





1. 引言
我最初接触编程,是在有“C9联盟C位成员”、“马家沟女子稀少大学”、"东方小麻省"之称的哈工大的C语言课上。当时每堂课都感觉有点郁闷,不知道自己在干什么。当时讲课是一位梳着马尾辫的女老师,非常耐心,一点一点地告诉我们C语言到底是啥。然而我还是各种不明白。我不得不去网吧熬夜,写了好多非常简单的代码,逐渐才理解了C语言是啥东西,也理解了当我在写程序的时候,我真正在做的是完成一个任务的自动化。
学习C语言过程中的困难来源比较多,主要是作为一个傻乎乎的没听过编程、不知道有程序员这么个职业的小白,我感觉需要记忆的东西有点多——我需要记住各种规则、各种概念,然后才能写出程序。感觉总是差一点才能写出一个可以跑起来的程序。
C语言的基础最后到底是学明白了,不过我后来一直没有使用它。C语言的代码量是比较多的,比如我要写一个高质量的文本数据预处理程序,得费老劲。人生苦短啊。
有没有啥语言学起来简单,用起来也简单呢?有,python。如图1-1是这里的主要内容,比大部分编程语言入门所涉及的内容要少很多。图1-1 目录
2. Python正传
2.1. python的起源和发展
上世纪60年代末,一个叫做Monty Python英国喜剧团体开始活跃起来,发行了《巨蟒剧团之飞翔的马戏团
》(Monty Python's Flying Circus,豆瓣主页巨蟒剧团之飞翔的马戏团 第一季 (豆瓣)movie.douban.com
)等一系列好玩的电视节目。这个天团的粉丝很多,包括后来成为计算机科学家的Guido van Rossum。80年代末,Guido van Rossum开始开发和维护一种独具特色的解释器,并引用了喜剧天团的名字、给它起名为”Python”。
Guido van Rossum开发Pyhton的目的,是创造一个使用起来尽量简单的脚本语言,以降低自己的工作量。相比C、Java等语言,Python的代码看起起来更像自然语言;写起来也是。Python还自动完成了内存管理之类的事情,让程序员需要做的、需要懂的事情大大降低。在不要求性能的场景里,Python是最适合我们的编程语言之一。
后来, Jim Hugunin 和他的朋友们为Python开发了一个叫做NumPy的库,专门用来做数值计算。NumPy是用C/C++/Fortran开发的,性能极高——在数值计算场景中,Python可以完成任务的逻辑部分,并依靠NumPy完成计算量比较大的环节,进而实现高性能的计算。
再后来, 人们又为Python开发了Pandas、SKlearn、Tensorflow等等第三方库,让Python在数据相关场景里,成为最受欢迎的语言之一。
2.2. Python不是最好的语言
人人都爱排名,人人都爱PK。如果我喜欢的球星比你的偶像水平更高,我就拥有对你的优越感。迈克尔.乔丹的粉丝大概是优越感最强的篮球迷了。程序员也有类似的爱好——大家喜欢讨论哪一种语言是最好的,使用这种语言的程序员会有一种幻觉:和使用的语言一样,自己也是最牛的。
那么世界上有没有最好的编程语言呢?有人认为有,那就是PHP (https://www.beehiveforum.co.uk/faq/),如图1-1www.beehiveforum.co.uk
。当然,作者是以开玩笑的语气说的这段话。看起来,Ta实际上认为不存在什么“最好的编程语言”。其他人说PHP最好,都是在起哄。图2-1 PHP最好的原因
我个人(不多的)体会是:(1)编程语言确实有好有差,设计较差的语言咱们一般也见不到;(2)我们常见的这些编程语言,也就是水平最高的这部分,没有绝对的优劣,只是各有千秋,比如python在数据科学相关任务中,比绝大部分语言都要便捷。
3. 用python写一个HelloWorld
在著名的《The C Programming Language》中, Brian W. Kernighan 和Dennis M. Ritchie 使用一个打印输出字符串的程序,介绍了C语言代码的基本构成。之后的程序员在介绍一种编程语言的用法时,沿用了这种形式。这里也随个大流。
一个可以打印输出“hellowworld”字符串的python程序hello_wordl.py内容是这样的:
是的,只需要这一句,计算机就会在控制台中输出如下字符串。
当这个脚本写的有点过于简单,有一定的隐患。
4. 如何配置一个Python开发/学习环境
4.1. 安装python
当我们说“安装python”,就是说要安装一个软件,它可以解释和运行python代码的解释器,并为开发者提供了必要的工具包。
Python的安装方式可以参考Python3 环境搭建 | 菜鸟教程www.runoob.com Python 环境搭建 | 菜鸟教程www.runoob.com
Python 环境搭建 | 菜鸟教程www.runoob.com
