






本文是《利用Python进行数据分析》的第七章<数据规整化:清理、转化、合并、重塑>的学习笔记。
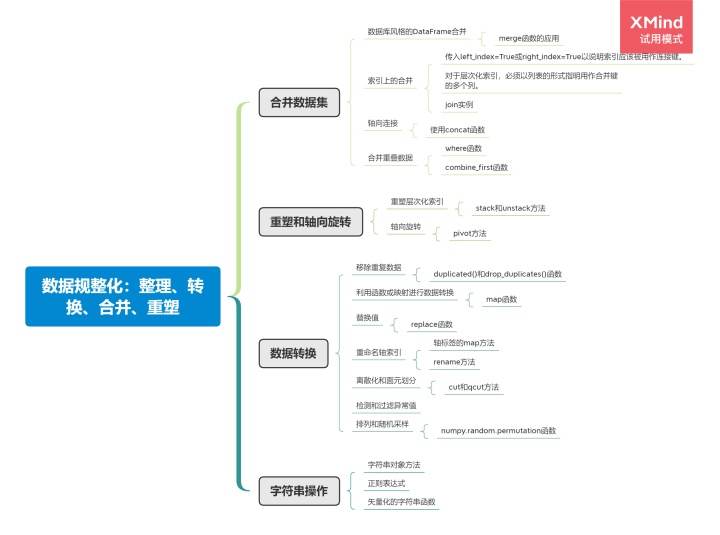
一、合并数据集
1.1数据库风格的DataFrame合并
数据集的合并(merge)或连接(join)运算是通过一个或多个键将行链接起来的。这些运算是关系型数据库的核心,与SQL语言类似。pandas的merge函数是对数据应用这些算法的主要切入点。
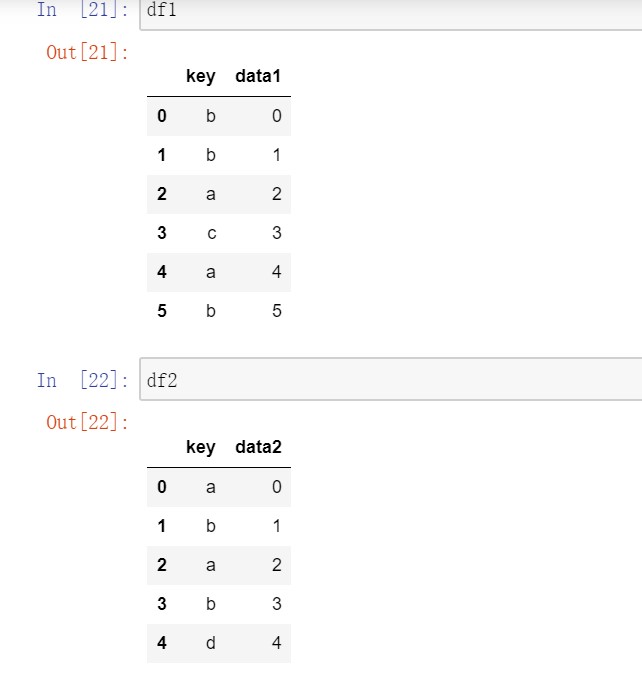
