





背景
在前面的系列文章中,多次提到了batch这个事,毕竟是GPU设备,有大量的设备线程,就是能适用这种批量的场景,所以使用batch是更高效的办法。
如果使用batch,有3种办法
1) 应用自己凑batch, 把这个事情丢给了上层,上层有改造成本,这对他们来说是个负担
2)服务提供方通过外层消息队列搞定,硬生生的将一个同步的应用变成了异步,上层也有改造成本
3)还是服务方提供方搞定,但是是内部搞定,上层应用无感知,这就是本文的主要话题
加载时
动态批次的几个核心概念
- 推荐批次:可以是多个,比如8,16,32(可通过模型配置文件配置),参考
preferred_batch_sizes_ - 最大批次:显然是推荐批次中最大的那个,参考
max_preferred_batch_size_ - 最大延时:凑批次过程可能需要等待,但也不能无限等待,所以有个类似的超时限制(可通过模型配置文件配置),参考
pending_batch_delay_ns_ - 当前已凑批次大小:批次后面的凑批次的过程中会讲,参考
pending_batch_size_,这个只是一个过程数据,未必是最终的批次 - 当前已凑批次大小对应的payload数量:后面的凑批次的过程中会讲,参考
pending_batch_queue_cnt_,如果payload的中图像只有1个即请求的batchsize为1,那么pending_batch_size_=pending_batch_queue_cnt_,同样,这也是一个过程数据,未必是最终的payload数量
具体细节参考代码【http://dynamic_batch_scheduler.cc】
DynamicBatchScheduler::DynamicBatchScheduler(
const ModelConfig& config, const uint32_t runner_cnt,
StandardInitFunc OnInit, StandardRunFunc OnSchedule)
: OnInit_(OnInit), OnSchedule_(OnSchedule),
scheduler_thread_cnt_(runner_cnt), idle_scheduler_thread_cnt_(0),
pending_batch_size_(0), pending_batch_queue_cnt_(0)
{
dynamic_batching_enabled_ = config.has_dynamic_batching();
......
max_preferred_batch_size_ = 0;
preferred_batch_sizes_.clear();
pending_batch_delay_ns_ = 0;
if (dynamic_batching_enabled_) {
for (const auto size : config.dynamic_batching().preferred_batch_size()) {
max_preferred_batch_size_ =
std::max(max_preferred_batch_size_, (size_t)size);
preferred_batch_sizes_.insert(size);
}
pending_batch_delay_ns_ =
config.dynamic_batching().max_queue_delay_microseconds() * 1000;
}
}
运行时
在TensorRT serving的inference实现 已经讲过了调度线程的默认过程,忽略了如果启动动态批次功能后的分支,现在来看看这个分支,本来默认过程是从队列中拿到请求payload后就直接开始处理了,但动态批次不是这样
- 获取批次,但未必能成功,不成功就继续等待再次被唤醒了
- 如果成功,那么就把批次从队列中取出来,取多少payload参考
pending_batch_queue_cnt_(代表了本个批次的payload数量) - 最后如果此时队列还有剩余的payload且还有空闲的调度线程,那么就设置一个通知标记(后面会去唤醒其他线程)
具体细节参考代码【SchedulerThread @http://dynamic_batch_scheduler.cc】
......
else if (dynamic_batching_enabled_) {
// Use dynamic batching to get request payload(s) to execute.
wait_microseconds = GetDynamicBatch();
if (wait_microseconds == 0) {
payloads = std::make_shared<std::vector<Scheduler::Payload>>();
for (size_t idx = 0; idx < pending_batch_queue_cnt_; ++idx) {
payloads->emplace_back(std::move(queue_.front()));
queue_.pop_front();
}
pending_batch_size_ = 0;
pending_batch_queue_cnt_ = 0;
pending_batch_shapes_.clear();
wake_thread = !queue_.empty() && (idle_scheduler_thread_cnt_ > 0);
}
}
......
