






我们在Spark高级分析指南 | 机器学习和分析流程详解(上)快速介绍了一下不同的高级分析应用和用力,从推荐到回归。但这只是实际高级分析过程的一小部分。你可能会发现,选择一个任务或算法通常是最简单的部分。主要的挑战是围绕特定算法的一切。本部分会给出整个分析过程的结构,及我们必须要采取的步骤 而不是执行一整个任务,但客观的评估有效性是为了 理解我们是否应该将训练过的算法用到实际上。
01 高级分析的流程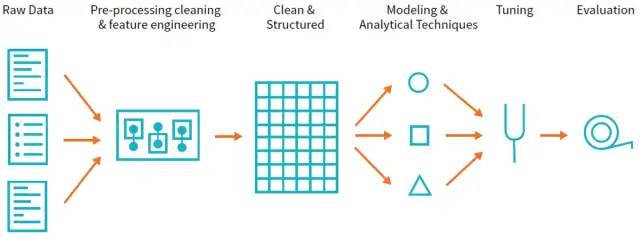
整个过程大体上遵循以下内容:
收集任务相关的数据
清晰和检查数据 来更好地理解它
执行特性工程,让算法能利用更多的信息
使用一部分数据作为训练集 来训练一个或多个算法,得到一些候选模型
通过在同一份数据的一个子集上(没有被用来作为训练集的)客观地测结果来做为成功标准,以评估和比较各模型
利用 上述过程得到的 模型能力 来进行预测、推荐、发觉异常或解决更多的一般业务挑战
这对每格高级分析任务都是一样的吗?当然不是。然而,这确实可以作为一个通用框架,来帮助你知道为了获得一个高级分析用力并从中得到价值需要做什么。就像我们对在前面的各种高级分析所做的那样,让我们分解过程的每一步来更好地理解每个步骤的总体目标。
1. 数据采集
不首先收集数据,自然很难创建训练数据。这通常意味着至少要收集用来训练算法的数据集。Spark在这方面显然是一个卓越的工具,因为它可以同各种数据源进行对话,并处理大大小小的数据。
2. 数据清洗
在收集了适合的数据后,你需要对其进行清理和检查,并沿着探索性数据分析或EDA 的路线 执行一些操作。EDA 在你视图更好地理解数据这个阶段 的一个合适的工具,它强调使用可视化方法来更好地理解数据的分布、相关性和其他细节。在这个过程中你会注意到你需要丢弃一些在数据上游记录错误或丢失的数据。
不论是哪种情况,对数据有更好的理解,并知道数据中有什么,都是一件好事,可以避免以后的错误。Structured APIs 中有许多函数可以提供清洗数据的简单方法。
3. 特征工程
现在有了清洗过的数据集,是时候通过潜在的规范化数据来增强它了(如果有必要的话),增加变量来代表其他变量间的交互,操作类别变量来转化为适当的格式作为机器学习模型的输入。
在MLlib中,所有变量必须以double型输入(不管他们实际代表什么)。这意味着你很可能必须用一些 类似单热编码类别变量和其他索引样式技术。
Spark提供基本的你会使用的各种机器学习特定的统计技术 来操作数据的基本要素。
4. 模型训练
下面的两步(训练模型、模型校正和评估)并非所有用例情况都有。这是一个一般的工作流,根据最终实现目的的不同,会有很大的不同。
到流程的这一步,我们有一个可以用来训练模型的数据集。训练一个模型意味着我们会给模型一组数据,机器学习模型会尝试执行我们前面指定的任务。在这个过程中,模型内部的参数会根据损失函数进行调整,为了在给定任务上尽量表现得更好。
例如,如果我们希望将垃圾邮件分类,我们的算法可能会找到某些词汇 能比其他词汇 更好地预测垃圾邮件。在我们的模型中,这些词会比那些没有相关性的词受到更大的影响。我们所说的模型就是算法的输出和数据。
一个模型是一个算法的校正版本,算法只是可以用来洞悉好预测的简化版本。然后我们给模型输入行的数据,模型会相应的对数据进行操作。在分类的例子中,我们有一个关于垃圾邮件特征的模型,如果我们给模型一个新邮件,它会返回输出对该邮件是否为垃圾邮件的预测。
然而,训练一个算法不是目的——我们想用模型来获得洞察力。因此我们必须回答这个问题,我们怎样知道我们的模型在它应该做的事情上是好的?这是模型校验和评估的内容。
5. 模型校正和评估
