






作者| 猪哥
来源 | 裸睡的猪
第一章主要讲解爬虫相关的知识如:http、网页、爬虫法律等,让大家对爬虫有了一个比较完善的了解和一些题外的知识点。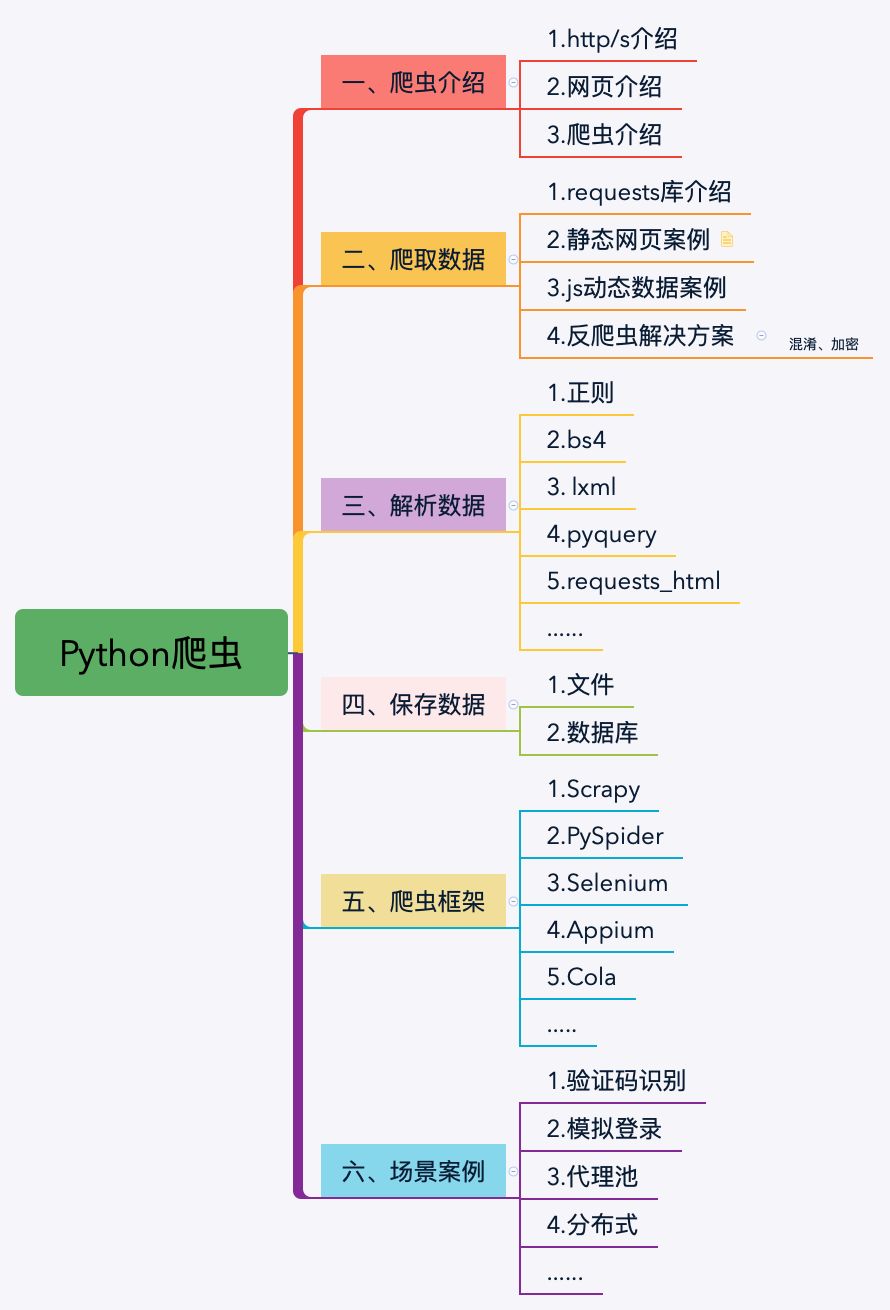
今天这篇文章将是我们第二章的第一篇,我们从今天开始就正式进入实战阶段,后面将会有更多的实际案例。
爬虫系列文章的第一篇,猪哥便为大家讲解了HTTP原理,很多人好奇:好好的讲爬虫和HTTP有什么关系?其实我们常说的爬虫(也叫网络爬虫)就是使用一些网络协议发起的网络请求,而目前使用最多的网络协议便是HTTP/S网络协议簇。
一、Python有哪些网络库
在真实浏览网页我们是通过鼠标点击网页然后由浏览器帮我们发起网络请求,那在Python中我们又如何发起网络请求的呢?答案当然是库,具体哪些库?猪哥给大家列一下:
Python2: httplib、httplib2、urllib、urllib2、urllib3、requests
Python3: httplib2、urllib、urllib3、requests
Python网络请求库有点多,而且还看见网上还都有用过的,那他们之间有何关系?又该如何选择?
