





在一次crud的时候,碰到了这样一个接口返回的数据是这样子的
<MachineModel machModelId="915432156" machModelName="故障标准传动链" machLayoutStatus="0">
<item machModelId="915432156" itemtype="7" id="915432156_1" name="行星" bearingType="SRB/CARB" bearingCompany="FAG" ftf="0.455" bsf="10.718" bpfo="13.64" bpfi="16.36" position_x="127" position_y="150" speedRate="0.008350566967190259" left="8" right="16">
item>
<item machModelId="915432156" itemtype="7" id="915432156_2" name="恒星" bearingType="F-573602.NCF-WPOS" bearingCompany="FAG" ftf="0.476" bsf="20.7" bpfo="30.9" bpfi="34.1" position_x="287" position_y="150" speedRate="0.008350566967190259" left="16" right="3">
item>
MachineModel>

后端将xml配置文件读出来返回给我了,要我拿到标签上的数据在页面上的位置做展示。嗯?
暂时没什么好的想法, 那么就直接innerHtml然后document.getElementsByTagName吧。

写完了之后,发现可维护性太差了吧。写的确实有些辣眼睛,想到是不是可以把vue的模板解析的代码借鉴(抄一抄)下,解析模板字符串,拿到标签上的数据。
正则
const ncname = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`; // aaa-bbb // 命名空间
const qnameCapture = `((?:${ncname}\\:)?${ncname})`; // ?: 代表匹配不捕获
const startTagOpen = new RegExp(`^<${qnameCapture}`); // 标签开头的正则 捕获的内容是标签名
const endTag = new RegExp(`^${qnameCapture}[^>]*>`); // 匹配标签结尾的 创建parseHtml函数,通过闭包的形式创建辅助函数公用html模板字符串参数。循环html字符串,处理不同的情况,处理之后进行截取。
while (html) {
let textEnd = html.indexOf(')// 判断是否是if (textEnd === 0) {// 如果进来了,那么这可能是开始标签也可能是结束标签let startTagMatch = parseStartTag(html) // 对开始标签进行解析 , 返回处理后的结果,主要数据为tagNameif (startTagMatch) {// 进栈
start(startTagMatch.tagName)// 如果匹配到了自闭和标签if (startTagMatch.autoEnd) {
end(startTags[startTags.length - 1])
}continue // 如果开始标签匹配完毕后,继续下一次匹配
}// 尝试匹配结束标签let endTagMatch = html.match(endTag)if (endTagMatch) {
advance(endTagMatch[0].length)
end(endTagMatch[1])continue
}
}let text// 如果大于0,则说明距离下一个开始标签还有距离, 而且中间值是文本111222if (textEnd >= 0) {
