






想真正掌握索引底层并不是空穴来风,原理看了又看,结果用不出来,解决不了问题,都是很多人的心病。说得简单是你并没有真正掌握和运用它,没有考虑应用场景,也没有思考空间结构。
就算你背的再多,给你一个问题,你还是不能求解。故此原理只是你进阶第一步,熟练用到工作中,才能真正的 Get 它。不要只是纸老虎的耀武扬威,那要怎么做呢? 咱们先看文章
01 什么是索引优化?
索引优化是针对在创建、使用索引过程中的优化方案,通过优化可大幅度提高索引查找效率、降低维护成本、满足业务需求等。可有的兄弟姐妹就说索引不就是建立后直接使用吗?干嘛优化它!真是浪费我心情你这个想法,顶多只能算使用。
如果这样即可满足开发需求,为啥你 Leader 面试你,还需问你索引底层、原理细节、技术方案等 结果整得你是心力交瘁、战战兢兢的直冒冷汗。何必这样难为你 ?

例:同样是咖啡,为啥速溶咖啡和星巴克的咖啡不一样?
后者注重整个流程的制作工序,从挑选咖啡豆,磨粉,过滤,加入纯牛奶、可可粉、白砂糖等,犹如艺术品。而你速溶咖啡直接就看混搭+搅拌,能有啥?只要有味道,就不看质量。注重工序有啥好处?
如果你想要改善口味,那你直接去调味环节中搭配,如你想降低成本,可优化制作工序和材料。而索引优化也是从创建、使用过程中去考虑。 那你不知道,就没法改变。好似你喜欢的女子对你爱答不理,结果只能日渐消瘦。
02 为什么要索引优化?
如要优化,应该如何着手优化?到这里咱们得喝杯茶来洽谈一下索引的前世今生!
索引本质就是通过列数据构建成的B+树结构。随着数据量的增加就会存在到以下问题:
- 列数据太长,维护成本高
针对列数据,可分为单列、多列
如果创建单例索引时,需要索引很长的字段列,例如像对于BLOB、TEXT或者很长的VARCHAR类型的列,这样就会导致索引查找变得很慢。因为该字段的值作为 B+Tree 每个节点下的元素。那么对索引来说就有如下缺陷:
- 单列数据太长,整个节点下容纳的元素就会减少。这样就需要更高的节点树来容纳整张表的元素。 要么你就胖,要么你就瘦。
- 索引查找对比时,先拿到 where 条件后面携带的数据,分别取其数据中的每个字母和元素一 一对比,对比时直接根据 ASCII 码值来判断。那数据是中文怎么来操作呢? 通过 Unicode 编码比较,先把中文转化为编码,然后对比其结果值。
- 咱们前面说过,索引的维护是通过 MySQL 后台任务线程自动创建维护整颗树,如果你元素太长,那插入过程:1.需要自上而下查找插入叶结点位置;2.自下而上分裂满结点。可以对该过程稍作修改,如果你元素长,维护的成本会增加。索引空间也增加了。
这也是为什么索引要选好字段来创建索引,现在明白没?
如果换为联合索引,多个字段共同组成,如果一个索引列太长,这个整体也会增大。这就是为啥团队里面,一个人掉队,瞬间就拉低平均分啦!