先以一个简单的案例开始,如果没有指明要用哪个列进行连接,merge就会将重叠列的列名当做键,最好使用on显式指定一下。
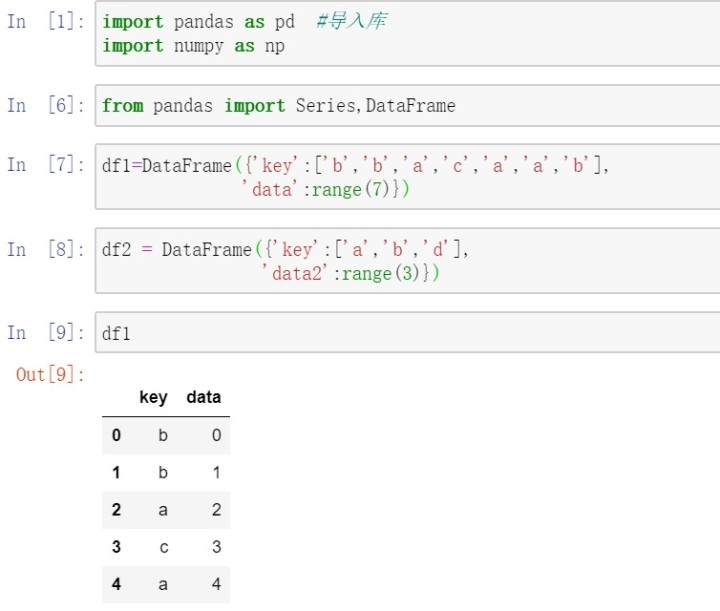
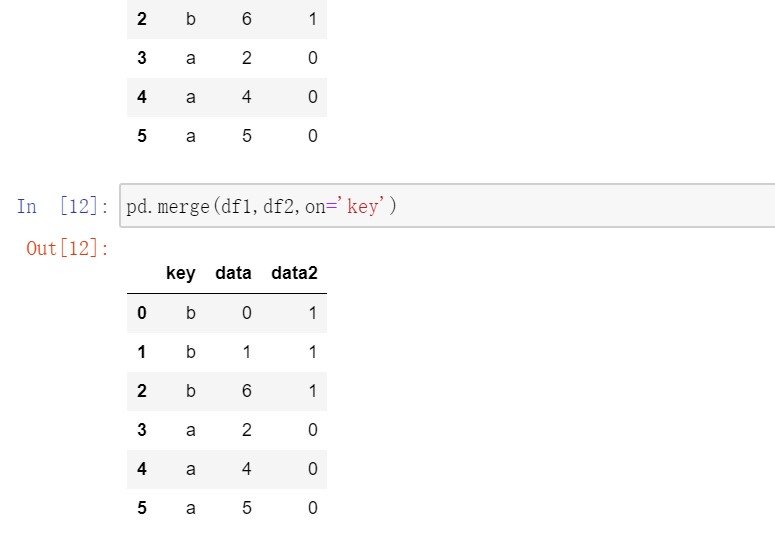
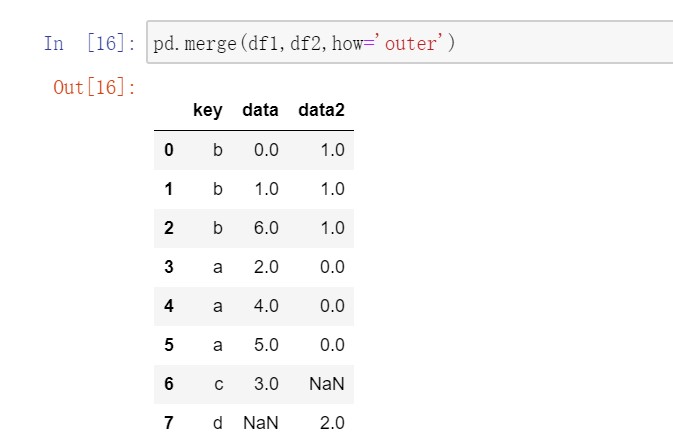
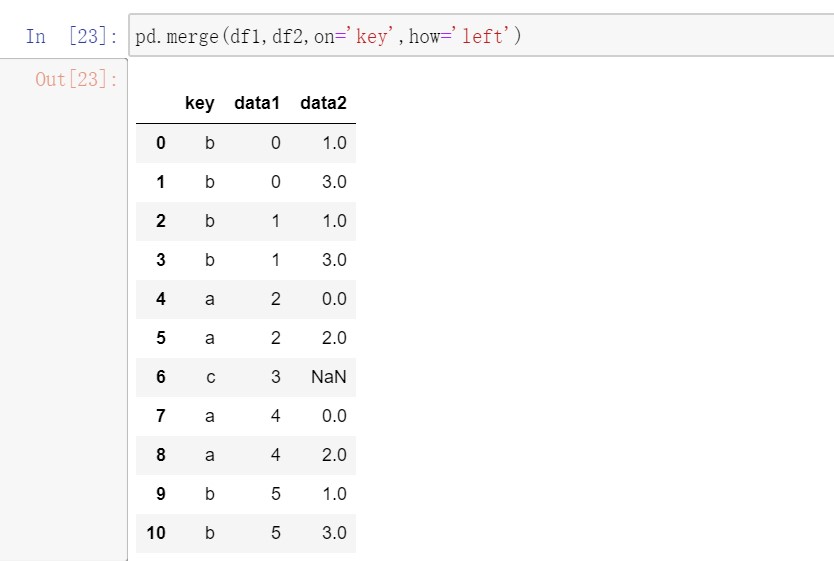
