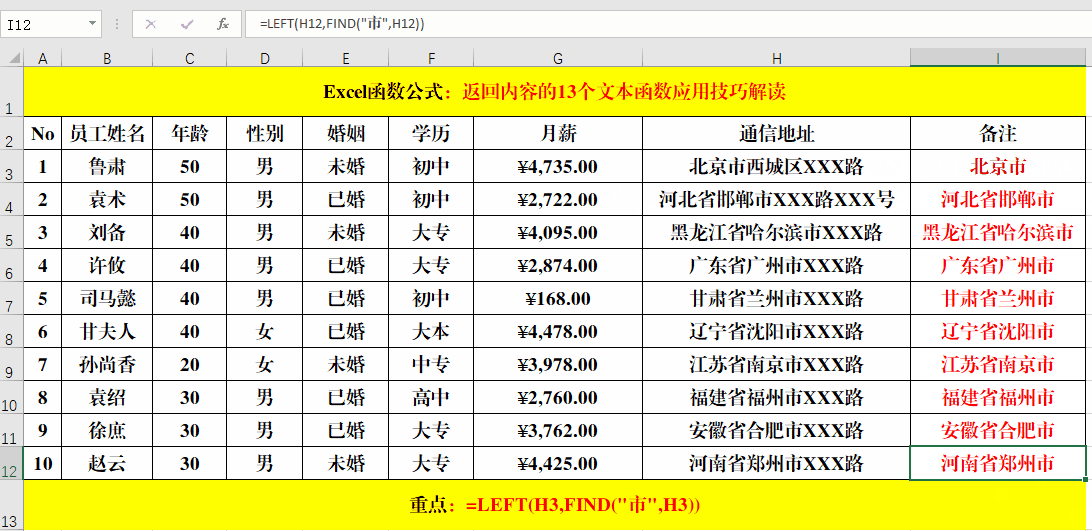
目的:提取地址中的省市名称。
方法:
在目标单元格中输入公式:=LEFT(H3,FIND("市",H3))。
解读:
1、Find函数的作用为:返回一个字符串在另一个字符串中的起始位置。
2、公式=FIND("市",H3)的作用就是返回“市”在H3单元格中第一次出现的位置,其结果作为Left函数的第二个参数,提取所需要的值。
六、Leftb。
功能:从文本左侧起提取指定字节数的字符。
语法结构:=Leftb(文本,[字节个数])
注意事项:
同Left函数,用法也相同,只是提取的字符长度按照字节来计算,全角字符为2个字节,半角字符为1个字节,汉字也为2个字节。