- 索引本身会存在索引碎片
那什么是索引碎片呢? 就是把紧凑的索引分散到多个页中去
先来个例子:一个阳光明媚的早晨,清脆的鸟叫声犹如空谷传音般回荡在你脑海,就在此时,忽然听到高考结束了,多少号来填写志愿几个字,飘进到你耳朵里。顿时一机灵。内心无比激动,感觉浑身有使不完的劲。网吧里面的键盘正欠你啪啪的敲打。看着你桌面上折磨了你3年的书本,感觉此刻达到了人生巅峰,今天你就是那最靓的仔。此后你不在需要它们的陪伴,挥手道别,扬长而去。发泄吧 ,少年。心中的恨意犹如通过任督二脉汇聚到你手中,直接三下五除二的撕碎着它们的皮肤。直接从5层高的教学楼,撒下到大地。书本的碎片感觉是失了智一样。飘荡到了各个角落。就在这时,猛虎般的咆哮声响彻整个校园。原来扫地的大妈又在开始骂娘啦! 因为去年就听到过,只是现在的主角换成了你。 立马灰溜溜的走掉。
这就碎片的危害,你撕的舒服,但是打扫起来就很麻烦。如果索引的全部数据可以在6个页面里保存。因为索引碎片的原因分散到了12个页里面。那当查询扫描索引时,需要读取12个页面,而不是6个页面,增加了近50%的IO。
这是何等的可怕。并且你锁片似的索引也会降低 MySQL 缓冲区缓存效率,还需占据更多内存空间。 碎片页多了也会增加数据库文件。需要更多的空间来存储额外页,并、降低备份和还原性能。那这个是怎么产生的呢?咋解决呀? 别着急,后面安排
- 冗余、重复索引,结果没太多意义
最不想做的事情就是重复的内容,费时又费力,还不能够提示自己的能力那什么是重复索引?
重复索引是指在相同的列上按照相同的顺序创建的相同类型(指索引底层结构)的索引。应该避免这样创建重复索引,发现以后立即移除,绝不含糊。 因为创建索引后需要 MySQL 单独进行索引的维护,并且优化器在优化查询的时候也需要逐个地进行考虑,就会影响性能。 毕竟你创建一列的索引,那就是种了一个树啊 。 你种下的树,你难道不去栽培吗?
可能有的人说唯一和普通索引是不一样类型的啊,这样还是重复索引?如果你这样理解,那你得看看小哥哥下面的文章。
比如:
CREATE TABLE test
(ID INT NOT NULL PRIMARY KEY,
A INT NOT NULL,
B INT NOT NULL,
UNIQUE(ID),
INDEX(ID)) ENGINE=InnoDB ;这些索引类型的本质都是B+Tree。那是不是一样啦? 再者说,你唯一和普通索引的效率能有主键找的快 ?如果你换成T-Tree、FULLTEXT、Hash倒是可以。
那冗余索引是不是和重复索引一样啊! 数据库里面不是会设计表存储冗余数据吗? 如果这么理解说明你是个爱学习的好孩子,但是还需要改善,为啥?
针对表来看,你每个表的字段还是一个啊,那索引同样也是一样的。
比如:创建了索引(A, B), 再创建索引(A)就是冗余索引,因为这只是前一个索引的前缀索引。因此索引(A, B)也可以当作索引(A)来使用(这种冗余只是对B-Tree索引来说的,这里思考下有收获额!)。但是如果再创建索引(B, A)、索引(B),也不是冗余索引,为什么呢?
因为B开头的索引不是索引(A, B)的最左前缀列。另外,其他不同类型的索引(例如哈希索引或者全文索引),无论覆盖的索引列是什么,也不会是B-Tree索引的冗余索引。总结下:就是交集的关系,以最左开始的索引产生的交集,就是冗余索引。那Hash、全文有冗余索引吗? 期待你的回答

可能在你脑袋热的情况下,稀里糊涂创建的索引,后面在 SQL 语句的查询条件下根本就没使用过。反而是浪费空间、资源,这时候应该果断的删除。不然就是你提升性能的累赘。
就好比如:明知天要下雨,你还不带把伞呀。 别人不喜欢你,你怎么对别人说、怎么做那都没用。你得展示出你的价值,这样才能让别人注意到你。又教给了大家一招!
03 你对索引优化的理解是什么
针对索引理解其实可分为成本与应用技巧上。索引本身就是提升查找效率,如果因为使用它的成本过高反而造成查询效率降低,那就违背了我们使用它的初心。在 SQL 应用层面未使用到的话,或者效果不好,那也没发挥出它的作用。相当于有再好的工具,也落实不到下来,空谈而已。如果能够在有限的成本下发挥更高的性能。这就能够更好的体现出索引的价值。但是如果无用,反而还影响性能。应用技巧和成本控制那都是相辅相成的,就好比如技术是为了实现更产品,而产品是为了推动技术。
04 索引优化要怎么入手?
