





生成对抗网络(GAN)是一组用于生成合成数据的深度神经网络模型。该方法由Ian Goodfellow在2014年开发,并在“ 生成对抗网络 ”一文中进行了概述。GAN的目标是训练鉴别器,使其能够区分真实数据和伪造数据,同时训练生成器以生成可以可靠诱骗鉴别器的数据综合实例。
GAN的一个流行应用是在“ GANgough”项目中,由受过wikiart.org绘画培训的GAN生成合成绘画。独立研究员肯尼·琼斯(Kenny Jones)和德里克·波纳菲利亚(Derrick Bonafilia)能够以令人印象深刻的性能生成合成的宗教,风景,花卉和肖像图像。文章GANGough:使用GAN创建艺术详细介绍了该方法。在本文中,我们将逐步介绍用python构建基本GAN的过程,该过程将用于生成手写数字的合成图像。
让我们开始吧!
首先,让我们导入必要的软件包。让我们首先导入“ matplotlib”,“ tensorflow.keras”层和“ tensorflow”库。我们还定义一个变量,我们可以使用该变量来存储和清除会话:
import matplotlib.pyplot as pltfrom tensorflow.keras import layersimport tensorflow as tffrom tensorflow.python.keras import backend as KK.clear_session()接下来,让我们加载“ MNIST”数据集,该数据集在“ tensorflow”库中可用。数据包含手写数字的图像和与数字相对应的标签:
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()让我们看一下训练数据中的第一个图像:
plt.imshow(train_images [0],cmap ='gray')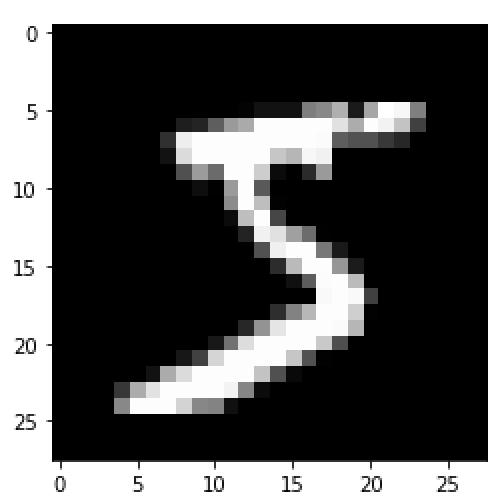
我们可以看到这是一个手写的“ 5”。接下来,让我们重塑数据,将图像像素转换为浮点值,并将像素值归一化为-1和1:
train_images = train_images.reshape(train_images.shape [0],28,28,1).astype('float32')train_images =(train_images-127.5)/ 127.5现在让我们定义生成器模型:
def generator_model(): model = tf.keras.Sequential() model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,))) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Reshape((7, 7, 256))) assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)) assert model.output_shape == (None, 7, 7, 128) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)) assert model.output_shape == (None, 14, 14, 64) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')) assert model.output_shape == (None, 28, 28, 1) return model我们首先初始化一个顺序模型对象。然后,我们添加第一层,这是一个普通的密集神经网络层。还有一系列转置的卷积层,它们是带有填充的卷积层。对于那些不熟悉的人,卷积层学习权重的矩阵(内核),然后将其合并以形成用于特征提取的过滤器。通过学习过滤器权重,卷积层可以学习卷积特征,这些卷积特征代表有关图像的高级信息。通过学习的滤波器,这些层可以执行诸如边缘检测,图像锐化和图像模糊之类的操作。这些是计算机视觉中内核矩阵的一些示例:

