






概览
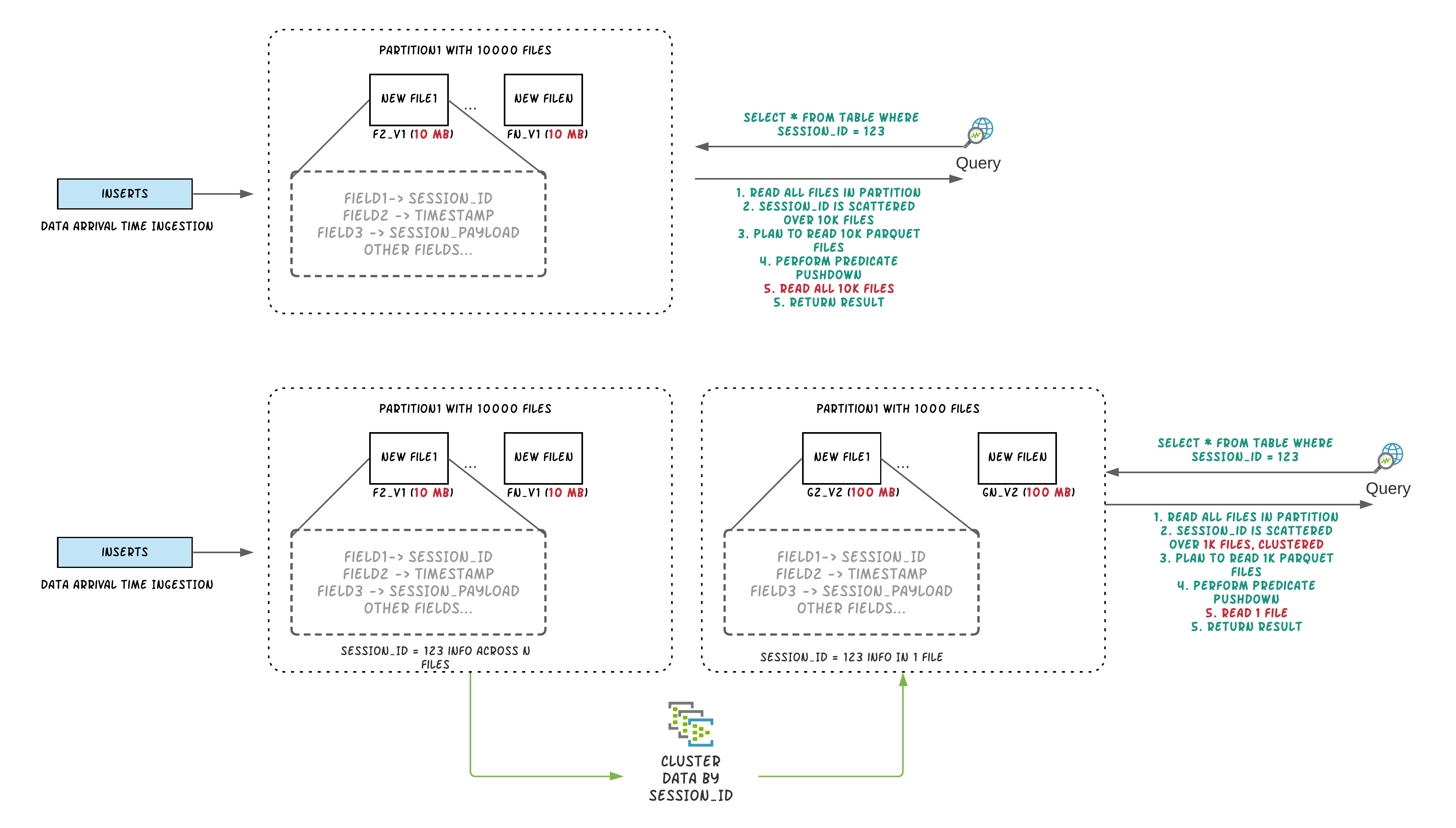
Apache Hudi为大数据带来了流处理,在提供新鲜数据的同时,比传统批处理效率高一个数量级。在数据湖/数据仓库中,关键的权衡之一是输入速度和查询性能之间的权衡。数据摄取通常倾向于小文件,以提高并行性,并使数据能够尽快用于查询。但是,如果有很多小文件,查询性能就会下降。此外,在摄入期间,数据通常根据到达时间在同一位置。但是,当频繁查询的数据放在一起时,查询引擎的性能会更好。在大多数体系结构中,每个系统都倾向于独立地添加优化,以提高由于未优化的数据布局而导致的性能限制。本博客介绍了一种新的表服务,称为clustering[RFC-19],用于重新组织数据,在不影响输入速度的情况下提高查询性能。
Clustering架构
在较高的层次上,Hudi提供了不同的操作,如insert/upsert/bulk_insert,通过它的写客户端API,能够将数据写入一个Hudi表。为了能够选择文件大小和摄入速度之间的平衡,Hudi提供了一个配置hoodie.parquet.small.file.limit,以能够配置最小允许的文件大小。用户可以将小文件软限制配置为0,以强制新数据进入一组新的文件组,或将其设置为更高的值,以确保新数据“填充”到现有文件,直到它满足增加摄入延迟的限制。
为了能够支持在不影响查询性能的情况下快速获取数据的架构,我们引入了一个“clusterin”服务来重写数据,以优化Hudi数据湖文件布局。
clustering table服务可以异步运行,也可以同步添加名为“REPLACE”的新操作类型,该操作将在Hudi元数据时间轴中标记集群操作。
两步进行Clustering
-
计划clustering:使用可插拔的clustering测录额来创建clustering计划。
-
执行clustering:使用执行策略处理计划,以创建新文件并替换旧文件。
计划clustering
按照以下步骤执行clustering。
识别适合clustering的文件:根据所选择的clustering策略,调度逻辑将识别适合clustering的文件。
根据特定的条件对符合clustering条件的文件进行分组。每个组的数据大小都是’ targetFileSize '的倍数。分组是作为计划中定义的“战略”的一部分。此外,还有一个选项可以设置组大小的上限,以提高并行性并避免调整大量数据。