- 针对字段需要索引很长的字符列问题,有以下方案解决:
前缀索引与索引选择性
默认索引是选择字符列的全部,那可以只选择索引开始的部分字符,这样就减少了索引的空间,从而提高索引效率。但这里有一个关键,是什么呢?那就是会降低索引的选择性。索引的选择性是指,不重复的索引值( 也称为基数,cardinality)和数据表的记录总数(#T) 的比值,范围从I/#T到1之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。
索引选择性好比如:你找的女朋友是个双胞胎姐妹,很多时候出现认错人的情况!
放眼到索引里面,相当于是做了全表扫描。为啥呀!索引不是B+Tree的结构吗?
因为相同的太多,你得需一个个的拿出来后,在与你 where 中的查询条件做对比,直到满足条件。这也是为什么主键、唯一索引的选择性是最好的,因为它是1,那自然性能也最好。那这前缀怎么来选择呢?
诀窍就在于选择足够长的前缀以保证较高的选择性,同时不能太长。计算列的选择性,使得前缀选择性接近于完整列的选择性。从而代替列。如下:
select count(DISTINCT 索引列) / count(*) from table; //字段不重复数据,所占表数据的比例值 select count(DISTINCT LEFT(索引列, num)) / count(*) from table; #逐步增大索引列长度(num),直到这个比例值接近上面所占表数据比例。
最终你就能拿到最适合的长度来作为前缀索引。 伪哈希索引
怎么个hash索引法? 你给我谈谈
此hash非彼Hash,这里指的是自定义hash索引,在你的数据表中创建一个字段,专门用于存储哈希值。前面谈到了hash中key存储的是槽,这个槽用 int 表示的。这是不是比字符串的字符要减少索引空间啦,并且你查询的时候照样是基于B+Tree 进行搜索。只是用这个用哈希值来进行对比。所以你要做的就是在 where 字句中手动加入哈希函数。那这个hash值怎么来呢?
你可以采用hash函数对插入数据做运算,然后把结果存储到对应的字段里面就可以了。但是这个函数选择生成为数字的比较好,不然就太费计算、存储的资源啦。例如:CRC32

- 索引顺序安排
上面所讲解的内容在联合索引下面同样适,但是在联合索引下面,就需要考虑到索引列的顺序,因为查询时需满足最左匹配来使用命中索引,如果顺序不对,那么是不会命中索引的。而且采用索引查询结果的排序也会基于字段列顺序排列。那如何选择合适的顺序?
这还是得需看场景需要。经验是将选择性最高的列放到索引最前列。 但更要的是避免随机I/O和排序的情况。如果你指定创建的索引列的基数本身就比较大或者接近于表中所有行,这时候创建索引页没太大用。这时候应该在应用层取消对这种类型查询,而改为其它类型做查询条件。
- 优化排序
每次查询后的数据都会在内存中做好排序后在返回给客户端,如果小数据集查询还好,那如果是上百万、千万的数据行呢?
这时如果在存储引擎里面获取数据时,就能通过索引排序的方式把检查的数据找到。就能避免默认找到结果集之后,在进行 order by操作,从而提升效率查询的效率。
例如:针对那种选择性低的列,就可以创建索引来做排序,像(sex , rating)
SELECT <cols> FROM profiles WHERE sex = 'M' ORDER BY rating LIMIT 100000, 10;那这里的索引排序有没得要求呢?
