



 本文介绍了乱码产生的根本原因——编码和解码所采用的字符集不一致,并提供了四种解决乱码的方法,包括调整编码格式、更改浏览器解码方式、使用记事本编写代码以及在网页头部添加meta标签。
本文介绍了乱码产生的根本原因——编码和解码所采用的字符集不一致,并提供了四种解决乱码的方法,包括调整编码格式、更改浏览器解码方式、使用记事本编写代码以及在网页头部添加meta标签。
- 乱码问题的原因:计算机只识别0,1,在计算机中的任何内容最终都会转化为0,1这种二进制编码来保存。如果一旦在编码或者译码的过程中出现问题均会造成乱码问题。
- 产生乱码的根本原因:编码和解码所采用的字符集不同。
- 首先了解一下基本知识
- 编码:依据一定的规则,将字符转化为二进制编码的过程。
- 译码:依据一定的规则,将二进制转化为字符的过程。
- 字符集:常用的字符集:
常用的字符集:ASCII,IOSO-8859-1,GBK,GB2312,utf-8
其中,GB2312为中文系统默认的编码与解码字符集;utf-8为万国码,为多种语言的编码方式。
4.解决办法
(1)改编码:使用notepad++编辑器:由于中午系统 的解码字符集均采用GB2312,所以将编码方式改为GB2312字符集,改变方式如下:
编码--->查看字符集->中文->GB2312,即可改变编码格式,
(2)改译码方式
在浏览器中 ALT--->查看--->编码--->utf-8
(3)使用记事本编写代码:
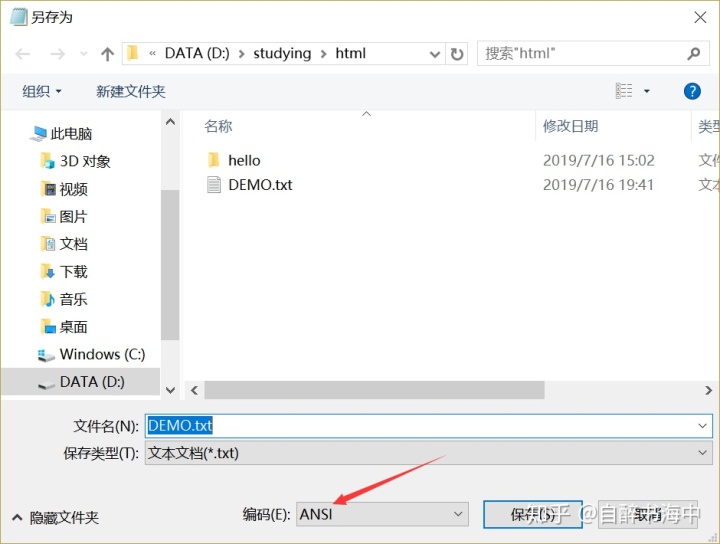
编码为ANSI,即为以系统的默认编码保存文件,识别系统编码译码方式,所以不会出现乱码问题。
(4)在代码头文件中添加meta标签,告诉浏览器网页所采用的编码字符。
<!--解决解码问题DEMO-->
<!doctype html>
<html>
<head>
<!--
需要告诉浏览器,网页所采用的编码字符集,浏览器会使用所使用的字符集解码,不会产生乱码情况。
-->
<meta charset="utf-8"/>
<title>这是一个网页标题</title >
</head>
<body>
<h1>有关解码问题的Demo</h1>
</body>
</html>
乱码问题暂时遇到这么多,欢迎指正~~~感谢

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