最后,clustering计划以avro元数据格式保存到时间轴上。
执行clustering
-
阅读clustering计划并获得标记需要clustering的文件组的’ clusteringGroups '。
-
对于每个组,我们使用strategyParams(示例:sortColumns)实例化适当的策略类,并应用该策略重写数据。
-
创建一个“REPLACE”提交并更新HoodieReplaceCommitMetadata中的元数据。
clustering服务构建在Hudi基于MVCC的设计之上,允许写入器继续插入新数据,同时clustering操作在后台运行,以重新格式化数据布局,确保并发读写器和写入器之间的快照隔离。
注意:clustering只能被调度到没有接收到任何并发更新的表/分区。在未来,并发更新用例也将得到支持。
clustering对于查询性能的提升
设置clustering
使用spark dataframe选项可以轻松设置Inline clustering。请参阅下面的示例
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val df = //generate data frame
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, "tableName").
option("hoodie.parquet.small.file.limit", "0").
option("hoodie.clustering.inline", "true").
option("hoodie.clustering.inline.max.commits", "4").
option("hoodie.clustering.plan.strategy.target.file.max.bytes", "1073741824").
option("hoodie.clustering.plan.strategy.small.file.limit", "629145600").
option("hoodie.clustering.plan.strategy.sort.columns", "column1,column2"). //optional, if sorting is needed as part of rewriting data
mode(Append).