你可能注意到,如上所述我们习惯将数据分为几个部分,而只用一个部分来训练。我们创建训练集而不是在全部数据集上训练的原因,是为了用其他的部分来校正模型或与其他模型比较。这么做的原因很简单,当我们构建一个模型后,我们希望模型可以推广到新的数据或以前没有见过的数据上。用来测试模型有效性的那部分数据被称为测试机。将其想象成学校中的考试。其目的是查看模型是否理解了 该数据处理的基本原则,还是只注意到了训练集中特定的东西。
在训练模型的过程中,我们还可能取另一个数据子集,并将其作为一个小的测试集(称为验证集),为了尝试不用的超参数或可能影响其他参数的参数——本质上,模型的变型。
继续已分类案例为例。我们有三个数据集,一个训练集用来训练模型,一个验证集用来验证我们正在训练的模型的不同变型,基于一个测试集会在最后用来对不同模型变型的评估,看看那个模型表现的最好。
6. 模型的利用
最后我们使用模型,可能是为了更好地了解顾客或执行用户划分或预测垃圾邮件。无论在哪种情况,这都是最终的目的。尝试解决的一个问题并更好地理解你的数据。
这个简要的工作流概述只是一个工作流的例子,并不包括所有的情况或可能的工作流。还有很多细节会很大的影响你的结果,
02Spark的高级分析工具箱Spark包含很多用来执行高级分析的核心包和很多第三方包。一个基本的包就是MLlib,其提供了用来构建机器学习管道的接口。
1. MLlib
是一个工具包,包含在Spark中,提供接口来:
收集和清洗数据
特征工程和特征选择
训练和校正大规模监督和非监督机器学习模型
在生产中使用这些模型
MLlib帮助完成整个过程的所有三个步骤,在前两个步骤中表现非常突出,原因我们稍后将讨论。
MLlib包含两个包分别使用不同的核心数据结构:
org.apache.spark.ml维护提供给Spark DataFrame的接口。同时为标准化执行上述步骤而构建的机器学习管道维护高级别接口。
低级别的包 org.apache.spark.mllib维护供Spark底层 RDD APIs 使用的接口。
什么时候及为什么你应该使用MLlib(相比于 scikit learn \ tensorfolw \ foo package)?
现在,你可能听说过很多其他机器学习包,比如可以python或各种R语言版本的,执行类似任务的scikit-learning包。你为什么吗还要使用MLlib呢?
有很多的工具可用来在单机上执行机器学习任务。他们在这方面做的都很好,并会继续称为更好的工具。然而,这些单机工具在用来训练的数据大小上 和处理时间上都受到了限制。
在规模上受到限制的事实,使它们称为了互补工具,而不是竞争对手。当您遇到这些可伸缩性问题时,请利用Spark的功能。
有两种主要情况,你会想要利用Spark的规模特性。首先,在从大量数据中生成训练集和测试集时,你回想使用Spark来预处理和生成特征以减少这个过程所花费的时间。 接着,你可能会想利用单机的机器学习算法在这些给定数据上进行训练。 第二种情况是,当你的输入数据和模型规模很难或不便于放在一台机器上时,使用Spark来承担这一重任。Spark使大数据机器学习变得容易。
对前面段落的一个重要警告是,虽然训练和数据准备都很简单,但仍然需要记住一些复杂性。比如,如果你在Spark集群上训练一个推荐系统,那么最终模型将会很大以至于难以在一台机器上运行预测,然而我们仍要做出预测来从模型中获得价值。另一个例子是在Spark训练一个逻辑回归模型。
Spark的执行引擎不是一个低延迟的执行引擎,因此,即使在单机上,由于启动和执行一个Spark工作的花费,快速(<500ms)做出单一预测仍是有挑战的。一些模型对这个问题有很好的答案,另一些仍然是开放的问题。我们将在本章的最后讨论目前的技术状况。这是一个富有成果的研究领域,随着新系统的出现,对这个问题的解决也会改变。