默认merge做的是inner连接,结果是交集。此外还有left、right、outer连接,外连接求取的是键的并集。多对多连接产生的是行的笛卡尔积。
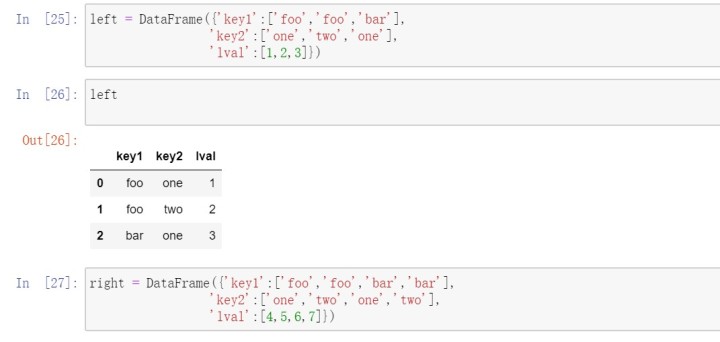
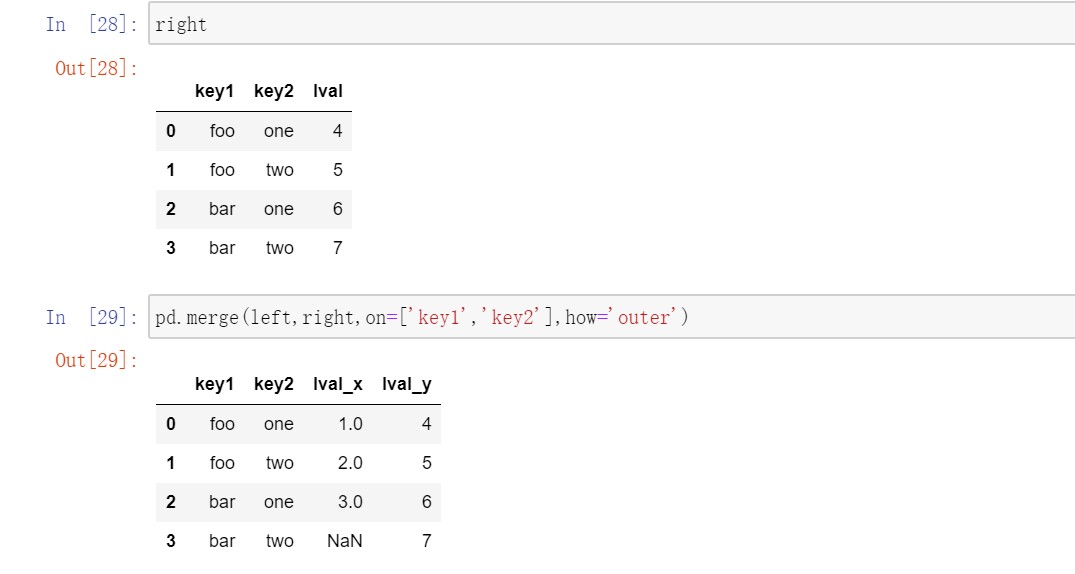
要根据多个键进行合并,传入一个由列名组成的列表即可:
1.2索引上的合并
有时,DataFrame中的连接键位于其索引中。在这种情况下,你可以传入left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接键。