只要在索引列的顺序和order by字句的顺序完全一致 ,并且所有列的排序方向(倒叙或正序)都一样时。才能用索引扫描进行排序。 如果查询需关联多张表,则只有当order by字句应用的字段全部为第一张表时,才能使用索引排序。而且order by 也需要满足前缀索引的要求。在这里需要额外强调一种情况,可以走索引查询,但是不能索引排序。
例如:联合索引(`is_role`, `role_name`, `role_status`)
EXPLAIN SELECT * FROM tp_user_role where is_role = 1 AND role_status =1;
因为不满足联合索引顺序,所以不走索引排序,但还是会触发索引。只不过是索引的第一列。这样对于指定索引列条件查询就有很大的损失,因为根据第一列索引查找的内容,对于第二、三列的数据就没在索引查找时互相匹配了。这样还需要在内存中做 where 条件筛选操作。
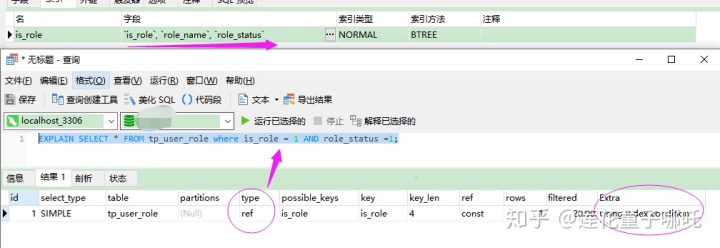
大家要特别注意最左配规则,面试经常考呀! 记住最左匹配开始,然后出现多个字段,就按照顺序进行对比,如果跳过中间的,那索引对比就会断开,只使用第一列的。
- 减少冗余与重复索引
一般冗余索引通常发生在为表添加新索引时, 但新增索引可能会导致 INSERT、UPDATE、DELETE 等操作更慢。所以在有新增索引需求时,应首选扩展索引而不是直接添加索引。那什么是扩展索引呢?创建索引时不依赖于现存索引列作为最左列。例如:现有索引(A),增加一个新的索引(A,B),这就是一个冗余列。所以可创建索引(B)或者不扩展新索引,直接用表中其它索引列做查询满足条件的语句,例如查询只需要(ID, A)结果时,那就可以考虑覆盖索引。这也是为什么联合索引用的多的原因?啥,你还不知道覆盖索引? 那你就看小哥哥上篇的文章
莲花童子哪吒:互联网大厂面试,谈索引就直逼这些底层?难的是我不懂这些原理mp.weixin.qq.com
大多数情况下都不需要冗余索引,应该尽量扩展已有的索引而不是创建新索引。但也有时候出于性能方面的考虑需要冗余索引,因为扩展已有的索引会导致其变得太大,从而影响其他使用该索引的查询的性能。
例如:state_id 为索引列,表数据为100W,state_id每个记录值大概为2W行
SELECT state_id city, address FROM userinfo where state_id=5;那如何提升该查询性能呢? 最简单办法就是扩展索引为 (state_ id, city, address),让索引能覆盖查询:
ALTER TABLE userinfo DROP KEY state id,ADD KEY state_id_2 (state id, city, address);
解决冗余索引和重复索引的方法就是,删除这些索引就可以,定位到这些索引。可以通过写一些复杂的访问INFORMATION_SCHEMA表中查询下面的索引名。
不过还有两个更简单的方法。可使用Shlomi Noach的common_ schema中的一些视图来定位,另外也可以使用PerconaTolkit中的pt-duplicate-key-checker, 该工具通过分析表结构来找出冗余和重复的索引。
对于大型服务器来说,使用外部的工具可能更合适些,如果服务器上有大量的数据或者大量的表,查询INFORMATION_ SCHEMA表可能会导致性能问题。

- 索引与锁开销
InnoDB 支持行锁和表锁,默认使用行锁,而 MyISAM 使用的是表锁。索引可以让查询锁定更少的行,减少锁争用从而增加并发性。这样也会提升查询的性能。那这个锁是怎么加上的呢?Innodb行锁触发条件是索引,当在存储引擎中过滤到不需要的行时才能有效,如果索引查询无法过滤掉无效的行,那就会把数据加载到服务器层,再使用 where 条件。这样无法避免锁定行了。
那有的人有疑问,都走了索引查询,不就已经减少锁定的行吗?为啥还存在锁定不必要的行?