七、Len。
功能:计算文本中的字符个数。
语法结构:=Len(文本)。
注意事项:
Len函数的参数“文本”,除了文本值以外,还以是数字、单元格引用及数组。
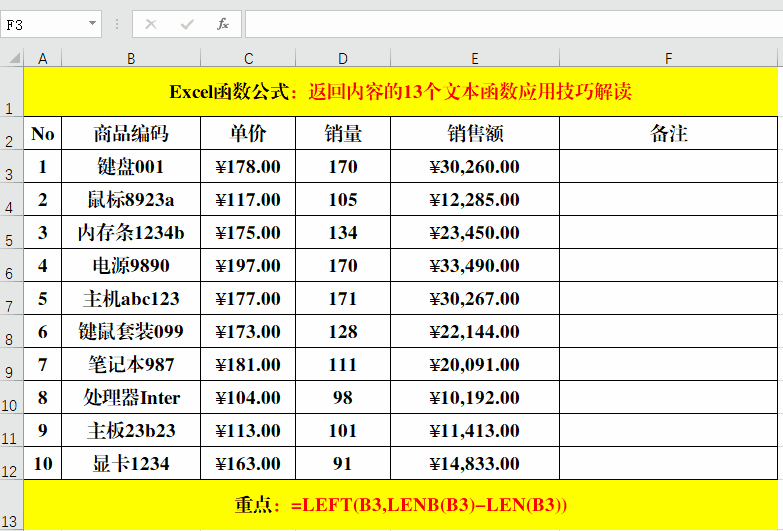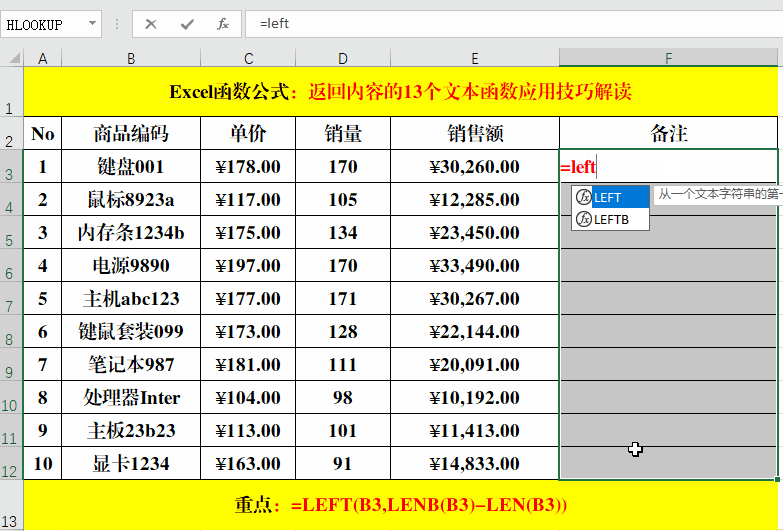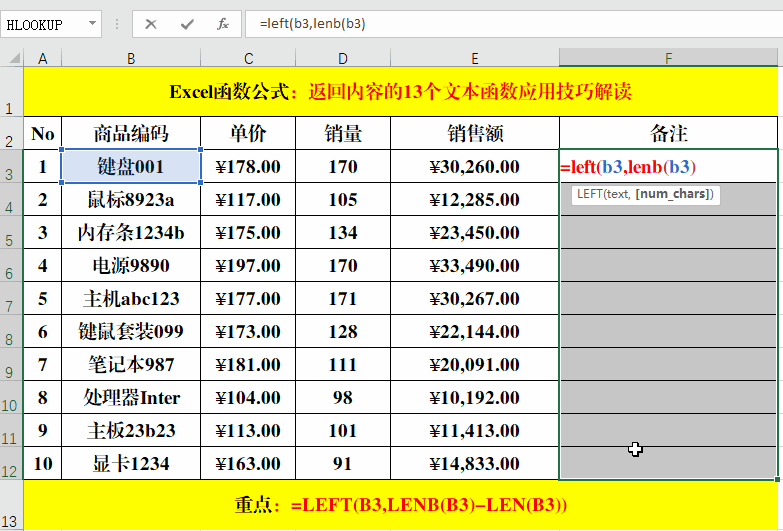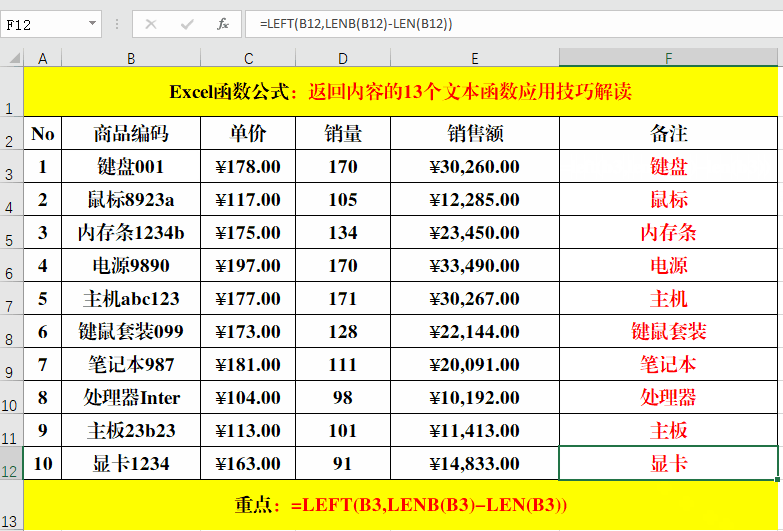
目的:从“商品编码”中提取“商品名称”。
方法:
在目标单元格中输入公式:=LEFT(B3,LENB(B3)-LEN(B3))。
解读:
