





上节对fork的基本功能进行了介绍,下面进一步讨论和分析。我们通过一些代码来加深理解。
代码1:
#include <stdio.h>
#include <unistd.h>
int main(){
int acpid;
acpid = fork();
if(acpid >0){
printf("1n");
wait();
printf("2n");
}
else{
printf("3n");
sleep(1);
}
}我们看一下wait的函数是等待任何一个子进程结束。那么上面这段代码的执行结果是什么呢?
大部分情况下,和我们的分析是一致的:
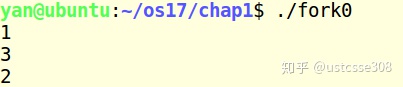
父进程打印出1,然后等待子进程,子进程打印3,然后sleep 1秒,子进程结束,父进程打印出2。但也有以下的结果:
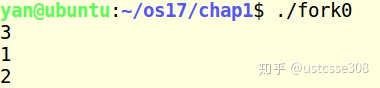
大概运行几十次可能会出现一次。这种情况下,就是父进程在生成子进程之后,子进程首先获得执行。为什么会出现这种情况呢?我们现在使用的操作系统是分时系统,也即,多进程切换执行。到底是子进程先执行还是父进程先执行,完全取决于系统的调度情况。
代码2:
#include <unistd.h>
#include <stdio.h>
int main(){
fork();
printf("pid is %d, ppid is %d.n",getpid(),getppid());
wait();
}
getpid也即获得当前进程的pid,getppid获得父进程的pid。

从上面的运行结果能够看出来什么呢?
首先注意到在第二行打印出的两个pid总是相差1。可以想见,进程的id号作为一个整数,在系统中也是从小到大,逐渐增加的。而第一行打印出来的ppid总是确定的,2583。那可以思考一下,这两行哪个是父进程,哪个是子进程?
当然,因为第一行的pid就是第二行的ppid,所以毫无疑问,第一行是父进程,第二行是子进程。
问题:父进程的父进程又是谁呢?而且可以看到,连续多次运行,这个父进程都是不变的。
上面的代码可以修改一下,把wait()给注释掉。

这里可以判断出来33114是父进程,33115是子进程。但是这里33115的父进程变成了1841。这是为什么呢?而且可以看到子进程打印的时候是在shell已经输出了新的提示行之后。如何理解呢?
代码3:
#include <unistd.h>
#include <stdio.h>
int main(){
fork();
fork();
fork();
printf("pid is %d, ppid is %d.n",getpid(),getppid());
wait();
wait();
wait();
}上面的代码中总共会打印多少行printf呢?
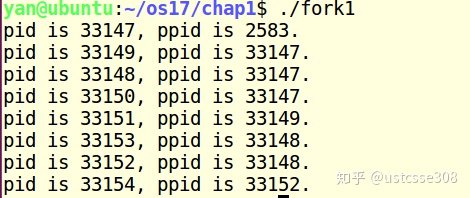
理解一下,33147就是fork1进程本身,它需要执行三个fork,所以有三个子进程的父进程都是它;然后第一个子进程是33148,148还有两个fork需要执行,所以148有两个子进程。这里总结一下,有三个fork语句总共有8个printf。在第一个fork之后会有两个进程,两个进程都运行第二个fork,在第二个fork之后总共会有四个进程;相应地,在第三个fork之后会有8个进程。
思考下面的代码会有多少行的打印:
#include <unistd.h>
#include <stdio.h>
int main(){
fork();
fork() && fork() || fork();
fork();
printf("pid is %d, ppid is %d.n",getpid(),getppid());
}这里主要考虑到&&和 ||的短路性质,譬如可以先考虑下下面的代码:
#include <stdio.h>
int main(){
int i=1;
int j=2;
// (i=3) && (j=4);
// (i=0) && (j=4);
// (i=3) || (j=4);
(i=0) || (j=4);
printf("i=%d, j=%d.n",i,j);
}
代码4:
fork bomb:
当尝试创建无限数量的进程时,也就出现了“fork炸弹”。 一个简单的例子如下所示:
while(1)fork();这通常会使系统崩溃,因为系统会将CPU时间和内存分配给准备运行的大量进程。系统管理员为了防止fork-bombs,可以对每个用户可以拥有的进程数量设置上限,还可以使用setrlimit()限制创建的子进程数。
【不想运行这个代码 :)】
代码5
#include <unistd.h> /*fork declared here*/
#include <stdio.h> /* printf declared here*/
int main() {
int answer = 84 >> 1;
printf("Answer: %d", answer);
fork();
return 0;
}这个代码的运行结果是什么呢?在经历过上面代码之后,可能觉得这个太简单了。这个的区别是printf()在fork之前。那么结果是什么呢?