,现在看起来真是亲切。2016年及以前,大家主要用的是python2,这份教程里主讲的也是python2。2017年开始,尤其是“2019年以后Python2不更新”的消息传出来以后,使用python2的朋友们开始快速的向python3迁移。现在,我们说”python”时,默认指的是python3。
4.2. 常见的IDE
集成开发环境(IDE)是这样一种软件,它把代码编辑器(文本编辑工具)、编译器(用来解析和转换代码的工具)、调试器、图形界面等必要工具集合到一起,支持程序员在可视化、直观的操作界面中进行代码编写、代码分析、代码编译、代码调试等操作。比如号称宇宙最强IDE的Visual Studio,就是一个经典的集成开发环境。
我比较熟悉的,是Eclipse和PyCharm。这是两个开源,也就是免费的软件。
4.2.1. PyCharm
PyCharm看起来是最酷的IDE之一。PyCharm的官网是https://www.jetbrains.com/pycharm/。PyCharmwww.jetbrains.com
的一个视图里,只能放一个项目,这点有些不方便。
4.2.2. 带有PyDev插件的Eclipse
我的领导,息哥以前是一个Java程序员,用惯了Eclipse。后来需要写Python程序时,他给Eclipse安装了一个插件,然后开始Java、Python双修。
默认情况下,Eclipse是最适合用来写Java程序的工具之一。当然了,Eclipse也可以用来写其他的语言。这需要我们给Eclipse安装一个用于支持python开发的插件。具体配置方式可以参考python+Eclipse+pydev环境搭建 - Bonker - 博客园www.cnblogs.com
5. python的基本语法与常用数据类型、数据结构
5.1. 标准数据类型
和其他编程语言一样,为了支持人们进行各种各样的数据操作,Python提供了几种标准数据类型,如表,比较少。
Python里所有的数据,包括int等,都被封装成了类。每一个变量都是一个对象,变量名实际上是一个指向对象的引用。这就是Python中所有数据的整体逻辑结构。
Python是一种“动态类型”语言,不要求程序员告诉解释器一个变量的数据类型,而是在解释运行的时候、自己推断。
表5-1 Python的标准数据类型
5.2. Python是动态类型语言
Python是一种动态类型(dynamically typed)语言。“动态类型”的意思是,在程序运行的时候,解释器会检查变量的类型,以确定是否存在对某些类型数据的错误使用,比如把字符串和整数拼接起来。
比如,python函数输入的类型,相当于Java的泛型,可以是任意类型。只有程序运行到函数内部,参数发生计算的时候,解释器才知道类型相关的配置是否正确。
相对地,还存在静态类型(static typed)语言。这类语言,在编译的阶段,就会对变量类型进行检查,告诉程序员那里出现了变量类别相关的错误。在程序运行的时候,计算机就不考虑是否有这种错误了。你懂的,这样就会为程序运行阶段节省一些开销。
在python中创建一个变量非常简单,比如:
a=666
向python函数传参也是非常自由,比如:
def printAny(x):
print(x)
if __name__==”__main__”:
printAny(“字符串”)
printAny(666)#输入整数
printAny([1,2,3,4])#输入列表
python里用换行和缩进来划分代码块,这个需要习惯一下。
5.3. 常见数据结构详解
Python里所有的数据都是对象,都是引用数据类型。每一个变量名都是一个引用、存储在栈空间里,指向堆空间里的一个数据块、即变量的取值。因此,从微观角度讲,我们在赋值的时候,实际上是引用的修改:把等号左边的变量名对应的引用指向修改为指向右边变量所指向的位置。
6. python的函数和库
6.1. 函数的定义
函数是所有编程语言必不可少的代码管理工具。Python的函数定义非常简单,使用”def”关键字即可,如代码6-1。函数的第一行由4部分组成:”def”关键字表示这个代码块是一个函数;字符串“a_simple_task”是这个函数的名称;小括号里是函数的输入参数;冒号表示代码块开始。注意,函数的参数中有一个”epoch=6”,这是python为函数的参数配置默认取值的方式。带有默认取值的参数,在调用函数时可以选择不显式传入,即使用默认取值。
#打印一段文本若干次
def a_simple_task(text_content, epoch=6):
for _ in range(epoch):
print(text_content)
6.2. 库的引用
6.2.1. 我们使用import时发生了什么?