save("dfs://location");
对于更高级的用例,还可以设置异步clustering pipeline。参考:这里
表查询性能
我们从一个已知的生产样式表的一个分区中创建了一个数据集,该数据集有大约20M的记录,磁盘大小约为200GB。数据集有用于多个“sessions”的行。用户总是使用session上的谓词查询此数据。单个session的数据分布在多个数据文件中,因为输入根据到达时间对数据进行分组。下面的实验表明,通过对session进行聚类,我们可以提高数据的局部性,减少50%以上的查询执行时间。
执行查询
spark.sql("select * from table where session_id=123")
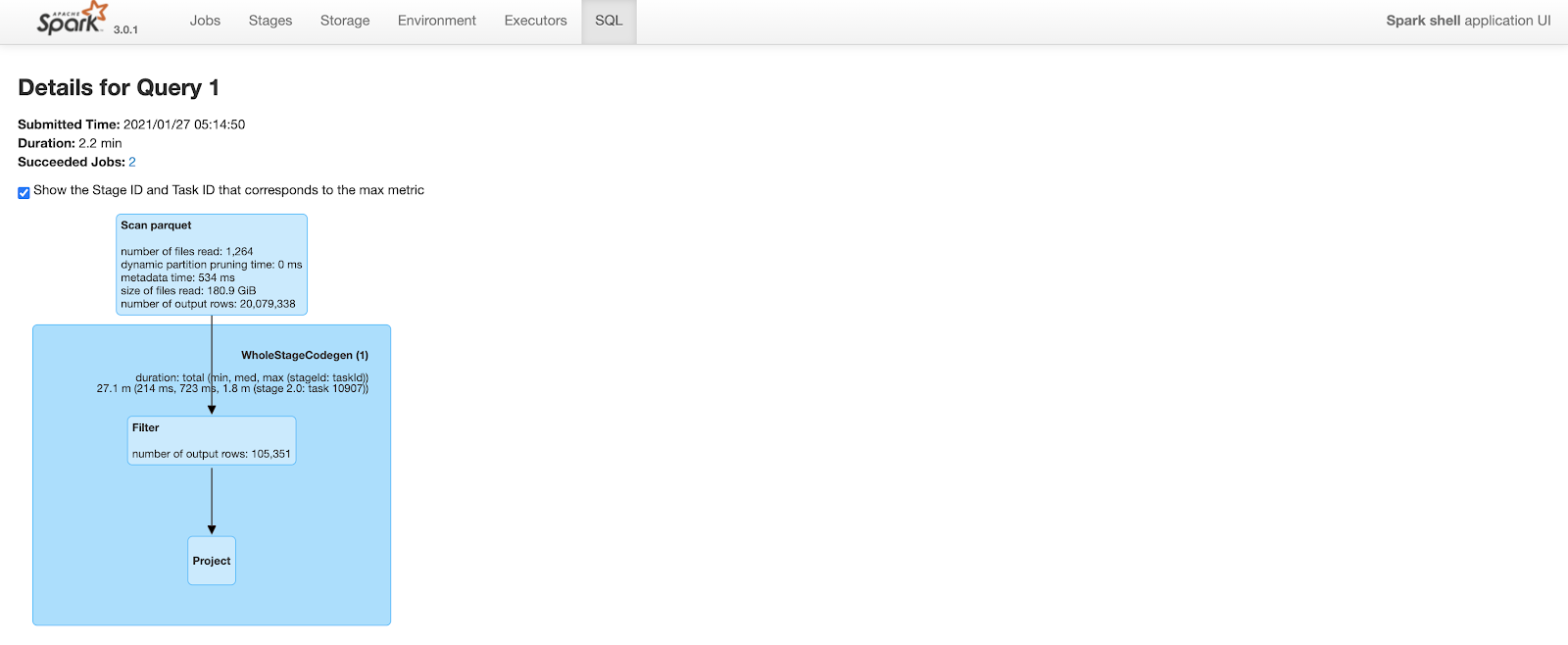
Clustering之前
查询耗时2.2分钟。注意,查询计划的“scan parquet”部分的输出行数包括表中所有20M行。
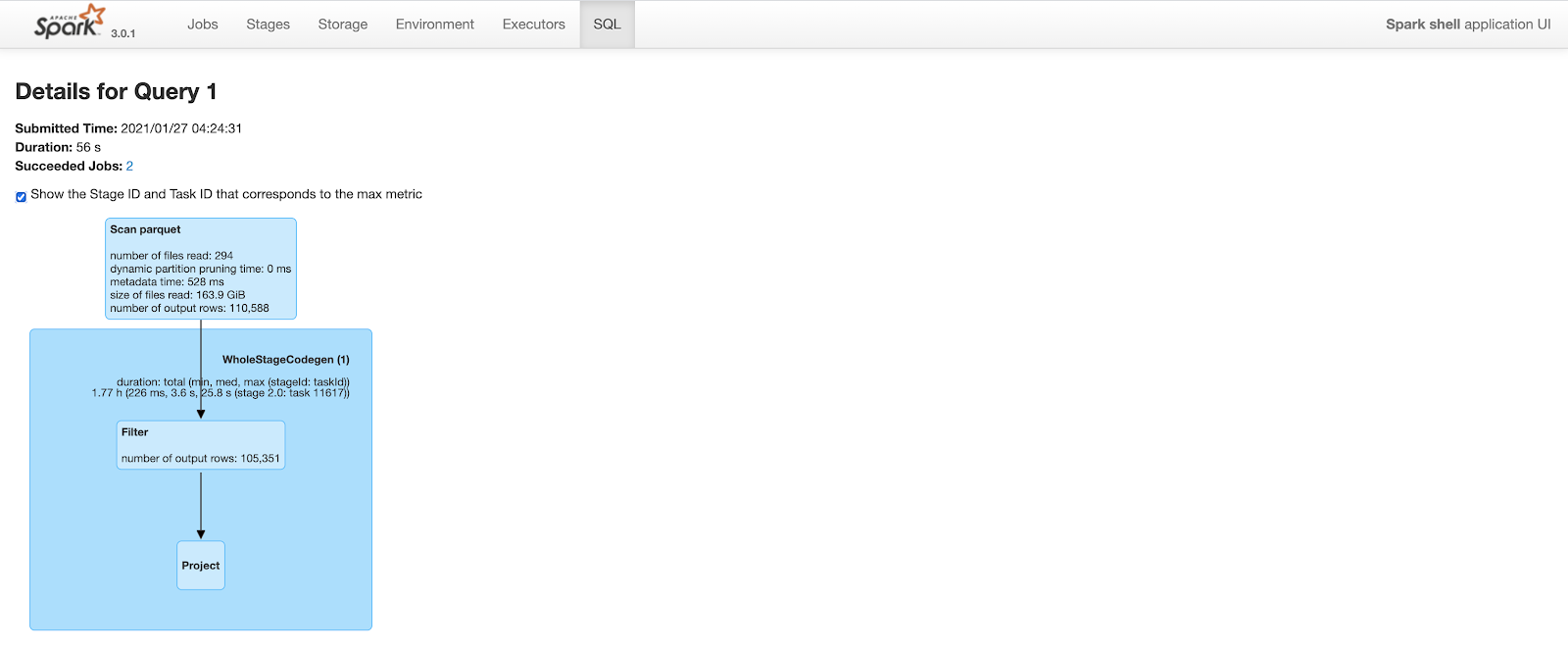
Clustering之后
查询计划与上面类似。 但是,由于改进了数据局部性和谓词下推,spark能够修剪大量的行。 clustering后,相同的查询在扫描parquet文件时只输出110K行(在20M行中)。 这将查询时间从2.2分钟减少到不到1分钟。
下表总结了使用Spark3运行的实验对查询性能的改进
| Table State | Query runtime | Num Records Processed | Num files on disk | Size of each file |
|---|---|---|---|---|
| Unclustered | 130,673 ms | ~20M | 13642 | ~150 MB |
| Clustered | 55,963 ms | ~110K | 294 | ~600 MB |
clustering后,查询运行时间减少60%。 在其他样本数据集上也观察到类似的结果。 参见RFC-19性能评估中的示例查询计划和更多细节。
我们期望在大型表中获得显著的加速,因为在这些表中,查询运行时几乎完全由实际I/O控制,而不是查询规划,这与上面的示例不同。
总结
基于cluster,你可以通过以下方式提高查询性能:
-
利用空间填充曲线等概念来适应数据湖布局,并减少查询期间的数据读取量。
-
将小文件拼接成大文件,减少需要查询引擎扫描的文件总数。
除此之外,clustering框架还提供了基于特定需求异步重写数据的灵活性。 我们预见到许多其他的用例采用带有自定义可插拔策略的clustering框架来满足按需数据湖管理活动。 一些值得注意的用例正在积极使用clustering解决:
-
重写数据并在静止时加密数据。
-
从表中删除未使用的列,减少存储占用。















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