1、Lenb函数的作用,请参阅下一示例。
2、如果要提取编码,可以使用公式:=RIGHT(B3,2*LEN(B3)-LENB(B3)),关于Right函数的作用及用法见下文。
八、Lenb。
功能:计算文本中代表字符的字节数。
语法结构:=Lenb(文本)。
注意事项:
请参阅Len函数。
九、Mid。
功能:从文本指定位置提取指定长度的字符。
语法结构:=Mid(文本,开始位置,提取长度)。
注意事项:
1、参数“文本”可以是文本值,也可以是数字、单元格引用或数组。
2、参数“开始位置”大于文本长度,Mid函数将返回空文本;如果小于1,返回错误值“#VALUE!”。
3、参数“提取长度”小于0,Mid函数将返回错误值“#VALUE!”。
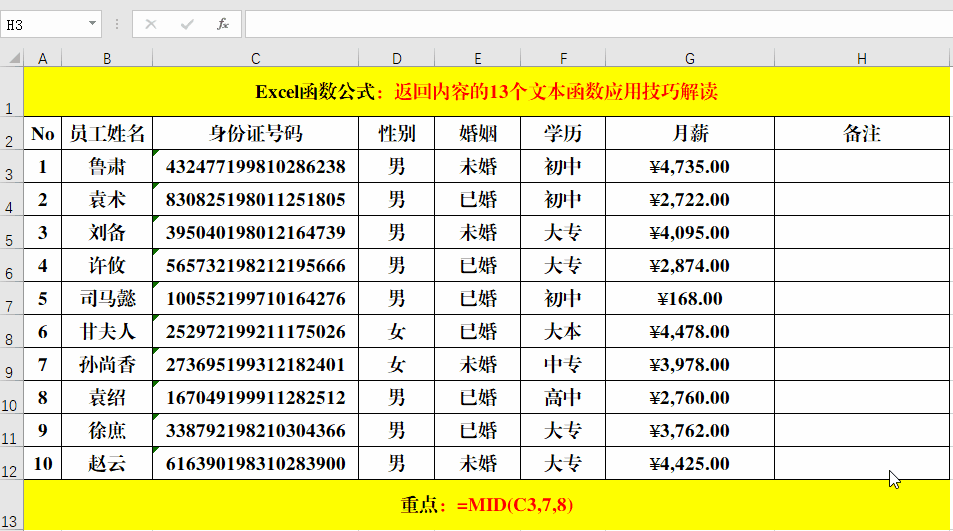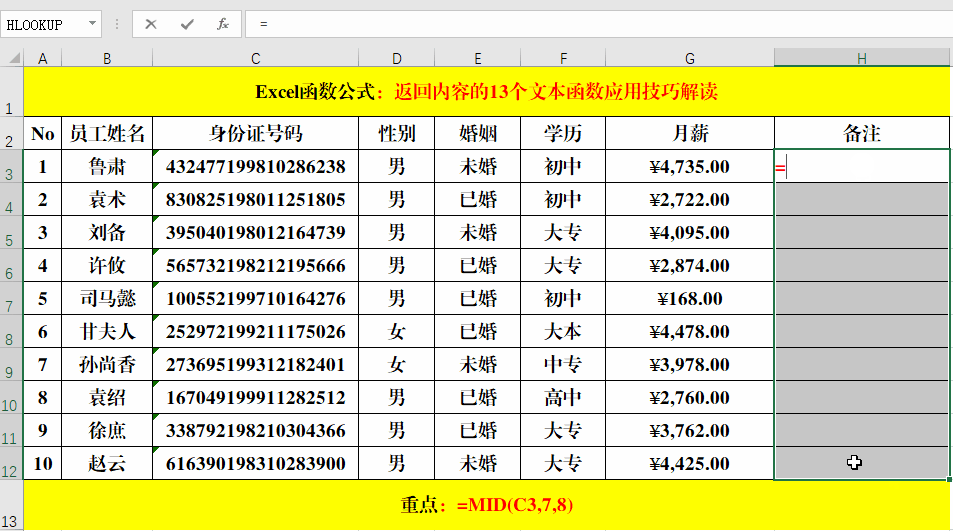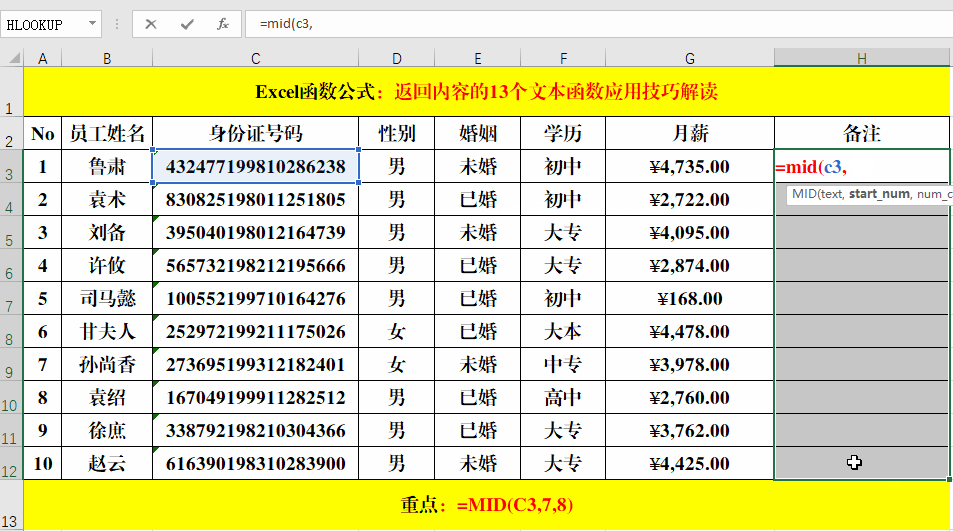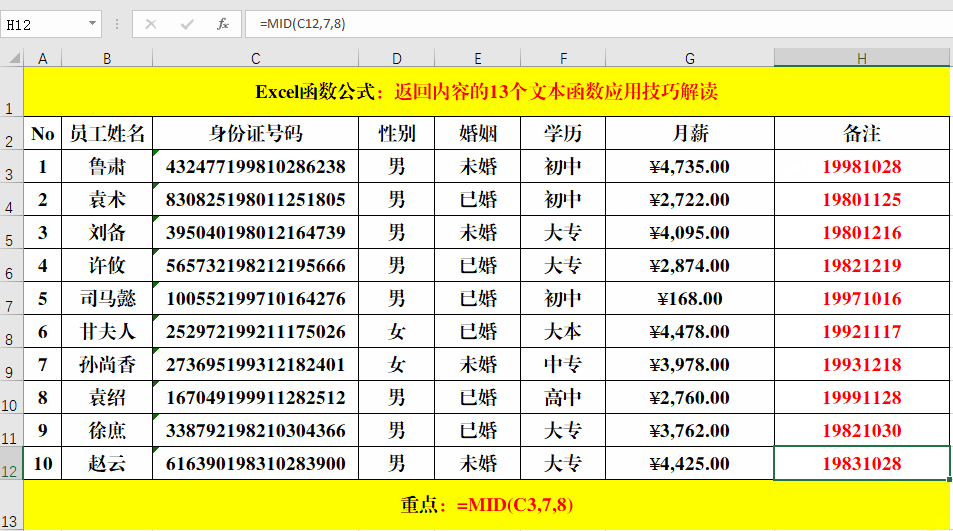
目的:提取身份证号码中的“出生年月”。
方法:
在目标单元格中输入公式:=MID(C3,7,8)。
解读:
1、示例中的“身份证”号码为随机生成数字,并不具有真实性。
2、从第7位开始,长度为8的数字是出生年月。
十、Midb。
功能:从文本指定位置起提取指定字节数的字符。
语法结构:=Midb(文本,开始位置,提取长度)。