有时候,我们需要基于第三方库或者自有库来开发某些内容,这时候需要把这些库或者里面的代码引入到当前代码中。我们可以使用“import”关键字来实现。
那么,”import”关键字做了什么呢?python解释器会把import指向的目录或文件里的所有代码都加载到内存里,并解释(运行)一遍。如果是函数定义、类或者变量,就放在内存里了;如果是一个具体的操作,比如打印输出,也会执行。因此,当我们导入3节所述的hello_wordl.py脚本时,会执行里面的所有语句。假如这里写了一些特别重的任务,导入一个模块的消耗就会很大。
一般情况下,我们不希望导入一个脚本就执行里面的内容,而是希望使用里面的函数、类和变量。这时候,我们可以使用一个简单的操作,把不希望被执行的部分圈起来。解释器在读到“if __name__ == '__main__':”时,会判断当前函数的名称是否为主函数。我们导入的模块的__name__变量取值,与脚本文件同名,因此if判断不会通过,里面的代码就不执行。而启动脚本所在模块的__name__取值是“”“__main__”,这个脚本里的main函数内容会被执行。
if __name__ == '__main__':
print("哈罗")
6.2.2. 第三方库的引用
一般来说,我们在安装第三方库的时候,已经把它们的路径添加到了环境变量中,可以直接使用”import”关键字来导入。
import random
print(random.uniform(0, 1))#基于0-1之间的均匀分布,生成一个随机数
6.2.3. 自有库的导入
有时候,我们自己也会开发一些库,需要在项目的某些地方引用。由于我们的自有库还没有添加到环境变量中,简单使用“import关键字”会失败。
Python解释器自动把启动脚本所在目录里添加到了环境变量中。解释器认识这个根节点里的所有脚本,可以直接使用”import”来导入这些库以及里面的代码。
而启动目录的上一级目录,或者同级别目录里的代码,由于不在操作系统环境变量中,无法直接导入。我们需要在代码中,手动地把相关目录中,最高级别的那一个添加到环境变量中。这样,解释器就可以知道去哪里找需要的脚本和代码了。具体可以看https://blog.csdn.net/xxxx000/article/details/79946709blog.csdn.net
7. 类、对象与继承
一说到编程语言,我们就不得不提到“类”和“对象”这对概念。大部分业务场景都可以想办法抽象为若干个事物互动形成的系统。类是这些事物的抽象描述。“类”和“对象”可以极大地提升我们对代码管理的效率,降低脑力、时间、试错等方面的代价,在软件开发领域是一个非常重要的模型。由于使用简单(当然实际应用时细节比较多)、功能丰富,类 和对象的应用十分广泛。从最初的启蒙,到现在的工程实践,我经历了计算机程序开发的两种编程思想:面向过程和面向对象。我的体会是,面向对象是一种非常有用的开发思想。
由于类和对象的关系比较特殊,一般人们会把它俩放在一起讲。但是这样做又会让我们犯迷糊,把二者混淆起来,因此有了7.2的标题名。但是,面向对象的编程思想确实是有用,付出一点代价整明白还是值得的。
7.1. 面向对象的出现是必然的