if (wake_thread) {
cv_.notify_one();
}
最后来看看获取批次的详细过程
- 某个调度线程锁抢到锁进来获取batch(能再次进入到这里,必然是因为有新的payload进来被唤醒了,另外,能进入到这里的并不一定是上次那个进来到这里但凑批次失败的线程,要看随能抢到锁)
- 从当前(上次)保留的payloads后面开始遍历队列(如果上次的凑批次成功的话,此变量为0,否则就是个中间值,就队列中保留的payload个数)
- 如果当前batchsize不为0(也就是上面提到的,上次凑批次并未成功),那么再看看加上新的payload是否会超过最大的batch size的,如果是就跳出这个遍历循环,也意味着会直接输出上次的那个不成功的批次
- 如果没有跳出,那么就算出新的batch和其对应的队列中payload个数(不一定是队列中所有的payload)
- 因为有了新的batch大小,那么看看是否能匹配上文提到的模型配置中batch size,需要注意就算命中了配置的batch size 也不一定会跳出循环,除非是最大的那个batch size, 这里使用了贪婪匹配
- 如果没有命中,继续遍历
- 可见跳出循环跳出的条件是
- 查过了最大的batch size
- 遍历自然结束
- 跳出循环后
- 如果曾经命中过配置的batch size ,无论是否最大,凑批次成功,直接返回
- 如果是因为超过了最大的batch size而跳出循环的,凑批次成功,直接返回
- 如果上文提到的超时配置是0,即不等待,凑批次成功,直接返回
- 计算批次的超时时间(当前的时间-批次的那个队列中第一个最老的payload的时间),如果超过了配置的超时时间,凑批次成功,直接返回
- 否则失败,也会返回,等待下次再次凑批次
具体细节参考代码【http://dynamic_batch_scheduler.cc】
uint64_t
DynamicBatchScheduler::GetDynamicBatch()
{
bool send_now = false;
size_t best_preferred_batch_size = 0;
size_t best_preferred_batch_cnt = 0;
size_t search_batch_size = pending_batch_size_;
size_t search_batch_cnt = pending_batch_queue_cnt_;
for (auto idx = pending_batch_queue_cnt_; idx < queue_.size(); ++idx) {
const auto batch_size =
queue_[idx].request_provider_->RequestHeader().batch_size();
if (search_batch_cnt == 0) {
......
} else {
if ((search_batch_size + batch_size) > max_preferred_batch_size_) {
send_now = true;
break;
}
......
}
search_batch_size += batch_size;
search_batch_cnt++;
if (preferred_batch_sizes_.find(search_batch_size) !=
preferred_batch_sizes_.end()) {
best_preferred_batch_size = search_batch_size;
best_preferred_batch_cnt = search_batch_cnt;
}
}
// If we found a preferred batch size then execute that.
if (best_preferred_batch_size != 0) {
pending_batch_size_ = best_preferred_batch_size;
pending_batch_queue_cnt_ = best_preferred_batch_cnt;
return 0;
}
pending_batch_size_ = search_batch_size;
pending_batch_queue_cnt_ = search_batch_cnt;
......
if (send_now || (pending_batch_delay_ns_ == 0) ||
(pending_batch_size_ >= max_preferred_batch_size_)) {
return 0;
}
struct timespec now;
clock_gettime(CLOCK_MONOTONIC, &now);
const struct timespec& queued = queue_.front().queue_timer_->StartTimeStamp();
uint64_t delay_ns = (now.tv_sec * NANOS_PER_SECOND + now.tv_nsec) -
(queued.tv_sec * NANOS_PER_SECOND + queued.tv_nsec);
if (delay_ns >= pending_batch_delay_ns_) {
return 0;
}
return (pending_batch_delay_ns_ - delay_ns) / 1000;
}
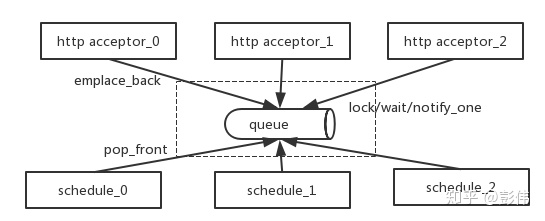
完整的示意图如下
测试
1) 模型配置
instance_group [
{
kind: KIND_GPU
count: 8
}
]
dynamic_batching {
preferred_batch_size: [ 16 ]
max_queue_delay_microseconds: 1000
}注意我开了8个实例
2) 测试代码
在TensorRT serving的inference实现 的测试代码基础进行了一点重构
之前只是根据一个传入的图片生成模型输入,现在为了验证能带来更好的性能,加了一个产生批次输入的功能
- 为了更存粹的验证性能,预先生产了所有的测试输入
- 本文生产了10000个随机输入,每个输入是3 * 299 * 299 *4 个字节的拷贝,所以总共10g+内存,如果没那么大内存,那就少产生一点
- 随机产生这10000个得消耗200s+, 也试过并发产生,但发现更慢
- 实际测试发现无论是随机输入还是一个单一的图片,系统的整个qps 几乎没变化
- 上文看到开了8个实例,再加大qps不会变化了
- 开启batch qps1000 VS 不开启 qps 400 【硬件是p100, 模型是fp16】 , 效果还是明显的,此时GPU利用率都超过了90%+
#include "src/core/model_config_utils.h"
#include "src/backends/tensorrt/plan_backend_factory.h"
#include <iostream>
#include "src/core/server.h"
#include "src/core/server_status.h"
#include <google/protobuf/text_format.h>
#include "src/core/provider.h"
#include <event2/buffer.h>
#include "src/core/status.h"