结果打印了两次。然后再尝试一下下面的代码:
#include <unistd.h> /*fork declared here*/
#include <stdio.h> /* printf declared here*/
int main() {
int answer = 84 >> 1;
printf("Answer: %dn", answer);
fork();
return 0;
}
看一下结果,这次只打印了一次。
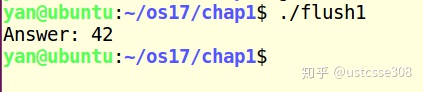
原因是:printf行虽然只执行一次,但是第一份代码中,打印的内容没有刷新到标准输出(没有打印换行符), 因此,输出文本仍在进程内存中等待发送。 执行fork()时,将复制整个进程内存,包括缓冲区。 因此,子进程以非空输出缓冲区开始,该缓冲区将在程序退出时刷新。
接下来看一下exec。
#include <stdlib.h>
#include <unistd.h>
int main(){
execl("/bin/more","more",NULL);
// execl("more","more",NULL);
/* We can only reach this code when there is an error in #execl*/
perror("failed!");
exit(1);
}
execl是exec六个系统调用中的一个,用来执行一个可执行文件;主要是参数的不同,像execl主要第一个参数要给它要执行的二进制代码的路径。
看到上面的代码,主要的一个疑惑可能是为什么会有
perror("failed");怎么还没做就在报错。
这里要深刻理解一下,exec是要运行另一个程序,也即要使用另一个程序的可执行的指令替换自己当前进程中的指令。也即,如果exec执行成功,那么perror代码就完全被替换掉了。只有在exec执行失败的时候才会看到failed。
到这里,可以再体会一下上一节的shell代码。
最后再看下silly fork代码。就是杀鸡用牛刀的意思,用fork实现一些本来比较简单的任务。
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv) {
pid_t id;
int status;
while (--argc && (id=fork())) {
waitpid(id,&status,0); /* Wait for child*/
}
printf("%d:%sn", argc, argv[argc]);
return 0;
}上面的代码实际的效果是逆序打印出来main函数的参数。代码的思路就是父进程可以进入while中的代码,而子进程则直接进入打印,因为while的条件是--argc,所以是逆序的;同时while要求父进程等待子进程,所以一次打印完成之后,才会创建新的子进程,所以也不会乱序。譬如:

大家可以试一下把wait去掉看看效果。
还有一个更silly的:
int main(int c, char **v)
{
while (--c > 1 && !fork());
int val = atoi(v[c]);
sleep(val);
printf("%s,%d,%dn", v[c],getpid(),getppid());
return 0;
}看一下执行结果:
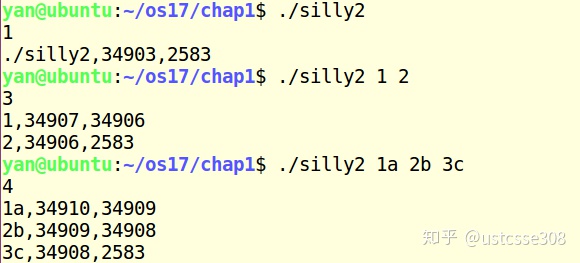
这里的while(--c > 1 && !fork()); 父进程会因为!fork()条件不满足,而直接开始执行while后面的语句;而子进程如果--c满足会再进行fork。因为--c>1,所以当c为2的时候就不能再执行了。
而如果没有带参数,也即c=1的时候,那么因为&&的短路特点,所以不会执行fork(),只有一个进程。
以上就是一些有趣的代码。
最后再来讨论下孤儿进程和僵尸进程。
孤儿进程前面已经见到过,因为子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵尸进程。
可以看一个代码:
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <stdlib.h>
int main()
{
pid_t pid;
pid = fork();
if (pid < 0)
{
perror("fork error:");
exit(1);
}
else if (pid == 0)
{
printf("I am child process %d. I am exiting.n",getpid());
exit(0);
}
printf("I am father process %d.I will sleep two secondsn",getpid());
//等待子进程先退出
sleep(2);
//输出进程信息
system("ps -o pid,ppid,state,tty,command");
printf("father process is exiting.n");
return 0;
}
看一下运行结果:
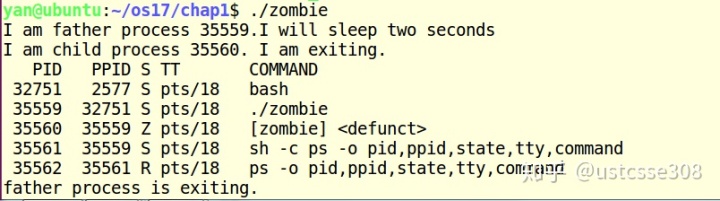
关于孤儿进程和僵尸进程的解释,在参考文献中解释的很清楚。
unix提供了一种机制可以保证只要父进程想知道子进程结束时的状态信息, 就可以得到。这种机制就是: 在每个进程退出的时候,内核释放该进程所有的资源,包括打开的文件,占用的内存等。 但是仍然为其保留一定的信息(包括进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等)。直到父进程通过wait / waitpid来取时才释放。 但这样就导致了问题,如果进程不调用wait / waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个 子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是“Z”。如果父进程能及时 处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态。 如果父进程在子进程结束之前退出,则子进程将由init接管。init将会以父进程的身份对僵尸状态的子进程进行处理。
在上面的代码示例中,可以看到子进程实际上已经使用了exit退出,但是仍然可以看到状态(S)为zombie(Z)的进程。但是当父进程也结束之后,看不到僵尸进程了。
所以这边主要的一个问题是,很多同学有点想不通,什么情况下 父进程会产生大量的子进程而自己还不退出。其实shell就是这样的一个例子;但是shell会等自己的子进程结束。还有一个例子就是web服务器,要不停产生新进程来处理新的请求。
所以考虑到这些,就能够理解APUE书中,作者所说的要fork两次,在上面的参考文献中也讲了这个问题。
参考:
- https://www.cnblogs.com/Anker/p/3271773.html















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