我的同事里有几个水平比较高的程序员,他们有时候会讨论"面向过程"和"面向对象"的优劣势和趋势。当然,我不太懂,这里基于自己的经历和体会来说一下面向对象编程思想带来的好处。
7.1.1. 纯过程有点累
一开始的时候,我认为所有的任务都需要拆解为一个流水线,流水线上有若干道满足特定需求的工序,流水线的最终输出是满足最终需求的所有数据。直观来说,就是用一个个函数,把原始数据做一道道加工后,得到最终的计算结果。比如下面的代码,用两个函数来描述玩扑克牌游戏时,玩家的两种操作。
#/math.py
def add(a, b):
return a + b
def 双倍(a):
return 2 * a
if __name__ == '__main__':
x1 = 66
x2 = 23
y1 = add(x1, x2)
y2 = 双倍(y1)
后来,随着工作内容越来越复杂,我的函数库越来越庞大,管理起来越来越困难。什么叫"管理"呢?就是建立一个机制,支持我们在需要特定代码块的时候能高效地找到(召回率尽量高)结果就是,支持我们在需求变更的时候对所有相关代码块进行修改,(最好能)支持我们开发过程中能复用代码块。而我的函数库,也就是一大堆脚本不支持这些。结果就是,我经常因为不知道一个函数已经存在,而重写一个,浪费时间和精力。
7.1.2. 封装起来便于管理
我可以想办法把计算流程想象成若干实体相互配合完成的活动。由于每个实体都有特定的属性和行为,我们可以把一些变量或者函数放在一起,作为一个实体所管辖的代码块。比如“加法”和“乘2”都是数学运算的具体操作,可以把它们放在一个脚本中。这样,当我需要一个具有特定功能的函数时,联想一下以前开发过的实体里,那些可能有这个函数,就可以很快找到了。
7.1.3. 基于继承来开发和管理
我们搞开发的过程中,经常遇到这样一种情况,即需要开发的实体,和之前开发过的一个实体很像,不过多了一些变量或者函数。下面这个脚本,为斗地主游戏添加了“要不起”动作。
#/斗地主.py
def 要不起(a):
if a > 666:
return True
else:
return False
def add(a, b):
return a + b
def 双倍(a):
return 2 * a
if __name__ == '__main__':
x1 = 66
x2 = 23
y1 = add(x1, x2)
y2 = 双倍(y1)
比如这个实体,“斗地主.py” ,比“math.py”就多了一个“要不起”函数。
具体怎么来做这种代码管理呢?我们可以配置一个叫做“类”的代码块,把所有相关的数据和函数都放到这个代码块中。
有一种开发套路,叫做面向对象,可以比较好地解决我的困难。有些实体之间的关系非常紧密,具有相同的属性和行为,我们可以把这些实体总结概括,也就是抽象为一类实体。
总结一下类的继承相关内容。人们还让类具有一种类似生物繁殖的能力,即“继承”。继承指的是,类B可以以类A为基础模板,沿用类A的一些变量和函数(遗传);改写类A的一些变量和函数,或者实现一些自有的特殊变量和函数(就像变异)。一方面,沿用类A的变量和函数,可以避免代码的重复开发;同时由于内容、功能相关的代码被集中起来管理,修改、增减时可以保证代码的一致性。
