





写在前面:
本文先写的渣英文再渣翻译,请见谅。
Intro2 Conditional Random Field(CRF)
1.1 CRF能用来做什么?
CRF 是一个序列化标注算法(sequence labeling algorithm),接收一个输入序列如

除了词性标注之外,CRF还可以用来做chunking,命名实体识别等任务。一般地,输入序列

1.2 What is conditional random field?
Random 指的是随机变量
1.3 HMM, a Generative model
给定一个观测序列observations, HMM models joint probability
这些假设使得HMM能够计算出给定一个词和它可能的词性的联合概率分布。换句话说,HMM假设了两类特征,一是当前词词性与上一个词词性的关系,以及当前词语和当前词性的关系,分别对应着转移概率和发射概率。HMM的学习过程就是在训练集中学习这两个概率矩阵(大小为
稍不同于linear CRF,HMM可以用有向图模型来表示,因为states与observations之间存在着明显的依赖关系。
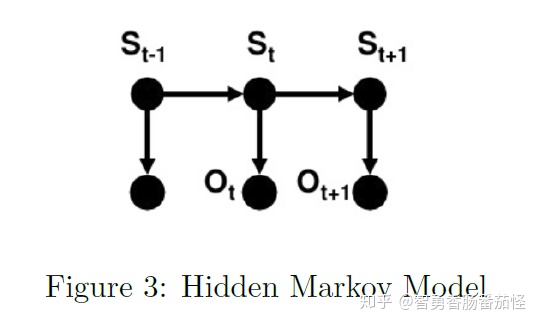
Conditional Random Field
2.1 From HMM to CRF
和HMM不同的是,CRF并没有做出上述的假设,CRF使用feature function来更抽象地表达特征,使得他不再局限于HMM的两类特征。一个特征函数可以表示为
where
The primary advantage of CRFs over HMMs is their conditional nature, resulting in the relaxation of the independence assumptions that required by HMMs. Additionally, CRFs can have arbitrary weights.
得到分布函数之后,我们只需要用最大似然估计估计参数
Negative Conditional Log-Likelihood:
对
第一项是与当前observation和真实state相关,第二项是对于所有可能状态输出,当前模型输出值。
为了更好理解CRF, 我们从CRF出发得到HMM模型,For each HMM transition probability
相似地, for each HMM emission probability
A CRF can be considered as a generalization of HMM or we can say that a HMM is a particular case of CRF where constant probabilities are used to model state transitions(e.g., we learn transition matrix in HMM which is constant).
Logistic Regression vs CRF
除了与HMM相似,CRF还可以看成序列化的logistic regression。他们都是判别式模型。Given input
我们再来看一下standard logistic function,这是一个sigmoid function, mapping
可以看到他们是几乎一样的,如果令
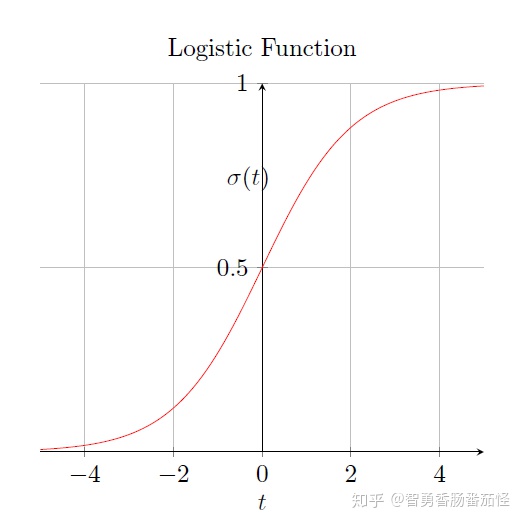
要理解CRF和LR的关系和CRF为什么是判别式模型,就要先理解LR。
对于一个二分类任务, 用bayes rule计算
将式子展开后,能用standard LR 表示。生成式模型估计 class conditionals
上式也被叫做normalized exponential 或 softmax,显然
In practice
3.1 Feature template
crf++ 和 sklearn crfsuite 都是现成的CRF工具包。这里用crf++举例说明。
实际使用中,我们需要先定义自己的特征模板Feature template,然后特征模板会生成特征函数。训练集通常用是CoNLL格式,如下图,表格内容是对特征模板的解析。

这样的输入序列能被写作
func1 = if (output = B-NP and feature="U01:DT") return 1 else return 0
func2 = if (output = I-NP and feature="U01:DT") return 1 else return 0
func3 = if (output = O and feature="U01:DT") return 1 else return 0
...
funcXX = if (output = B-NP and feature="U01:NN") return 1 else return 0
funcXY = if (output = O and feature="U01:NN") return 1 else return 0一个模板会生成
举个栗子, 一个用于NP chunking的训练集有两个句子"The cat is lovely. Montreal is a city." 对应的词性标注是 DT NN VBZ RB . NNP VBZ DT NN . 。chunking labels 应为 B-NP I-NP O O O B-NP O O O O 其中 B-NP, I-NP,O叫做"BIO" annotation,分别表示 begin,inside,outside of a noun phrase。假设有两个 unigram feature templates 为"U01%:x[0,1]" and "U02%:x[0,0]", we will go through the training samples token by token. 值得注意的是,在这个训练集中我们只有3种labels,5种词性标注, 和7个token types。
For the first token The, 3*5 and 3*7 feature functions will be generated for "U01" and "U02".
3.2 Weight Learning
训练的目的是为每个特征函数赋上权重
根据2.1中求得对一个
where
References
Lafferty, John, Andrew McCallum, and Fernando CN Pereira. "Conditional random fields: Probabilistic models for segmenting and labeling sequence data." (2001).
Another crf tutorial for NLP
Why Do We Need Conditional Random Fields?
what are conditional random fields
CRF与LR,生成式模型与判别式模型
CMU:从Bayes到LR到CRF
理解公式推导
从LR到CRF
MIT:从HMM到CRF的理解以及训练过程
buffalo:关于LR到CRF的推演
关于目标分布函数的优化
原始论文的解释
CRF与其他相关模型的比较
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