httplib/2:
这是一个Python内置http库,但是它是偏于底层的库,一般不直接用。
而httplib2是一个基于httplib的第三方库,比httplib实现更完整,支持缓存、压缩等功能。
一般这两个库都用不到,如果需要自己 封装网络请求可能会需要用到。
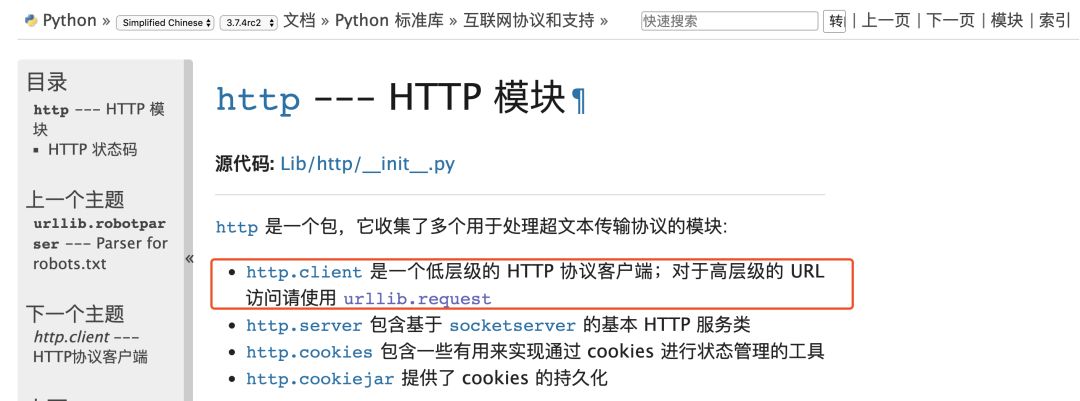
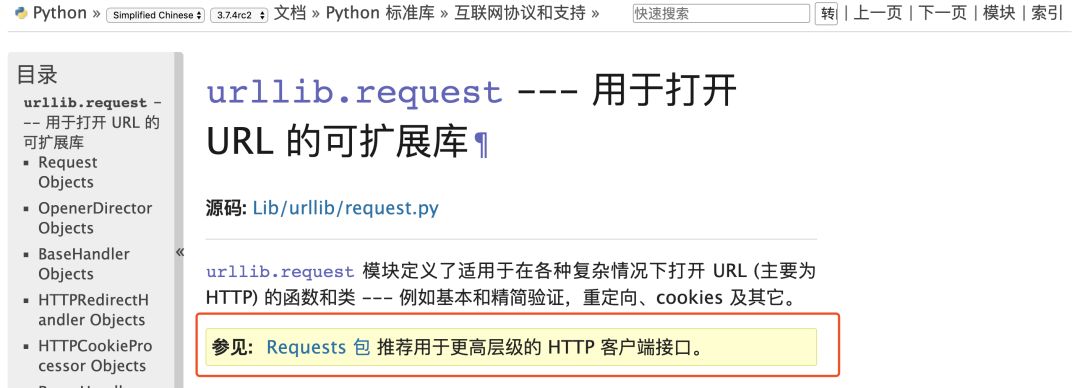
urllib/urllib2/urllib3:
urlliib是一个基于httplib的上层库,而urllib2和urllib3都是第三方库,urllib2相对于urllib增加一些高级功能,如:
HTTP身份验证或Cookie等,在Python3中将urllib2合并到了urllib中。
urllib3提供线程安全连接池和文件post等支持,与urllib及urllib2的关系不大。
 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