7.2. WTF是类和对象?
这句脏话不是对谁的吐槽,主要是描述刚开始学习类和对象时的心情:类和对象有啥区别啊,这部一样吗?!回过头来看当时的学习过程,我认为不需要那么激动,应该更耐心一点。编程语言和编程的思想,在学习的初期,更多的是一种记忆活动,要求我们尽量多地记忆。在脑海里有一个初步记忆后,我们可以开始上手写代码,发现有些东西不理解、忘记了,然后再学习一会儿、再动手写。在这个迭代的过程中,我们对编程语言和编程的思想掌握的会越来精确、越来越深刻。
在使用类管理代码,基于类成员变量管理数据,和使用对象调用方法等操作的过程中,我按照自己的视角和语言,对类和对象进行了理解和解释。类实际上就是一个代码块,里面包含了一组有内在联系的变量和函数。我们可以以类为模板,在内存里缓存一个特别的数据块,我们把类的成员变量和方法都复制到这个数据块里,然后在必要的时候更新成员变量取值或者调用方法(这样类就不受影响了)。总不能就叫“数据块”吧,需要起一个响当当的名字。数据块的称呼比较多,包括对象(object)、实例(instance)等等,其中出镜率较高的是对象。
7.3. 如何定义一个类
如下,是一个类,它描述了斗地主玩家这类事物。Python3支持中文编程,这里为了直观,使用了亲切的中文。
第一行有4个元素:”class”字符串表示当前代码块描述的是一个类;“玩家”字符串是这个类的名称;“()”字符串这里没啥用,当然有时有用;冒号“:”表示开始一个独立的代码块。
玩家类有4个方法,或者说成员函数。其中”__init__”函数是构造函数,即用于构建对象的方法。这个方法比较特殊,继承自一个叫Object的类。Object类是python中所有类的基类,解释器会自动完成这个继承动作。
class 玩家():
def __init__(self):
pass
def 出牌(self):
print("123456789")
def 托管(self):
print("你们太菜了,看我的")
@staticmethod
def 喝茶(self):
print("让我冷静一下。")
7.4. 如何将类实例化并使用
我现在构造一个“玩家”类的实例,就像下面的代码。第一行代码完成了类的实例化,产生了一个叫“李大力”的玩家对象。这行代码的组成部分有4个:(1)等号左边的是接收对象数据内存地址的变量;(2)等号是赋值关键字,将右边的变量取值(python中全部为引用)复制到左边变量中;(3)“玩家”是某一个类的构造方法名称;(4)括号用来接收参数,这里使用的构造函数不需要输入。
李大力=玩家()
李大力.喝茶()
第二行代码表示“李大力”这个玩家执行了喝茶动作。这行代码由4部分组成:(1)“李大力”是对象的名称;(2)英文句号结构成员运算符,用来访问一个类或对象的成员;(3)“喝茶”是这个对象执行的一个动作;(4)括号用来接收参数,这里的函数没有输入参数。
8. 进程、线程与并发
8.1. 进程与线程
进程和线程是计算机操作系统里的概念,二者的出现和发展,与操作系统的出现和发展有密切的联系。详情可以参考(一)线程的发展历史www.jianshu.com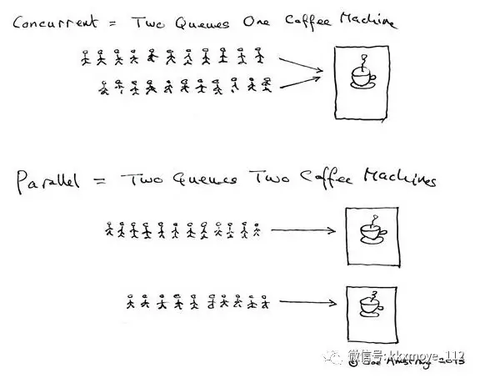
最早的计算机是“一根筋”,CPU只有一个核心,而且同一时间只能执行一个任务,这导致cpu、内存在同一时刻只能做一件事。但是,有些任务不怎么需要cpu工作,比如IO频繁的任务,cpu经常需要等待。看着那么多的计算能力没有用上,当时的人比较难受。
于是,有人想了个办法,把内存划分为若干个区域,每个区域里存放不同任务的变量、代码,然后让所有的任务同时启动,每个任务对应的单元叫做进程。进程们运行的情形可以这样简单理解:当一个进程在IO的时候,另一个进程就赶紧用CPU算一会儿。多核CPU出现以后,人们允许多个进程使用不同的CPU核心进行并行计算。
假如一个大任务里,有N个子任务,共享了一些全局变量,那么全局变量就需要复制N份,存储在内存里。有人就琢磨,这些数据是一样的啊,是不是可只存储一份呢?然后他们提出了线程这么个概念。一个线程是进程中运行的一个程序单元,它可以使用进程中的全局变量进行计算,并与进程内的其他线程共同使用(争抢)一个CPU核心。一些编程语言的线程可以像进程一样,使用多个CPU核心,有的则只能使用一个核心。
8.2. 如何使用python的进程和线程
在python程序运行的时候,Python解释器会在内存中构建一个进程,在进程中有一个虚拟机,虚拟机里存放了程序里所有的变量、函数和至少一个线程。
Python没有内置的进程相关工具,需要使用mutiprocessing(multiprocessing - Process-based parallelism - Python 3.8.1 documentationdocs.python.org
)等库来实现多进程。
Python内置了一个threading库(threading - Thread-based parallelism - Python 3.8.1 documentationdocs.python.org
),可以基于它来使用线程进行计算。
8.3. 为什么是伪线程
我们常说,Python的线程是“伪线程”,这是有原因的。由于一个进程内的线程共享了进程的全局变量,我们需要注意一下数据的一致性。有些情况下,某个线程会修改全局变量的内容。假如每个线程使用不同的核心欢快地跑,就可能发生这样一种情况:线程B使用全局变量x的同时,线程A修改了x的取值并进行计算,那么二者使用了不一致的数据。这可怎么办?