text = html.substring(0, textEnd)
advance(text.length)// 这里去除字符串即可,无需进行额外处理
}
}最核心的函数解析开始标签,拿到需要的属性
最核心的函数解析开始标签,拿到需要的属性function parseStartTag() {
let start = html.match(startTagOpen)
if (start) {
const match = {
tagName: start[1], // 匹配到第一个分组, 在这里就是这个标签名。
attrs: []
}
advance(start[0].length) // start[0] 代表匹配到的结果
let endT, attr;
// 如果没有匹配到结束标签并且还能匹配到属性的话那么就开始解析属性
while (!(endT = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length) // 将属性去掉
match.attrs.push({
name: attr[1],
value: attr[3] || attr[4] || attr[5]
})
}
stack.push({ tagName: match.tagName, attrs: match.attrs })
// 这里处理了自闭和标签
if (endT[0].trim() === '/>' && html.trim().match(startTagClose)) {
let endTagMatch = html.match(startTagClose)
if (endTagMatch) {
advance(endTagMatch[0].length)
}
return { ...match, autoEnd: true }
} else {
advance(endT[0].length) // 将开始标签的> 去掉
return match
}
}
}
匹配到开始标签,需要进栈
匹配到开始标签,需要进栈 function start(tagName) {
startTags.push(tagName)
}
匹配到结束标签,需要进栈, 开始与结束标签进栈的目的是对匹配到的结束标签是否是上一次匹配到的开始标签,否则就报错。至于自闭合标签在parseStartTag函数中处理过了。
匹配到结束标签,需要进栈, 开始与结束标签进栈的目的是对匹配到的结束标签是否是上一次匹配到的开始标签,否则就报错。至于自闭合标签在parseStartTag函数中处理过了。function end(tagName) {
endTags.push(tagName)
if (tagName === startTags[startTags.length - 1]) {
startTags.splice(-1)
} else {
console.error('开始标签与结束标签不匹配')
// 进行异常处理
}
}
对html字符串进行截取
对html字符串进行截取 function advance(n) {
html = html.substring(n)
}
完整代码
完整代码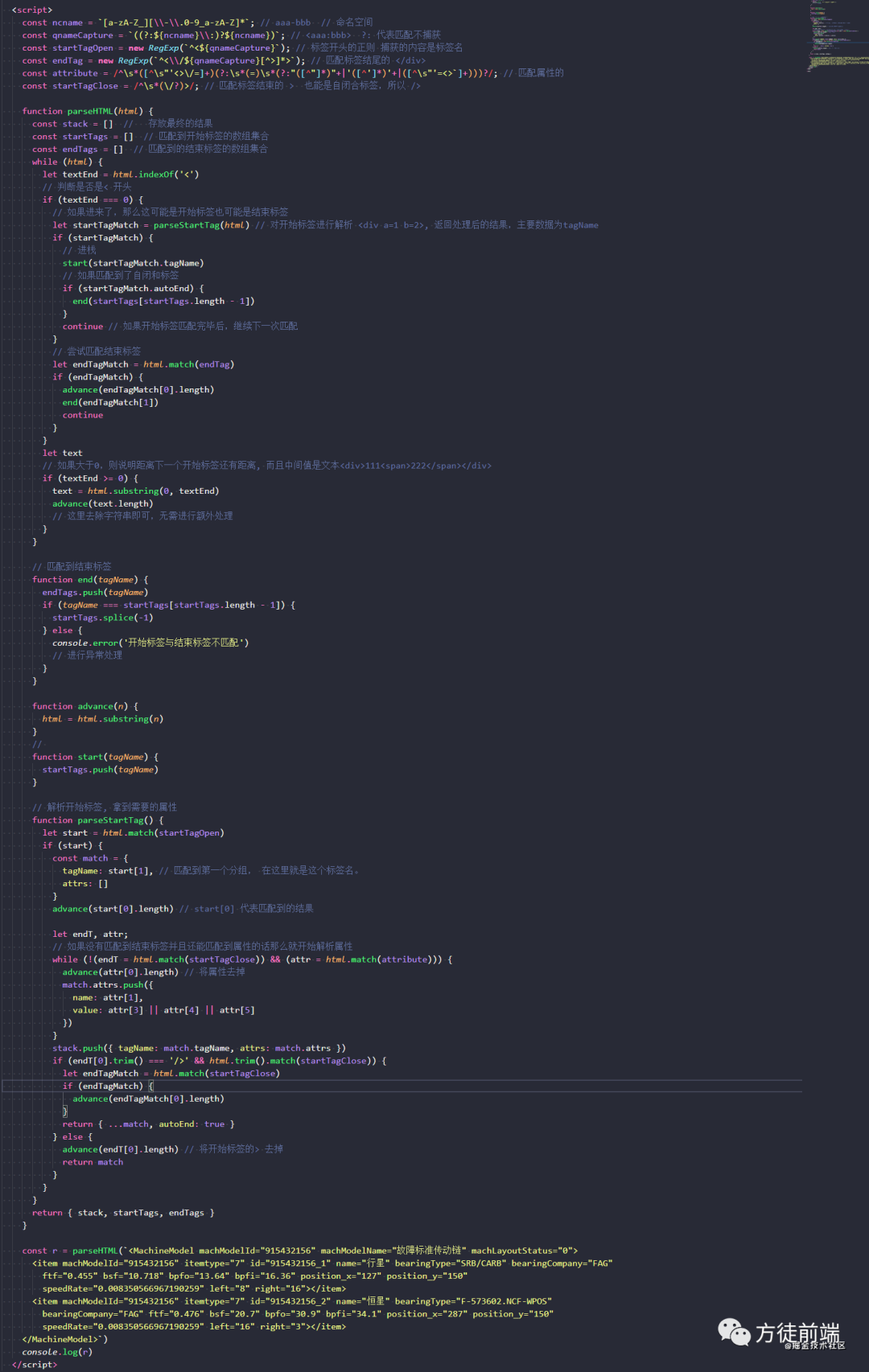
返回的处理结果
返回的处理结果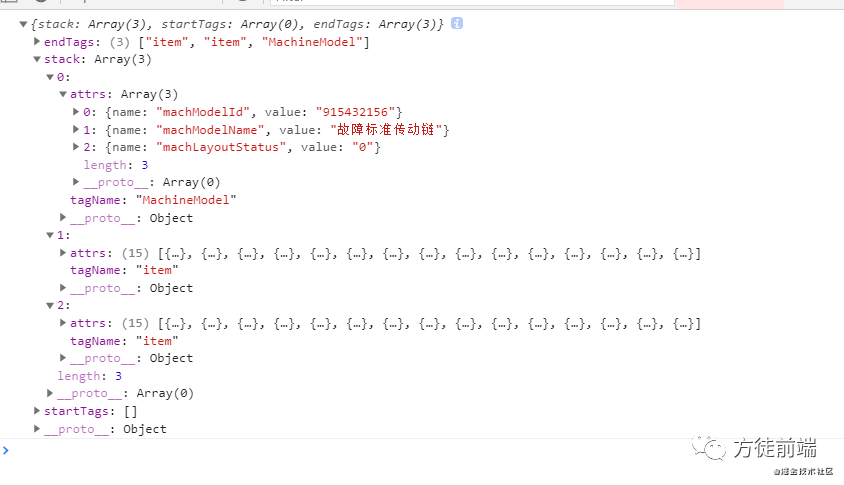
谢谢看完
谢谢看完如果这篇文章对您有所帮助的话,那就点个赞趴。
往期文章:
【我只看到了第三层】重新聊聊webpack
通俗易懂的实现符合promise A+ 规范的自定义promise
js异步编程,eventLoop、消息队列都是做什么的?什么是宏任务,什么是微任务
webpack4 搭建企业级脚手架
关注公众号查看更多有趣的文章、干货和完整代码。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