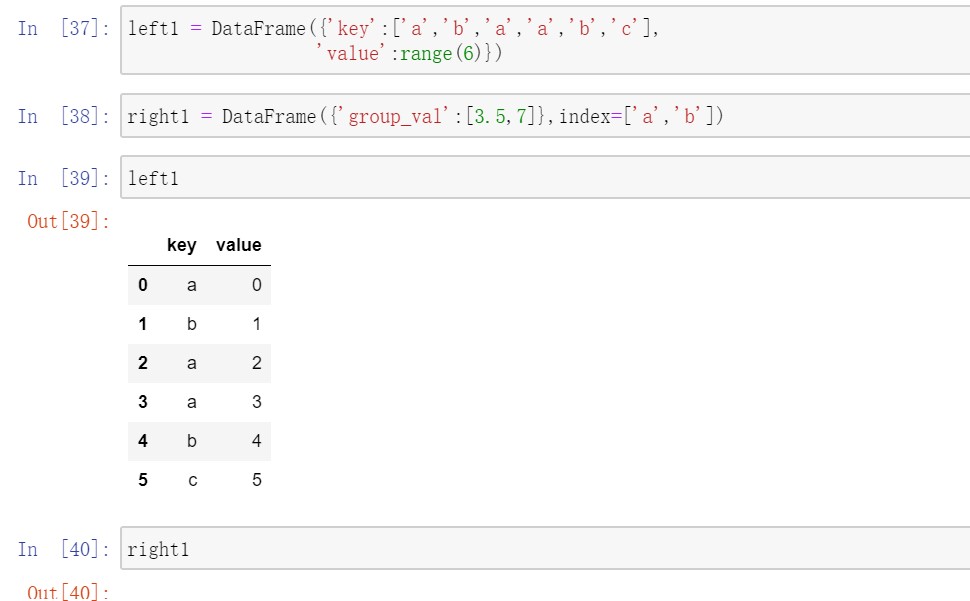
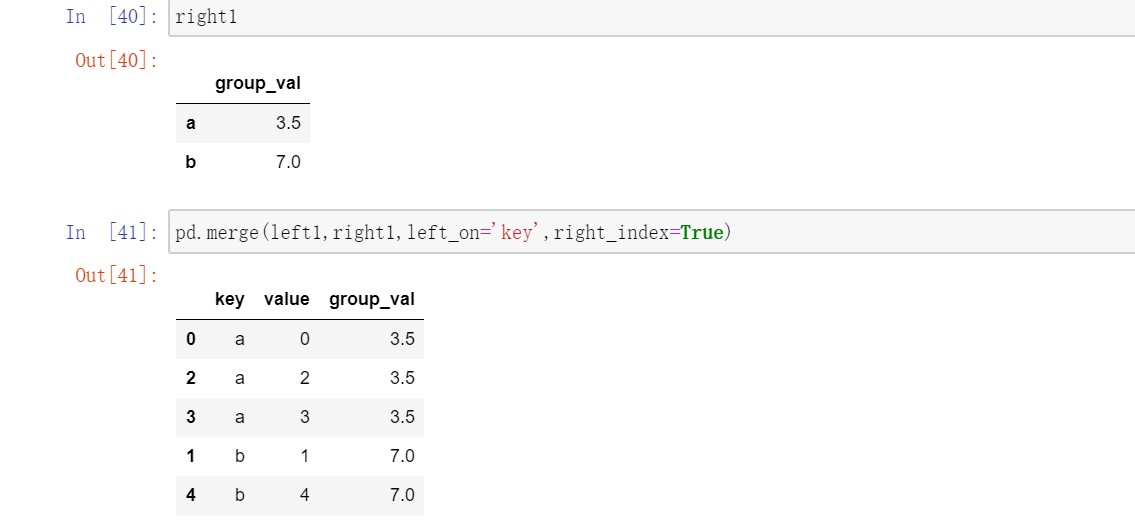
对于层次化索引,必须以列表的形式指明用作合并键的多个列。
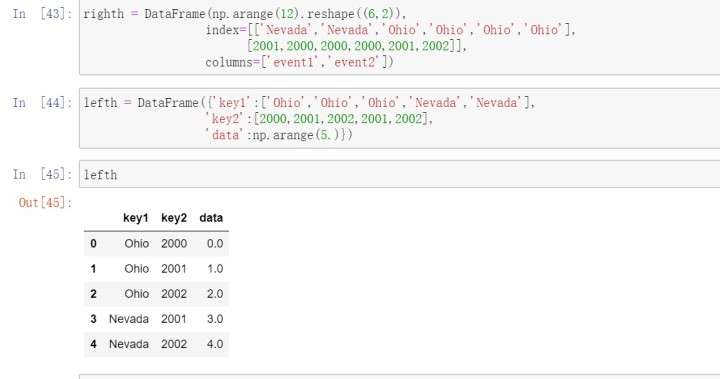
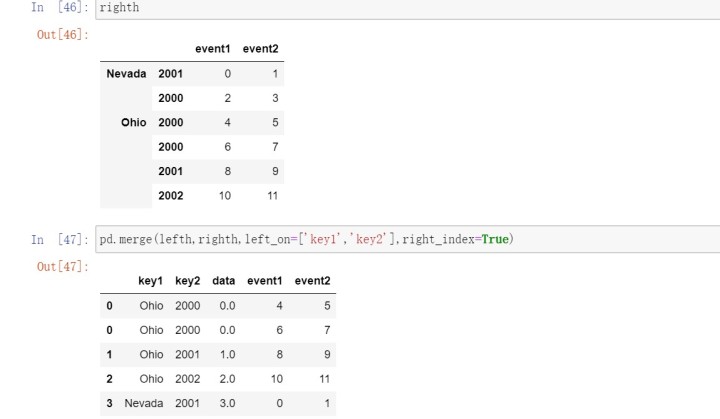
DataFrame还有一个join实例方法,它能更为方便地实现按索引合并。