#include "src/clients/c++/request_http.h"
#include <condition_variable>
#include "src/core/logging.h"
namespace ni = nvidia::inferenceserver;
namespace nic = nvidia::inferenceserver::client;
enum ScaleType { NONE = 0, VGG = 1, INCEPTION = 2 };
void loadModel(std::string config_path,std::string version_path,ni::ModelConfig &model_config,
std::unique_ptr<ni::InferenceBackend> &backend){
ni::BackendConfigMap backend_config_map;//null
bool autofill=false;
ni::GetNormalizedModelConfig(config_path, backend_config_map, autofill, &model_config);
ni::ValidateModelConfig(model_config, std::string());
auto plan_config = std::make_shared<ni::PlanBackendFactory::Config>();
plan_config->autofill = false;
std::unique_ptr<ni::PlanBackendFactory> plan_factory;
ni::PlanBackendFactory::Create(plan_config, &plan_factory);
plan_factory->CreateBackend(version_path, model_config, &backend);
}
void
FileToInputData(
const std::string& file_name, size_t c, size_t h, size_t w,
ni::ModelInput::Format format, int type1, int type3, ScaleType scale,
std::vector<uint8_t>* input_data);
void loadData(std::string& file_name,std::vector<uint8_t>* image_data){
size_t c=3;
size_t h=299;
size_t w=299;
ni::ModelInput::Format format = ni::ModelInput_Format_FORMAT_NCHW;
int type1=5;
int type3=21;
ScaleType scale = ScaleType::INCEPTION;
FileToInputData(file_name, c, h, w, format, type1, type3, scale, image_data);
}
void loadRndData(std::vector<uint8_t>* image_data){
std::vector<uint8_t> input_buf(3*299*299*4);
for (size_t i = 0; i < input_buf.size(); ++i) {
input_buf[i] = rand();
//input_buf[i] = 0;
}
image_data->swap(input_buf);
}
void loadCoreDataSet(std::vector<std::vector<uint8_t>> &image_data_set,int num){
for(int i=0;i<num;i++){
image_data_set.emplace_back();
loadRndData(&(image_data_set.back()));
if((i+1)%1000==0){
LOG_INFO<<"loading:"<<(i+1);
}
}
LOG_INFO<<"load data:"<<num;
}
void loadDataSet(std::vector<std::vector<uint8_t>> &image_data_set,int num,int threads_num){
image_data_set.clear();
std::vector<std::thread> threads;
std::vector<std::vector<uint8_t>> partionDataSet[threads_num];
if(threads_num<1 || num<1 || num%threads_num!=0){
return;
}
LOG_INFO<<"===load data start====";
for(int i=0;i<threads_num;i++){
threads.emplace_back(loadCoreDataSet,std::ref(partionDataSet[i]),num/threads_num);
}
for(int i=0;i<threads_num;i++){
threads[i].join();
image_data_set.insert(image_data_set.end(),partionDataSet[i].begin(),partionDataSet[i].end());
}
LOG_INFO<<"===load data done====";
}
std::mutex exit_mu;
std::condition_variable exit_cv;
volatile int done = 0;
void infer(std::string model_name,int64_t model_version,std::string model_path,
std::string infer_request_header,
ni::ModelConfig &model_config,
std::unique_ptr<ni::InferenceBackend> &is,
std::vector<uint8_t>& image_data,
std::shared_ptr<ni::ServerStatusManager>& ss_mgr){
//build ModelInferStats
auto infer_stats = std::make_shared<ni::ModelInferStats>(ss_mgr, model_name);
auto timer = std::make_shared<ni::ModelInferStats::ScopedTimer>();
infer_stats->StartRequestTimer(timer.get());
infer_stats->SetRequestedVersion(model_version);
//build InferRequestProvider
ni::InferRequestHeader request_header;
google::protobuf::TextFormat::ParseFromString(infer_request_header, &request_header);