注意事项:
1、参数“开始位置”、“提取长度”均按照字节数计算。
2、用法同Mid函数,不再赘述。
十一、Right。
功能:从文本右侧起提取指定个数的字符。
语法结构:=Right(文本,[字符长度])。
注意事项:
1、参数“文本”,除文本值外,还可以是数字、单元格引用或数组。
2、参数“字符长度”必须大于或等于0,如果小于0,则返回错误值“#VALUE!” ;如果等于0,返回空文本;省略时,默认值为1;如果大于文本的总长度,Right函数将返回全部文本。
目的:提取“商品编码”中除“商品名称”外的部分。
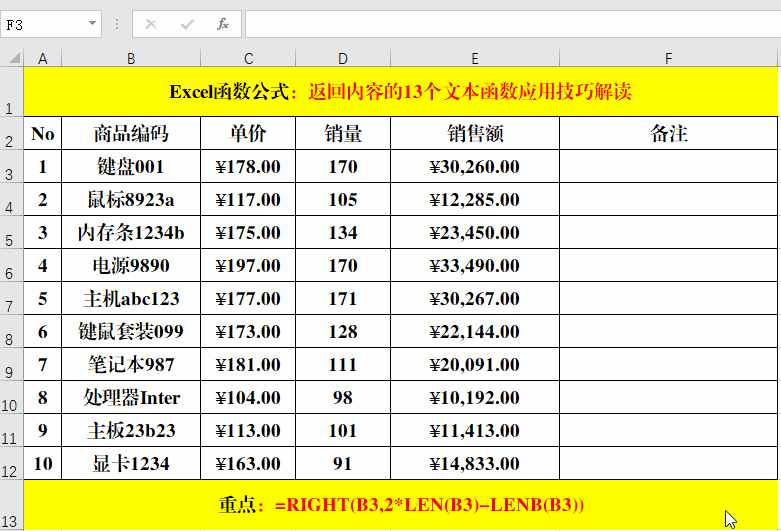