Python选择使用一个全局解释器锁(global interpreter lock, GIL),在一个时间片内,只允许一个线程工作。这样就可以高枕无忧,不怕数据不一致啦。当然,这样的代价就是,多个线程只能使用相当于一个CPU核心的计算能力。因此,大家说python的线程是伪线程。
看起来,GIL限制了python的性能,因此有很多人在想办法让python突破一下。作为小菜鸡,我只能盼望相关的带头大哥们努努力啦。
8.4. Python线程和进程的适用场景
表 8-2 python的进程和线程适用场景
9. 常见第三方库
Python的第三方库非常非常非常多。即使是巅峰期的马三立先生来个“报库名”,也得好一会儿。这里没有全部列出,只是说一些我用的比较多的。
9.1. Numpy:数值计算之星
Numpy(numpypypi.org
)为Python提供了一个高效的数据结构用来存储多维矩阵,还支持矩阵相关的计算,极大的方便了对批量数据的处理。另外,numpy还提供了一大堆统计分析、线性代数等方面的工具。使用numpy,我们可以构建出适用各种场景的、性能较高的数据结构、算法和库,比如pandas。
9.2. Pandas:数据分析之星
有人在numpy的基础上,模仿R语言的数据框,弄了一个python的数据框,并提供了非常丰富的统计分析工具。这就是pandas(Python Data Analysis Librarypandas.pydata.org
)。
AQR Capital Management推出pandas的初衷,是在简化金融行业工作者数据分析工作的同时,提供一定的性能。为此pandas配备了一些sql的方法;还可以连接数据库进行读写操作(Pandas 连接数据库www.jianshu.com
);对excel表格等结构化数据的处理也是非常方便(https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html)。pandaspandas.pydata.org
提供的这些工具,简化了我们在数据预处理和计算中的工作量,非常值得学习和使用。
9.3. Sklearn:机器学习之星
数据科学工作不光需要统计方法,还需要机器学习方法。Sklearn(https://scikit-learn.org/stable/scikit-learn.org
)是python的第三方库中,机器学习方面的代表。我认为,Sklearn的最大特色是,里面提供的所有的模型,都配置的良好的默认超参数,运气不差的新手可以直接训练出有意义的模型。Sklearn的开发团队思想比较开放,借用了numpy、matplotlib等等其他第三方库,性能、功能都不错。
9.4. Tensorflow与PyTorch:深度学习之星
聊到机器学习,就不得不说机器学习的一枝,神经网络。现在的神经网络,已经成为一个异常发达的模型方法研究和应用领域。比较有代表性的网络结构包括全连接、卷积神经网络、循环神经网络、transformer等等等等,训练方法包括传统的BP、生成对抗、强化学习、远程监督、重构、多任务等等等等。这些东西要是让我们自己实现,好多学生就要无法毕业、好多工程师就要失业了——算法和工程能力要求比较高,手写的工期太长。好在一些团队开源了一些类似机器学习积木的工具,支持我们把前面提到的东西进行各种改动和组合,进而在较短的时间内构造出实用的模型。这些积木的品牌非常多,最具代表性的是Tensorflow(TensorFlowtensorflow.google.cn
)和PyTorch(PyTorchpytorch.org
)
9.5. jpype1:让python搭上java的快车
说一千,道一万,python的性能还是差点意思。我们可以使用混合编程的方式,把业务流程中计算量比较大的部分,用性能较好的语言实现,也就是开发自己的库(可以叫第二方库)。然后用python实现整体逻辑、调用自有库完成计算密集型环节,这样就可以提升整体业务的性能了。
