





MATLAB聚类算法
K-means聚类与层次聚类(1) kmeans聚类聚类算法是一种根据初始点不断迭代,最后将数据聚类的过程。matlab中实现Kmeans常用聚类函数如下:
[IDX,C]=kmeans(X,k)
[IDX,C,sumD,D]=kmeans(X,k)
输入参数:X为N*P输入矩阵,其中每一行表示一个点,每一列表示一个变量;k为聚类数;
返回参数:IDX,N*1向量,存储每个点的聚类标号;
C是k*P矩阵,存储k个聚类质心的位置;
sumD是1*k的和向量,存储的是类间所有点与该类质 心点距离之和;
D是N*K矩阵,存储的是每个点与所有质心的距离。
 在kmeans函数里,可以根据需要选择调用的参数
在kmeans函数里,可以根据需要选择调用的参数
1)‘Distance’:聚类距离的度量方式
默认欧氏距离,cityblock表示绝度误差和。
2)‘Start’:初始质心位置选择方法
sample表示从X中随机选择K个质心点;
uniform表示根据X的分布范围均匀的随机生成k个质心;
3)‘Replicates’(聚类重复次数):选取不同的初始点进行计算的次数,默认值为1
4)‘Options’:迭代的方式,需要创建一个statset变量,它包含如下两个参数
‘display’与 'MaxIter'(最大迭代次数)
 (2)层次聚类
(2)层次聚类
层次聚类方法是通过某种相似性测度计算节点之间的相似性,并按相似度由高到低排序,逐步重新连接个节点。
在matlab中使用linkage函数对元素进行分类,从而创建系统聚类树;使用dendrogram函数显示层次聚类树。
(3)Kmeans聚类分析
clc,clear;
close all;
X=[79 75 70.45 78.35 76.35 71.92 75.85 74.25 66.6...
71.05 51.75 87.87 68.3 77.55 75.8 70.68 74.9...
71.3 77.2 77.8 75.2 66.65 75.7 77.3 77.8 70]';
%行向量变为列向量,这里只用了一列数据,也可以使用多个变量数据进行聚类分析。
[x,y]=size(X);
opts = statset('Display','final');
K=11; %将X划分为K类
repN=50; %迭代次数
%K-mean聚类
[Idx,Ctrs,SumD,D] = kmeans(X,K,'Replicates',repN,'Options',opts);
%Idx N*1的向量,存储的是每个点的聚类标号
%打印结果
fprintf('划分成%d类的结果如下:\n',K)
for i=1:K
tm=find(Idx==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类共%d个分别是%s\n',i,length(tm),int2str(tm)); %显示分类结果
end
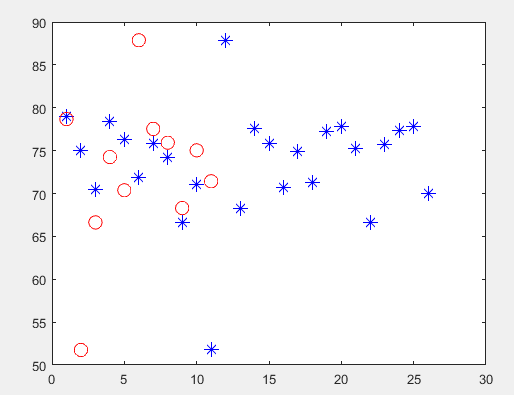
figure(1)
plot(X(:,1),'b*','MarkerSize',10);
hold on
plot(Ctrs(:,1),'ro','MarkerSize',10);
K-means聚类结果:

聚类结果绘图:
(4)层次聚类分析示例
A=[79.95 75 80.45 78.15 76.25 71.95 75.85 71.85 76.6...
77.05 71.85 67.85 68.9 74.55 75.4 70.65 79.55 74.9...