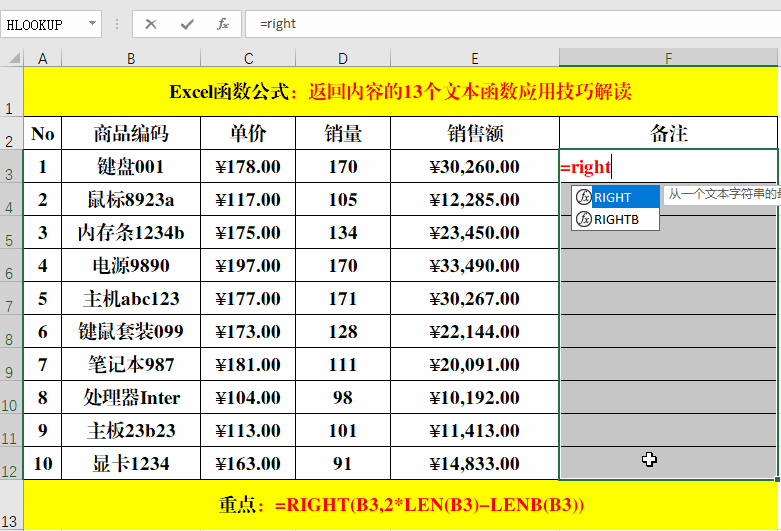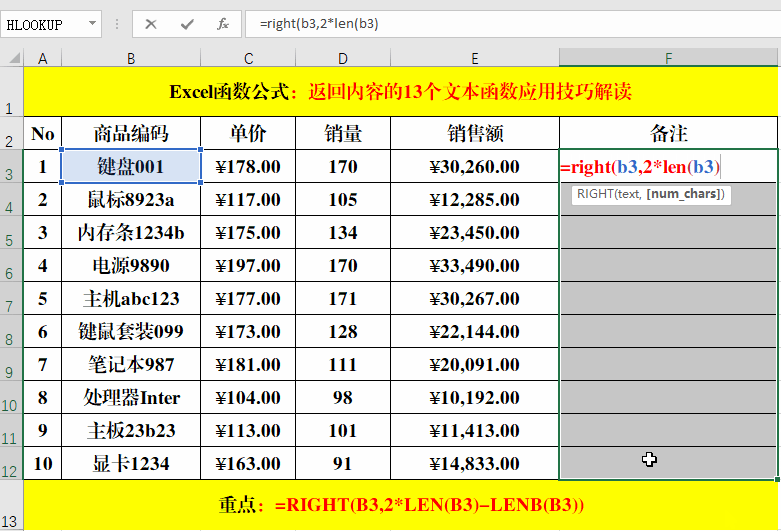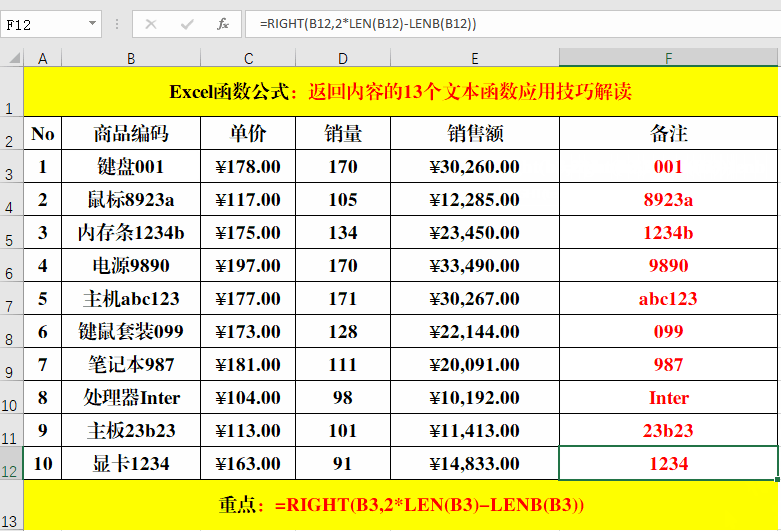
方法:
在目标单元格中输入:=RIGHT(B3,2*LEN(B3)-LENB(B3))。
十二、Rightb。
功能:从文本右侧起提取指定字节数的字符。
语法结构:=Rightb(文本,[字节长度])。
注意事项:
同Right函数,用法也同Right函数,不再赘述。
十三、Rept。
功能:生成重复的字符。
语法结构:=Rept(文本或字符,重复次数)。
注意事项:
参数“重复次数”为0时,Rept函数将返回空值;也不能超过32767,否则返回错误值“#VALUE!”。