char* buffer = (char*)&image_data[0];
auto smp = new ni::SystemMemoryReference();
smp->AddBuffer(buffer,image_data.size());
auto smsp = std::shared_ptr<ni::SystemMemory>(smp);
std::unordered_map<std::string, std::shared_ptr<ni::SystemMemory>> input_map;
input_map["input"]=smsp;
std::shared_ptr<ni::InferRequestProvider> request_provider;
ni::InferRequestProvider::Create(model_name, model_version, request_header, input_map, &request_provider);
infer_stats->SetBatchSize(request_provider->RequestHeader().batch_size());
//build InferResponseProvider
std::shared_ptr<ni::HTTPInferResponseProvider> response_provider;
evbuffer* output_buffer = evbuffer_new();
ni::HTTPInferResponseProvider::Create(output_buffer,
*(is.get()),
request_provider->RequestHeader(),
is->GetLabelProvider(),
&response_provider);
//build callback
auto OnCompleteHandleInfer = [response_provider,&is](ni::Status status){
//std::cout<<"status.Message():"<<status.Message()<<std::endl;
if (status.IsOk()) {
response_provider->FinalizeResponse(*(is.get()));
ni::InferResponseHeader* response_header = response_provider->MutableResponseHeader();
//std::string rstr(response_header->DebugString());
//std::cout<<rstr<<std::endl;
std::unique_lock<std::mutex> lock(exit_mu);
done++;
if(done%1000==0){
LOG_INFO<<"infer data:"<<done;
}
}
exit_cv.notify_all();
};
//infer
is->Run(infer_stats, request_provider, response_provider, OnCompleteHandleInfer);
}
int main(){
std::string model_path="/your/path/model_repository";
std::string model_name("plan_model");
int64_t model_version = 1;
int infer_count=10000;
//load model
std::string config_path=model_path+"/"+model_name;
std::string version_path= config_path+"/"+ std::to_string(model_version);
std::unique_ptr<ni::InferenceBackend> is;
ni::ModelConfig model_config;
loadModel(config_path,version_path,model_config,is);
//load data_set
std::vector<std::vector<uint8_t>> image_data_set;
loadCoreDataSet(image_data_set,infer_count);
if(image_data_set.size()<1){
LOG_INFO<<"===empty data====";
return 0;
}
//infer
std::string infer_request_header("batch_size:1
input { name: "input" batch_byte_size:1072812}
output { name: "InceptionV3/Predictions/Reshape_1"
cls { count:1}}");
auto ss_mgr = std::shared_ptr<ni::ServerStatusManager>(new ni::ServerStatusManager(""));
ss_mgr->InitForModel(model_name, model_config);
for(int i=0;i<infer_count;i++){
infer(model_name,model_version,model_path,infer_request_header,
model_config,is,image_data_set[i],ss_mgr);
}
std::unique_lock<std::mutex> lock(exit_mu);
exit_cv.wait(lock,[&infer_count]{return done==infer_count;});
return 0;
}
小结
- 使用TensorRT或者GPU时用上batch非常重要
- batch 两个因素:大小和窗口期 (本文将大小设置成模型配置允许的最大尺寸)
- 相比不开启batch, qps增长了150%
- 本文压测代码中放弃了所有的http 相关部分,就是本地起一个单线程预先产生好所有输入,然后开始往队列扔,消费线程如配置所示开了8个实例数,可以认为没受到其他因素的干扰
- 重复压测一个输入还是多个从压测结果上并没有差别
- 看看和性能相关的几个因素: schedule实例数/模型量化版本/动态batch/模型生成时的最大batch数
- 在p100机器上测试V3的fp16版本,batch16或者32能使得qps达到1000~1100,再大或者再小效果都会差点,如果能用上int8因该会稍微好点,无论怎样这个性能值基本上已经是极限了
- 尝试使用官方client 压测同样配置下的官方server(不开启动态batch,也不使用client batch),只能到100+, 原因还不太明确
trtis/install/bin/trtserver --model-store=your/path/model --http-thread-count=8 &
trtis-clients/install/bin/perf_client -u x.x.x.x:8000 -m plan_model -p3000 -t4 -v -b1














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