74.3 77.2 77.8 75.2 76.65 74.7 78.3 77.8 70.9];
X=A';
Y=pdist(X); % 计算样本点间的欧氏距离
Z=linkage(Y,'average');
%%%利用linkage函数创建聚类树——Y是距离函数,average表示使用类平均算法,Z是返回系统聚类树。
%%%‘average’可以用其他算法代替,如:single表示最短距离算法;%complete表示最长距离算法;median表示中间距离算法;
%centroid表示重心法;ward表示离差平方和法
cn=size(X);
clabel=1:cn;
clabel=clabel';
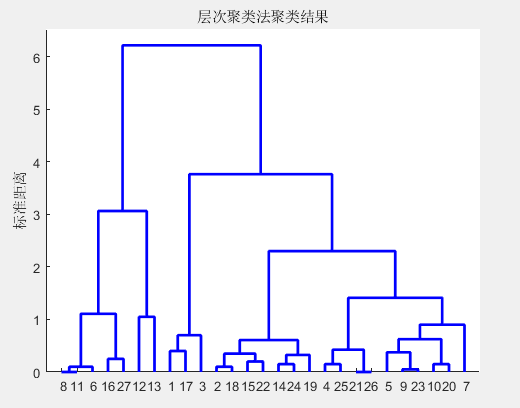
figure
F2=dendrogram(Z); %显示系统聚类树
title('层次聚类法聚类结果');
set(F2,'linewidth',2);
ylabel('标准距离');
(5)层次聚类分析示例2
clc,clear
a=[79.95 75.55 80.45 78.15 76.25 71.95 75.85 71.85 76.6;
49.05 51.85 67.85 19.9 34.55 25.44 80.65 67.88 88.97;
75.78 65.22 87.87 45.66 44.78 44.55 44.98 57.98 55.89];
X=a';
[m,n] = size(a);
d = mandist(a')
d = tril(d);
nd = nonzeros(d);
nd = union(nd,nd);
for i = 1:m-1
nd_min = min(nd);
[row,col] = find(d == nd_min);tm = union(row,col);
tm = reshape(tm,1,length(tm));
fprintf('第%d次合成,平台高度为%d时的分类结果为:%s',i,nd_min,int2str(tm));
nd(find(nd == nd_min)) = [];
if length(nd) == 0
break
end
end
%% 生成聚类图
y = pdist(a,'cityblock'); %求a的两两行向量之间的绝对值距离
yc = squareform(y); %变换成距离方阵
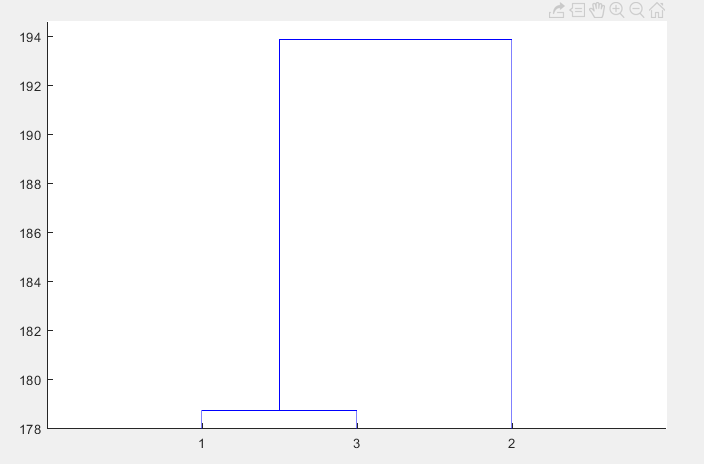
z = linkage(y) %生成等级聚类树
[h,t] = dendrogram(z) %绘制聚类树
T = cluster(z,'maxclust',3) %把对象划分成3类,通过观察聚类数效果确定分类数目。%%%%分类数可自己根据实际情况修改。
for i =1:3 %3对应上一行的分类数目
tm = find(T == i); %求第i类对象
tm = reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有%s\n',i,int2str(tm)); %显示分类结果
end
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









