





R语言数据输入
可供R导入的数据源,文本文件(txt、XML)、统计软件(SPSS、SAS)、键盘、其他(Excel)、数据库管理系统(SQL、MySQL)
在这里,我打算挑一些常用的。
使用键盘输入数据
两种方式
1、R内置的文本编辑器,使用edit()函数。
2、直接在代码中嵌入数据
第一种:R内置的文本编辑器,使用edit()函数
data data data #显示data数据框
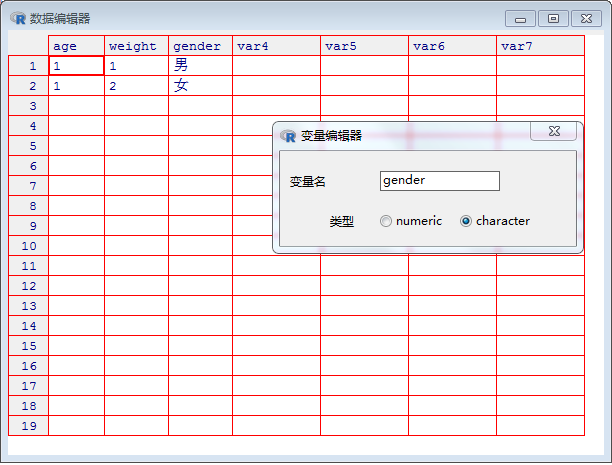
age weight gender
1 1 1 男
2 1 2 女
在这个对话框,我们可以给变量gender选择变量类型,有numeric和character两种类型。
输入完数据,结果会保存到之前赋值的对象中data
第二种:直接在代码中嵌入数据
可以参考之前推送的数据结构———下。里面有详细讲解
从带分隔符的文本文件导入数据
语法:
data
file是带分隔符.csv文件,输入该文件的地址。notice!不要直接复制粘贴文件路径,不然会得到如下错误。
data 错误: 由""D:\R"开头的字符串中存在'\R',但没有这种逸出号
"\"在R语言被认为是转义字符,应该改为"\"或者"/"才算正确。
options是控制如何处理的选项。
| 选项 | 描述 |
|---|---|
| header | 一个表示文件是否在第一行包含了变量名的逻辑型变量 |
| sep | 分开数据值的分隔符。默认是sep="",这表示了一个或多个空格、制表符、换行或回车。使用sep=","来读取用逗号来分割行内数据的文件,使用sep="\t"来读取使用制表符来分割行内数据的文件 |
| row.mames | 一个用于指定一个或多个行标记符的可选参数 |
| col.names | 如果数据文件的第一行不包括变量名(header=FALSE),你可以用col.names去指定一个包含变量名的字符向量。如果header=FALSE以及col.names选型被省略了,变量会被分别命令为V1、V2,以此类推。 |
| na.strings | 可选的用于表示缺失值的字符向量。比如说:na.strings=c("-9","?")。表示把-9和?值在读取数据的时候转换成NA |
| colClasses | 可选的分配到每一列的类向量。比如说,colClasses=c("numberic","numberic","character","NULL","numberic")。把前两列读取为数值型向量,把第三列读取为字符型向量,跳过第四列,第五列读取为数值型向量,如果后面还有列,重复循环。可以预见到,在遇到大型数据的时候,colClasses可以显著提高读取效率。 |
| quote | 用于对有特殊字符的字符串划定界限的字符串,默认值是双引号或单引号。 |
| skip | 读取数据前跳过的行的数目。这个选项在跳过头注释的时候比较有用 |
| text | 一个指定文字进行处理的字符。如果text被设置了,file应该被留空。 |
这是Studentgrades.csv文件的前几行
StudentID,First,Last,Math,Science,Social Studies
011,Bob,Smith,90,80,59
012,Jane,Weath,69,58,85
013,Dan,"Wkfa III",85,67,83
045,Mary,"O'Leat",75,65,86
我们用读取这个文件
data data
First Last Math Science Social.Studies
11 Bob Smith 90 80 59
12 Jane Weath 69 NA 85
13 Dan Wkfa III 85 67 83
45 Mary O'Leat 75 65 86str(data) #这个函数可以查看数据框的数据结构
'data.frame': 4 obs. of 5 variables:First:Factorw/4levels"Bob","Dan","Jane",..:1324 Last : Factor w/ 4 levels "O'Leat","Smith",..: 2 3 4 1Math:int90698575 Science : int 80 NA 67 65
$ Social.Studies: int 59 85 83 86
变量名Social Studies被自动地根据R的习惯所重命名。列StudentID现在是行名,不再有标签。Jane的缺失的科学课成绩被正确地识别为缺失值NA。不得不用引号包住Wkfa III,否则R会在那一行读出七个值,而不是六个。同时也不得不用引号包住O'Leat,否则R会把单引号读取为分隔符。我的第一列前面的0也不见了。
有时候导入数据和你想要的数据总是会有偏差,你想把缺失的去掉,该出现的没出现,改有的没有。
在后面我们会讲到把缺失值去掉,提取想要的数据,剔除不想要的数据。
默认的,read.table()把字符变量转化为因子,这并不是我们想要的情况,在此,可以加上选项colClasses选项去对每一列都指定一个类
如下代码,还是对Studentgrades.csv
data data
First Last Math Science Social.Studies
011 Bob Smith 90 80 59
012 Jane Weath 69 NA 85
013 Dan Wkfa,III 85 67 83
045 Mary O'Leat 75 65 86str(data)
'data.frame': 4 obs. of 5 variables:First:chr"Bob""Jane""Dan""Mary" Last : chr "Smith" "Weath" "Wkfa,III" "O'Leat"Math:num90698575 Science : num 80 NA 67 65
$ Social.Studies: num 59 85 83 86 #行名保持了前缀0,First和Last不再是因子,而是字符。
导入Excel数据
读取一个Excel文件最好的方式是在Excel中将其导出为逗号分隔文件(.csv),并使用前面描述的那样导入R中。
同时,有一个xlsx包直接地导入Excel工作表,相应的,你需要安装Java包。
install.packages("xlsx") #安装xlsx包
library("xlsx") #加载包
workbook mydataframe
今天的学习就到这里,有问题的小伙伴后台留言,一起学习进步。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