在阿帕比的一个项目中,我们需要一个合适的分词器。一开始用的是开源分词器HanLP,不过分词效果不太适合当时的场景。HanLP为了提供一个全能NLP工具,整了很多功能,而为了让这些功能之间合理配合,软件的结构还是有点复杂,因此要改的话,我心里没底、犯怵。邬老师和兰博说,要不写一个吧。领导发话,咱就得干。
写一个也有困难,主要是我只对python比较熟悉,java、C之类的知识略有耳闻,无法实现一个性能足以支撑业务的分词器。另外,分词里涉及大量数据的操作和预处理,这部分要是也用其他语言实现,那可要耽误工期的。
怎么办呢?混合编程。最后,我们的整体框架是用python写的,除了分词环节,其他全部保留。而分词环节由一个以jar包为核心的第二方库提供,python版的主题只需要掉API即可。这个jar里,就是我们的分词器了。
那么,python如何调用jar包里的东西呢?使用jpype1库(https://pypi.org/project/JPype1/)。python2pypi.org
里有一个库叫jpype,为了区别,python3里叫jpype1。
类似jpype1的库还有很多,支持python调用各种编程语言。
9.6. Pymysql之类的数据库连接工具
Python的天职,是支持数据科学领域从业者的工作,因此对数据库操作的支持是必不可少的。Pymysql(PyMySQLpypi.org
)和pymongo(pymongopypi.org
)是这方面最具代表性的第三方库。我们常见的数据库、中间件都有相应的库,比如redis(redispypi.org
)、kafka(kafka-pythonpypi.org
)、py4neo(py2neopypi.org
)等等。
10. 如何让模型跑起来
生产中,我们的软件系统一般比较复杂,由很多子系统、模块组成。算法模型部分通常独立出来、形成一个子系统,主要由算法工程师负责,原因是:内容偏向数据挖掘,对软硬件环境有特殊要求,算法工程师工程能力相对专业开发较弱等等。最后一个原因主要是说本人,同行们不用在意哈。算法模型如何独立出来又能和其他子系统互动、提供能力呢?可以考虑把算法封装成一个工具包,体用API给其他子系统,也可以提供一个服务、让其他子系统调用。
10.1. 把模型封装成工具包
就像9.5所说的,我们可以把一些算法封装起来,然后对外提供API,这样就可以支持其他人、其他语言使用我们的算法了。这样做的好处是,使用简单、数据传输效率高。
10.2. 用HTTP服务封装模型
当然了,有时候封装工具包、部署到其他子系统里,是部分方便或者说不被允许的:工具包里的算法、参数等是严格保密的;或者说,部署难度很大;有些情况下,我们需要所有的子系统使用同一版本的算法,以获得相同的处理结果;等等。这时候,我们可以以HTTP服务的形式,把算法的能力提供出去。这样,做的好处是,对使用者来说,他们只需要关心输入和输出的结构,而算法的细节、维护、升级等等事宜,都由专人负责。
比如一个简单的问答系统,很多地方需要基于分词算法来提取文本信息(搜索框、后台数据加工、实体标注等等),如果各处使用不同的分词算法工具,或者同一个算法工具的不同版本,就会出现文本切分标准的不一致,导致信息检索召回率的下降。而全局使用一个统一的分词服务,可以较好地解决这个问题。
10.3. 如何构建一个HTTP服务
我们可以基于python内置的库http来构建一个HTTP服务,比如https://github.com/lipengyuer/SimpleHTTPServers/blob/master/src/a_simple_server.pygithub.com
前面这个服务提供了一个同步接口,可以理解为一个单进程的程序。这个服务只能使用一个进程来完成计算,吞吐是有限的。假如说我们的数据量比较大,单进程不够用,怎么办呢?可以用map-reduce的结构把服务升级一下,比如lipengyuer/SimpleHTTPServersgithub.com