目的:将“销售额”图示化。
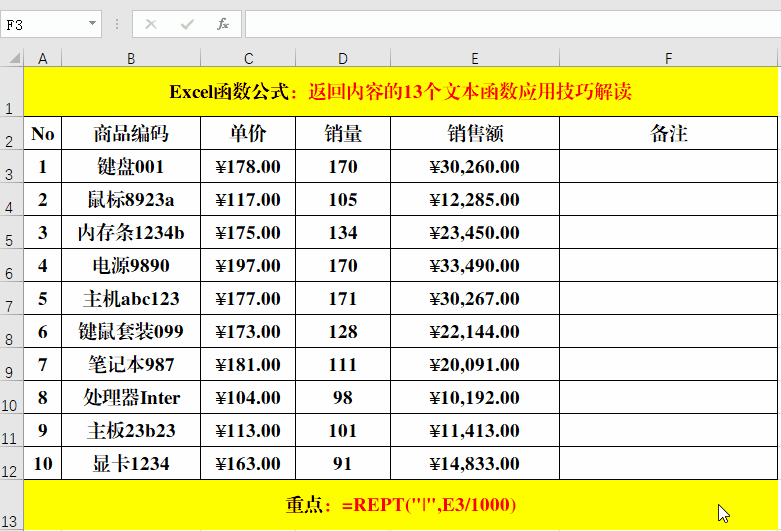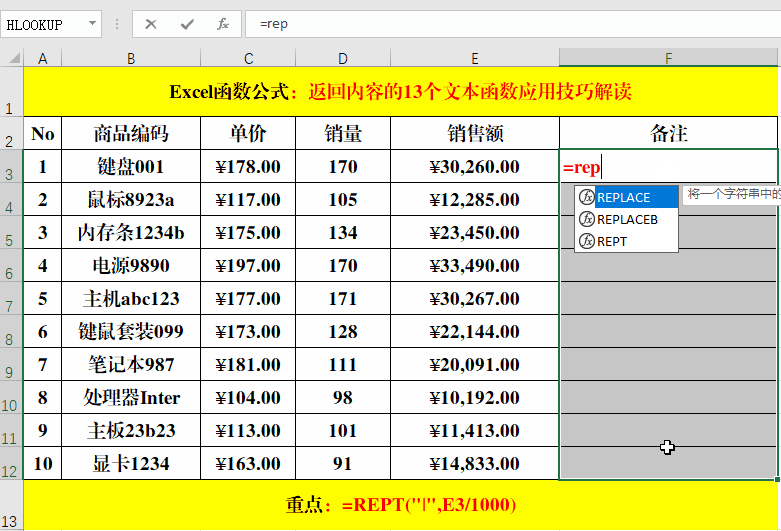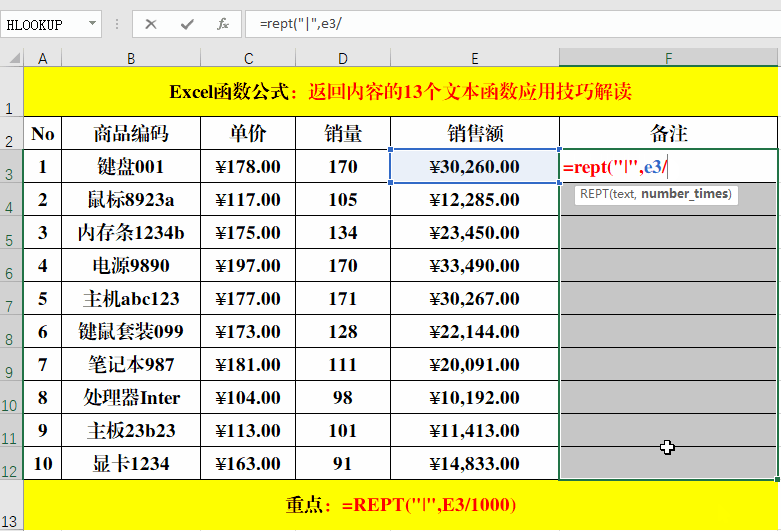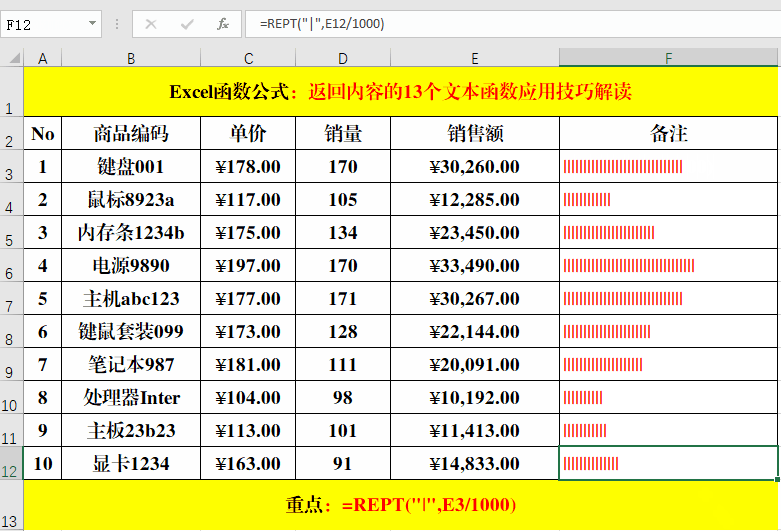
方法:
在目标单元格中输入公式:=REPT("|",E3/1000)。














 7637
7637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