首先,B+Tree是范围性的搜索,如果条件有局限性,那么整个范围的就会被锁定。举个例子:表数据,索引为(`is_role`, `role_name`, `role_status`)
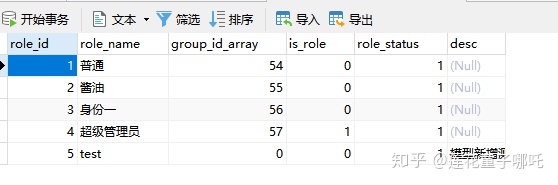
查询返回1~4,但实际上 3 已经被锁住了,这就是锁住无效的行
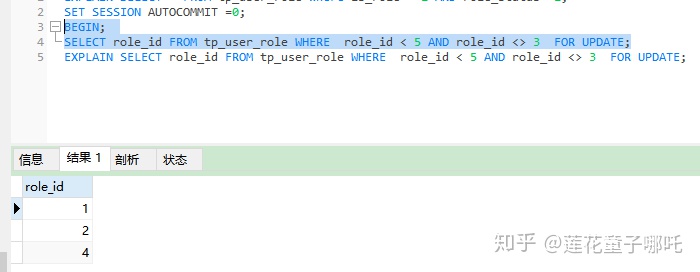
因为先走前面的索引走范围查找,然后拿到服务层,最后应用 where 字句后的条件。
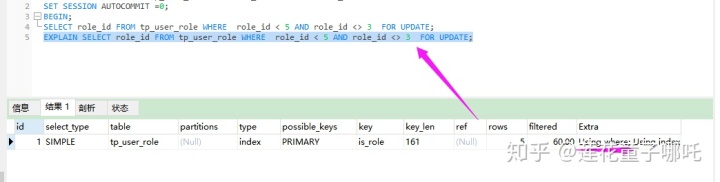
现在访问,3记录,将会锁住
那如果查询中锁定了10000行,但实际只需用100行,就亏大了。在 5.1 之前都需要提交事务之后才能释放这些锁,5.1 之后可以在服务器端过滤掉行之后就释放锁,不过依然会导致一些锁冲突。那怎么解决呢?
那就避免在 服务层使用where字句,直接在索引查找的时候,只保留需要数据,常见就是覆盖索引啦!
- 减少索引碎片
前面谈到了索引碎片的问题,首先得先知道造成索引碎片的原因是啥?
- 选用主键随机性太大,不是有序增长的,比如uuid
默认innodb的B+Tree都是根据主键来做顺序写入的,这样可让索引更加的紧凑,不会出现分裂。如果你主键是随机的,那么写入到磁盘时,数据就会不连续。
- 删操作
删除主要是因为破坏了页的完整性,数据库删除数据时,在磁盘页里面只是打个删除标记,并不会真正抹除磁盘上的数据,就类似于伪删除。当后面有新增数据就直接把标记的数据覆盖,从而更好的利用空间。 现在你该知道,为啥你删除记录后,后面新添数据,主键还是会在以前的基础上继续递增。
那这情况,只能重新梳理页结构,这样会让数据变的更加紧凑,不让它们分散到各处。可以通过 OPTIMIZE TABLE 或者重新导入数据表来整理数据。对于不支持 OPTIMIZE TABLE 的存储引擎,直接通过ALTER TABLE 操作来重建表。只需要将表的存储引擎修改为当前的引擎即可:
ALTER TABLE <table> ENGINE=<engine>;
- 避免强制类型转换
当查询条件左右两侧类型不匹配的时候会发生强制转换,强制转换可能导致索引失效而进行全表扫描。
如果phone字段是varchar类型,则下面的SQL不能命中索引:
select * from user where phone=12345678888;
可以优化为:
select * from user where phone='12345678888';总结
- 索引优化的根本:
- MySQL 优化成本即查询扫描的行数
- 索引自身维护消耗
- 索引优化的关键,即 MySQL 通过索引执行查询计划时,首先根据索引列的顺序对比,对比完成后在进行数据读取,最后做where条件限制。
- 该索引优化是针对索引底层组成上,下一篇将在 SQL语句优化上继续完善,毕竟索引得靠它使用出来。
如有帮助,欢迎关注。后续好文不断更新。每写一篇文章真的比较费劲,但都是我自己慢慢挺过来的。转发或关注都是支持,谢谢大家微信搜索:莲花童子哪吒
















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