在之前遇到的一个场景中,我们需要处理的数据量确实有点多,一台机器处理不过来了。我们的leader息哥选择写一个分布式系统,基于multiprocessing库提供的可节点通信的队列,支持master节点带领若干slave节点,对外提供HTTP服务。可以参考https://github.com/lipengyuer/SimpleHTTPServers/tree/master/src/really_distributedgithub.com
11. Python的优势、势与适用场景
简单来说,python的优势是写起来方便,劣势是性能不足。
11.1. 优势
Python把大量编程和数据结构的细节简化或者隐藏了起来,程序员开发的时候主要精力可集中在业务内容上。
另外,python的社区非常发达、越来越发达,积累了大量入门和进阶教程,拥有(最)丰富的第三方库。不论是学习还是使用,我们都可以从互联网中获得到支持,从本文的外链数量就可以看出来。
11.2. 劣势
学习《马哲》的时候,老师跟咱们说,要辩证地看待事物。在搞学术和工程的时候,也要讲究辩证,不能只说一个东西的好处,还得看看它有没有啥不好的地方。Python有很多不足,首先是性能较低,其次是维护有些麻烦。
11.2.1. python为什么慢
众所周知,python是出镜率较高的编程语言中,性能最差的之一。在编程水平差距不大的情况下,人们用java等语言写的算法,那就是比python快。
“一行一解释”太慢。Python是非常典型的解释型语言,解释器会遍会一行一行遍历我们的代码,每遍历到一句就当场解释为机器码然后运行;而C/C++之类的编译型语言,是先把代码转换为机器码,然后直接跑机器码。
全局解释器锁的使用,是python线程无法利用多核CPU。人家都用多核来提升自己的并行化程度,进而提升速度,人进我退就显得python比较慢了。
再配合上python的动态类型特点,解释工作还真挺繁重的。但是,等你判断出类型,判断出对象的数据结构和内存地址范围,人家C已经开始执行下一句了。
当然了,使用混合编程的套路,可以很大程度上缓解python的性能弱点、解决某些对性能有要求的场景。由于语言之间相互调用存在数据传输的缓解,终归存在性能的衰减,假如是高性能场景,就别墨迹了,换语言吧。
11.2.2. 写更好的注释、做更好的程序员
Python给了程序员一个非常自由的空间,可以轻松地写出各种各样风格的代码。当然这个自由也是有代价的:我们回过头再看自己的代码时,可能会感觉有点难懂。由于没有强制规定类型生命的那个操作,我们传递变量类型是啥,还得根据上下文取推测,这样的工作质量就大了。
我的办法是,多写一点注释,尽量在注释里记录变量的类型等信息。老板们最喜欢这样了,开发者走了,新人能更快接手。
我们的职业生涯还是比较长的,即使是以前写的垃圾,也有可能在以后的工作中排上用场。因此,写个注释便于以后维护和使用,不算亏。
11.3. Python的用武之地
综上所述,python非常适合在业务的初级阶段,被用来开发模型或算法demo。Python也非常适合用来开发和验证一些新的模型和算法,如果新东西有效而且需要提升性能,我们就可以升级模型和算法,或者考虑使用高性能的语言替换模块、甚至重写。
12. 结语
总的来说,python是一种特色鲜明的计算机编程语言,非常适合用来做数据处理和计算方面的工作,以及一些算法、模型的验证工作。
如果要我从不计其数的编程语言中挑一个,教给闺女,我会选python。python为程序员做了很多细节工作,降低了程序员在语言本身上消耗的脑力,允许了他们在业务内容上投入更多的精力。对计算机编程的初学者来说,这种语言带来的挫败感会少一些,因此特别适合用来做编程启蒙。
当然,以后我还要教她C语言、Java这些语言,在与python的对比中学到更多的东西。
注意:本文为李鹏宇(知乎个人主页https://www.zhihu.com/people/py-li-34)原创作品,受到著作权相关法规的保护。如需引用、转载,请注明来源信息:(1)作者名,即“李鹏宇”;(2)原始网页链接,即当前页面地址。如有疑问,可发邮件至我的邮箱:lipengyuer@126.com。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