如果您有兴趣,可以在此处了解有关卷积神经网络的更多信息。还有一系列泄漏的“ ReLu”层:
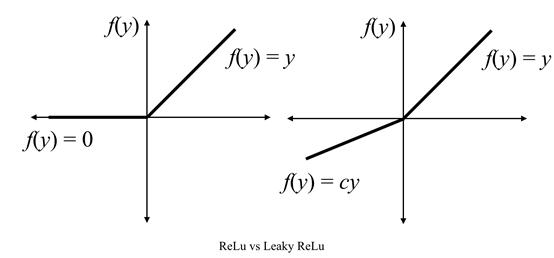
这些是经过修饰的“ ReLu”激活,可通过增加“ ReLu”功能的范围来帮助缓解垂死的神经元问题。还有批量归一化层,用于固定每一层输入的均值和方差。这有助于提高神经网络的速度,性能和稳定性。
生成器和鉴别器网络以与普通神经网络类似的方式进行训练。即,权重被随机初始化,损失函数及其相对于权重的梯度被评估,并且权重通过反向传播被迭代地更新。
训练过程将帮助生成器模型从噪声中生成真实外观的图像,并且判别器在检测看似真实的伪图像方面做得更好。让我们看一下生成器模型的输入示例。首先,让我们定义发生器并初始化一些噪声“像素”数据:
generator = generator_model()noise = tf.random.normal([1, 100])接下来,让我们将噪声数据传递到我们的“ generator_model”函数中,并使用“ matplotlib”绘制图像:
your_session = K.get_session()generated_image = generator(noise, training=False)array = generated_image[0, :, :, 0].eval(session=your_session)plt.imshow(array, cmap='gray')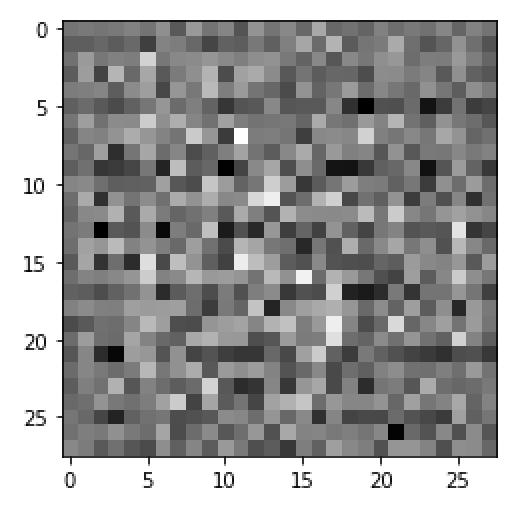
我们看到这只是一个嘈杂的黑白图像。目标是让我们的生成器学习如何通过迭代训练这些嘈杂的数据来生成数字的真实外观的图像,就像我们之前绘制的那样。经过充分的培训,我们的生成器应该能够从嘈杂的输入中生成真实的手写数字,如上面所示。
现在让我们定义鉴别函数。这将是用于分类的普通卷积神经网络:
def discriminator_model(): model = tf.keras.Sequential() model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1])) model.add(layers.LeakyReLU()) model.add(layers.Dropout(0.3)) model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')) model.add(layers.LeakyReLU()) model.add(layers.Dropout(0.3)) model.add(layers.Flatten()) model.add(layers.Dense(1)) return model接下来,让我们定义损失函数和鉴别对象:
discriminator = discriminator_model()cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits = True)接下来,我们定义特定于鉴别器的损失函数。此功能衡量鉴别器能够区分真实图像和伪图像的能力。它将鉴别器的二进制预测与真实图像和伪图像上的标签进行比较,其中“ 1”对应于真实,“ 0”对应于伪造:
def discriminator_loss(real_output, fake_output): real_loss = cross_entropy(tf.ones_like(real_output), real_output) fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output) total_loss = real_loss + fake_loss return total_loss发电机损耗函数用于衡量发电机欺骗鉴别器的能力:
def generator_loss(fake_output): return cross_entropy(tf.ones_like(fake_output), fake_output)由于生成器和鉴别器是独立的神经网络,因此它们每个都有自己的优化器。我们将使用“ Adam”优化程序来训练我们的鉴别器和生成器:
generator_optimizer = tf.keras.optimizers.Adam(1e-4)discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)接下来,让我们定义历元数(即训练数据上的通过次数),噪声数据的尺寸大小以及要生成的样本数:
EPOCHS = 50noise_dim = 100num_examples_to_generate = 16然后,我们为训练循环定义功能。'@ tf.function'装饰器编译函数。'train_step()'函数通过从随机噪声生成图像开始:
@tf.functiondef train_step(images): noise = tf.random.normal([BATCH_SIZE, noise_dim]) with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: generated_images = generator(noise, training=True) #random seed images然后使用鉴别器对真实和伪造图像进行分类:
@tf.functiondef train_step(images): ... real_output = discriminator(images, training=True) fake_output = discriminator(generated_images, training=True)然后,我们计算生成器和鉴别器的损失:
@tf.functiondef train_step(images): ... gen_loss = generator_loss(fake_output) disc_loss = discriminator_loss(real_output, fake_output)然后,我们计算损失函数的梯度:
@tf.functiondef train_step(images): ... gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables) gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)然后,我们应用优化器找到使损失最小的权重,并更新生成器和鉴别器:
@tf.functiondef train_step(images): ... generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables)) discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))接下来,我们定义一种方法,该方法将允许我们在训练完成后生成伪图像并将其保存:
def generate_and_save_images(model, epoch, test_input): predictions = model(test_input, training=False) fig = plt.figure(figsize=(4,4)) for i in range(predictions.shape[0]): plt.subplot(4, 4, i+1) plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray') plt.axis('off') plt.savefig('image_at_epoch_{:04d}.png'.format(epoch)) plt.show()接下来,我们定义一种训练方法,该方法将允许我们同时训练生成器和鉴别器。我们从迭代历元数开始:
def train(dataset, epochs): for epoch in range(epochs):在历元循环内,我们生成图像:
def train(dataset, epochs): ... display.clear_output(wait=True) generate_and_save_images(generator, epoch + 1, seed) display.clear_output(wait=True) generate_and_save_images(generator, epochs, seed)最后,我们可以使用epochs参数在训练数据上调用“ train()”方法:
train(train_dataset, EPOCHS)如果我们用两个时期来运行代码,我们将获得以下伪图像输出:

我们看到输出仍然非常嘈杂。经过50个纪元后,我们应该生成以下图表(请注意,在具有16 G内存的MacBook Pro上运行需要花费几个小时):

正如我们所看到的,有些数字是可以识别的,而另一些数字则需要更多的培训才能提高。可以推测,随着时间的推移,数字看起来会更加真实。我将在这里停止,但您可以随意使用数据并自己编写代码。您可以使用许多其他数据集来训练GAN,包括Intel图像分类数据集,CIFAR数据集和Cats&Dogs数据集。其他有趣的应用包括深层伪造视频和深层伪造音频。
要开始对视频进行GAN培训,您可以查看白皮书《复杂数据集的对抗视频生成》。在本文中,作者在UCF-101动作识别数据集上训练了GAN ,其中包含来自YouTube的101个动作类别中的视频。要开始对GAN进行音频培训,请查阅“ 对抗性音频合成”一文。在本文中,作者训练了GAN上的语音指令“一到九”,其中包含鼓声,鸟叫声等。
结论
总而言之,在本文中,我们讨论了生成对抗网络(GAN)以及如何在python中实现它。我们表明,GAN同时训练两个神经网络,一个用于数据生成,另一个用于数据判别。鉴别器和生成器的层最明显地分别包含转置卷积层和普通卷积层,它们学习图像的高级特征表示。我鼓励您尝试在其他一些有趣的数据上训练GAN,例如我上面提到的语音或视频数据集。我希望您发现这篇文章有用/有趣。这篇文章中的代码可在GitHub上找到。感谢您的阅读!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









