





这里有最简单的一类验证码:他们有固定的背景颜色,相同的字符颜色和字体,字符的坐标位置也是固定的。

对于这类验证码,我们只需要对每个数字进行采样,建立标准库,然后应用的时候一一对照标准库,就可以轻易做到100%识别。
使用ImageCreateFromPNG函数把图片取回来,然后用imagecolorat函数取得每一个坐标点的色值,并且把第一个点的颜色确定为背景色。
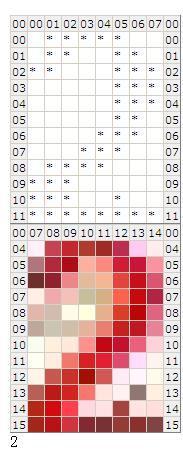
然后按照图像大小比例画一个表格,如果该单元对应的坐标颜色与背景色相同,不显示任何内容;反之显示黑色块。于是我们得到这样的分解图:

可以观察到,数字所占区域的y坐标是6-15,四个数字所占区域的x坐标分别为3-10,12-19,21-28,30-37。于是建立以0-9为样本建立10个二维数组($arr_eg[0] – $arr_eg[9]),该数组每一个元素均对应该数字区域的每一个坐标,如果该坐标色值与背景相同,值为0,反之为1 。这就是我们的标准库。
识别的时候,同样取得四个数组,与标准数组一一对照,就可以精确地把四个数字识别出来。
以上的例子虽然简单,但是已经把基本原理介绍清楚了,就是 采样->建立标准库->应用->对照标准库->识别。但是,实际应用中,遇到的往往不是如此简单的情况。比如下面是稍微复杂的一类验证码,它的背景和字符都不是纯色,还有很多干扰点,但其字符的坐标都是固定的。

首先我们对其进行去噪处理。就是首先把每个字符区域分割出来,按照出现的频率确定其主色值(字符的色值),然后去除与其相差大于一定程度的坐标,过滤之后得到目标所在的坐标数组,然后同样与标准库对照。但是这种情况下是不会精确吻合的,我们只能选择吻合度最高的昨作为结果。经过实践,识别率可以达到99%。
再难一点的,就是下面这种:使用了变色、干扰点、干扰线、变位等几种用于干扰手段。
与上一种不同,它的每一个字符所在的位置是不确定的,这就需要我们自己去确定其位置,把字符所占据的大小固定的那一个小块切出来。首先把所有的干扰点和干扰线去掉(去掉之后字符是有所“误伤”的,通常会缺1-3个像素点),得到比较干净的图,然后用一条横向和竖线去扫描它(比较形象的说法,具体如何实现请自己思考),把扫到的没有出现颜色的横竖线全部去掉,把分析范围缩到一个较小区域。然后再用竖线扫描,根据颜色的出现与否,又得到5个小区域,每个小区域再用横线扫,除去空白,得到目标区域。得到的目标区域有时候会比标准区域小想办法补全,然后对照,按吻合率最高的原则得出结果。最后识别率达90%以上。


















 4714
4714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









