





SQL不是一门语言,而是一门手艺。
把SQL当手艺来学
1.行列过滤
2.数据变换
3.合并连接
4.聚合透视
奇怪的用法
把SQL当手艺来学
所谓手艺,要求心手相连,每一门手艺的背后,都闪现着手艺人的心血与智慧。SQL也是。
SQL: Structured Query Language,结构化查询语言。实际上也有戏称是标准查询语言的,并不为过,SQL诞生于1974年,基于关系数据库(也就是表格),发展至今毫无衰落迹象,反而渗透到各个数据处理工具/系统中:传统数据库、Hive数据仓库、MongoDB支持类SQL,甚至玩dataframe表格的R语言也可以通过sqldf包写sql,Spark、Flink也可以写SQL,等等。玩数据分析,学好SQL无往而不利。
如果把SQL当语言来学,那么学习路径是单词、语法、技巧,学完后一团乱麻

当手艺来学,就要先修内功——分析思路,再按分析所需的功能学用法,将会无比通畅。试想我们拿到表格形式的数据,要怎么操作分析?16个字:
行列过滤、数据变换、合并连接、聚合透视
以下以hive为例来说,先简化几个表:
1. 行列过滤
select seword --列过滤 from ks.selog where uid=1002 --行过滤 |
| 搞笑视频 |
从ks.selog表格中找出uid=1002的行中的 seword列。简直就是自然语言啊,你说气人不~
from一个表,select结果也是个表。
2. 数据变换
select os, case os when 'iphone' then 1 when 'android' then 2 end as osid from ks.selog |
iphone, 1 iphone, 1 android, 2 |
利用case-when将os变换成id。现在看这一串单词就不觉得头疼了吧。
大部分SQL教程会堆砌各种函数、语法,不怕,我们知道都是为了做数据变换,分门别类的来看:
- 字符串函数:
length(),变upper(),截substr(),拆split(),拼concat()…
- 数值计算:
+-*/模%,舍入round(),随机rand(),取整ceil()floor(),数学sin()…
- 日期函数:
year(),month(),day(),minute(),date_add()…
- json抽取:
get_json_object('{"button":"cancel"}','$.button') 得到cancel
- url参数抽取:
parse_url(a_url, 'HOST'), parse_url(a_url, 'QUERY' , 'speachid')
- 字典取KV:
event_urlparams['speachid']
- 数组取元素:
displayresult[1] 第一条展现结果
- if函数,case子句
- 类型转换: cast('2' as int)
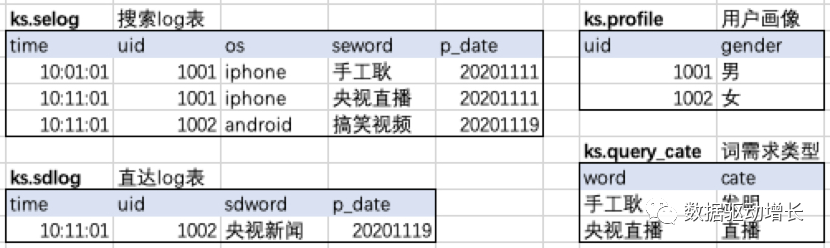
3.合并连接
select t1.uid, word, gender from ( select uid,seword word from ks.selog union all select uid,sdword word from ks.sdlog ) t1 join ( select uid,gender from ks.profile ) t2 on t1.uid=t2.uid |
1001,手工耿, 男 1001,央视直播,男 1002,搞笑视频,女 1002, 央视新闻,女 |
稍微复杂些了。来看其中的关键点,
union all ,将2个格式一致的select查询结果合并。
子查询 () t ,用括号包含查询语句并命名为t,查询结果是一个表格,这是一个隐含表,可以被select。
Join on,把2个表按某个字段连接起来,把右表中的信息连到左表上。
不沉溺于sql中的关键字,用输入一个表操作后输出一个表来看,画一下这个过程
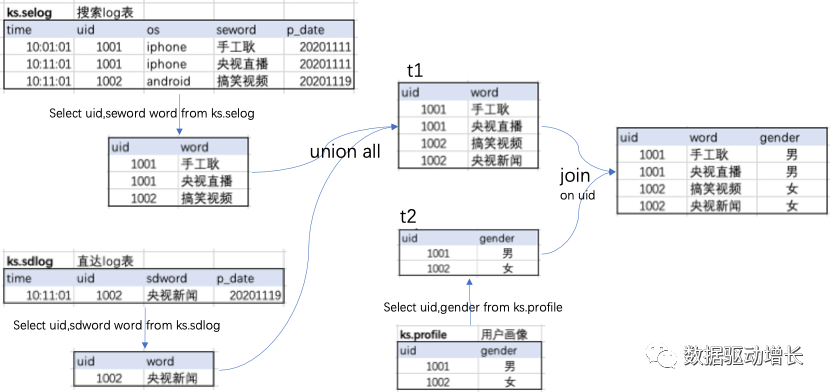
4.聚合透视
select os,sum(1) sepv,count(distinct uid) seuv from ks.selog group by os |
iphone, 2, 1 android, 1, 1 |
聚合指按某几列聚合group by,得到的结果是维度列os和指标列sepv计数、seuv去重计数。指标列由聚合函数计算得到,指标列可以直接计算。