2. 高级别MLlib概念
在MLlib中,有很多基本的“结构”类型:transformers,estimators,evaluator和pipelines。
通过结构化,他们将定义你要做出的总体架构选择。下面是对一个整体工作流程例子的说明:
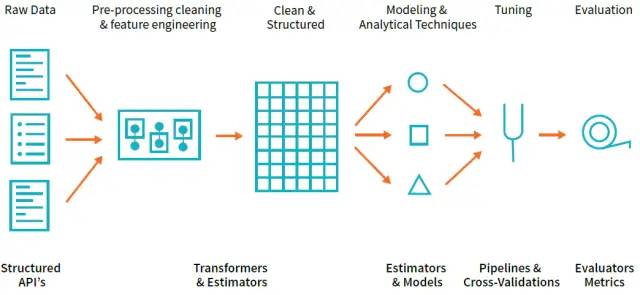
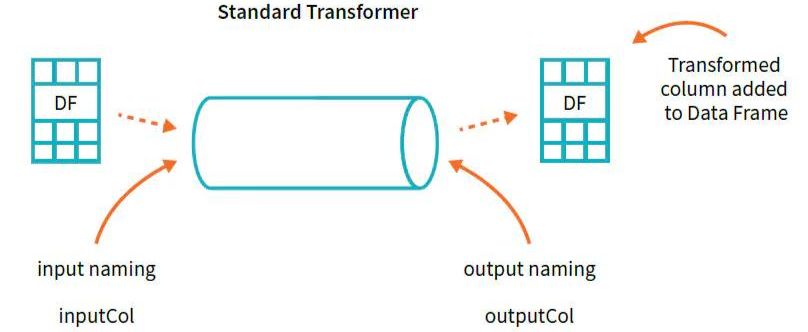
Transformers是以某种方式转换原始数据的函数。其可能创建一个新的交互变量(从两个其他变量得到)、标准化一个列、或仅仅将其转换成double型作为模型的输入。一个transformer例子是将字符串分类变量转换为可用于MLlib的数值。Transformers是预处理和特征生成中最先用到。
Estimators是两种类型的操作之一。首先,estimators可以是一种初始化数据的transformer。一个例子是将一列转换为列的百分位表示——为了做到这点我们会基于列中的值进行初始化。然后,estimators是Spark中实际模型的名称(估计器),我们将对其进行培训并将其转换为模型,以便使用它们进行预测。
一个evaluator允许我们查看 一个给定estimator 是如何根据我们指定的标准,如ROC曲线,来执行的。一旦我们从测试模型中选择了最好的模型,就可以使用他来进行预测了。
在较高的层次上,我们可以逐个指定上面的每个步骤,然而在pipeline中指定个步骤为一个stages往往更简单。这个pipeline类似于 Scikit-learn的Pipeline概念,transformations和estimators是一起制定的。
除了高级架构类型之外,还有很多底层事物你可以使用。最常见的是Vector。无论何时我们将一组特征输入给机器学习模型,我们都必须以一个有Doubles构成的Vector 的形式给出特征。这个vector可以是稀疏的或稠密的。它们以不同的方式指定,一种是指定精确值(稠密的),另一种是指定总大小及哪些值非零(稀疏的)。你可能已经猜到的,当大量值为0时,稀疏向量作为比其他格式更扁平的形式 是更合适的。
%scalaimport org.apache.spark.ml.linalg.Vectorsval denseVec = Vectors.dense(1.0, 2.0, 3.0)val size = 3val idx = Array(1,2) // locations in vectorval values = Array(2.0,3.0)val sparseVec = Vectors.sparse(size, idx, values)sparseVec.toDensedenseVec.toSparse%pythonfrom pyspark.ml.linalg import VectorsdenseVec = Vectors.dense(1.0, 2.0, 3.0)size = 3idx = [1, 2] # locations in vectorvalues = [2.0, 3.0]sparseVec = Vectors.sparse(size, idx, values)令人困惑的是,有一些类似的类型。其类似是指一些可以在DataFrame中使用,而另一些只能在RDDs中使用。RDD的实现在mllib包中,DataFrame的实现在ml包中。
End.
作者:有机会一起种地OT
来源:简书
















 1930
1930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