透视不是sql强项,一般通过SQL得到聚合的数据,在Excel、Pandas进行透视
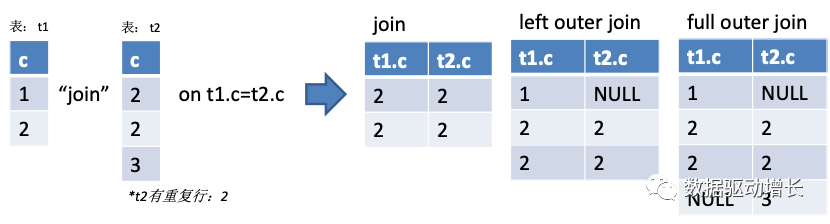
16字说完了,其中合并连接是最强大之处,多个表格在不同的地方,非常常见,在SQL里只管按需union join即可。union 好说,列名一致就行,join则会面临左右表要连接的字段参差不齐,也就引申出好多种join,只记基础的3种足够用
现在挑战一下
select gender,case when cate is NULL then '其他' when cate='发明' then '发明创造' else cate end as newcate, count(1) pv,count(distinct t1.uid) uv,count(1)/count(distinct t1.uid)/1000 avgpv_k, sum(if(t3.cate is NULL,0,1)) useless from ( select uid,upper(seword) word from ks.selog union all select uid,upper(sdword) word from ks.sdlog ) t1 join ( select uid,if(gender is not NULL,gender,'') gender from ks.profile ) t2 on t1.uid=t2.uid left outer join ( select distinct word,cate from ks.query_cate ) t3 on t1.word=upper(t3.word) group by gender,case when cate is NULL then '其他' when cate='发明' then '发明创造' else cate end |
现在看这一坨臭长的中英文字符还是乱码吗?
[我们理解了1+1=2,那么就很容易理解复变函数和切比雪夫不等式啦 @_@||-_-||]
奇怪的用法
qg1:透视
为了吹SQL,还是写一下sql的透视,闲的慌
select os, count(if(p_date=20201111,seword,NULL)) c20201111, count(if(p_date=20201119,seword,NULL)) c20201119 from ks_mmu.selog group by os |
啥时候会这样枚举结果列?比如数据量很大,Excel搞不定了,又很明确有哪些列可以枚举。比如要对一天内用户的活跃小时进行聚类分析,要得到 就可以这样写sql。
qg2:hive借java能力做数值变换
| select reflect("java.lang.Math", "round", 2.5) |
就问骚气不骚气~
qg3:写python代码嵌入sql执行
# python代码,存储为 x.py import sys os_id={"iphone":1, "android":2} for line in sys.stdin: fs=line.rstrip("\n").split("\t") os=fs[0] osid=os_id.get(os, 0) print "%s\t%s"%(os, osid) |
hive -e" add file ./x.py; --定位到所写脚本 select TRANSFORM(os) -- 将原始列传给x.py USING 'python x.py' --用x.py逐行处理并输出 as (os string,osid string) --脚本输出的\t分割的各列新名字 from ks.selog --其他sql语法不变 " |
iphone, 1 iphone, 1 android, 2 |
再问是不是更骚气~
qg4:行列互转

最后总结一下:
1.行列过滤
2.数据变换
3.合并连接
4.聚合透视
这不是一篇教程,要教程是官网看,详细到每一个关键字,够看好几天;
这只是一个视角。
不要满脑子想select from where group,而想我要对表格的数据做什么,SQL这个工具能帮我,工具练熟了心手合一,就掌握了一门手艺。
荒年饿不死手艺人















 4369
4369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