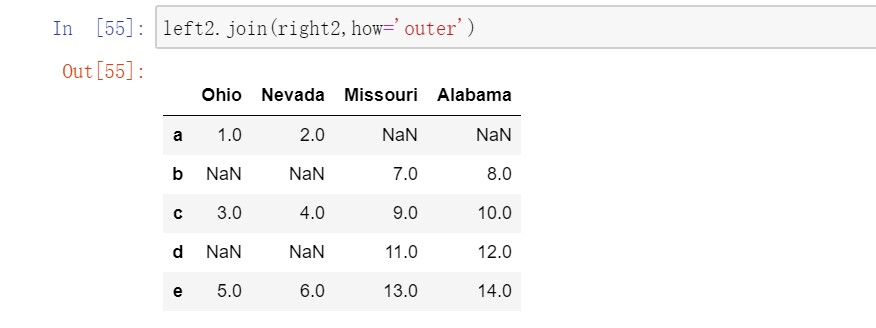
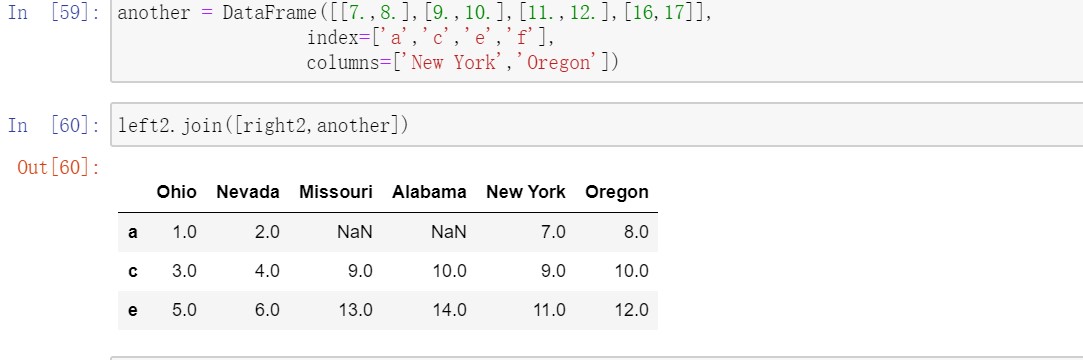
对于简单的索引合并,还可以向join传入一组DataFrame
1.3轴向合并
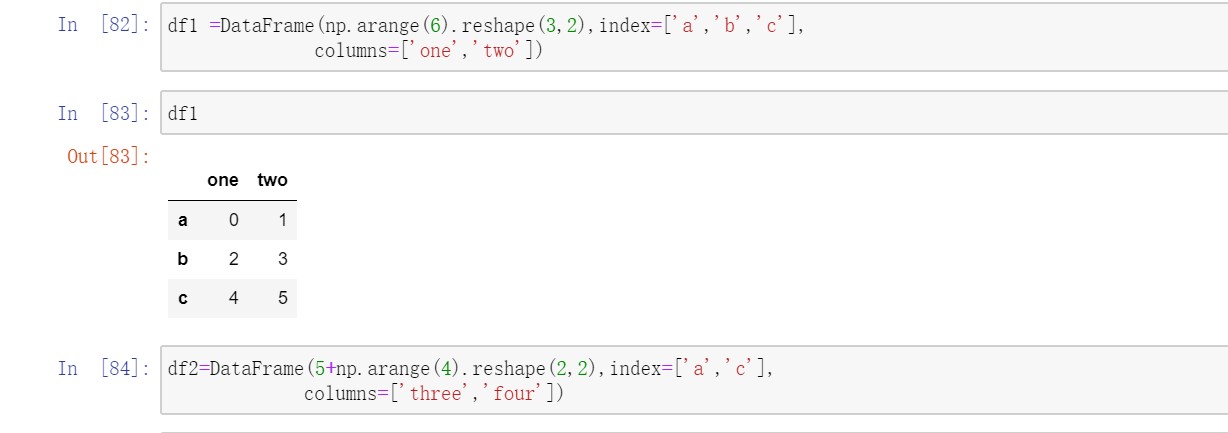
另一种数据合并运算也被称为连接(concatenation)、绑定(binding)或堆叠(stacking)。NumPy有一个用于合并原始NumPy数组的concatenation函数:

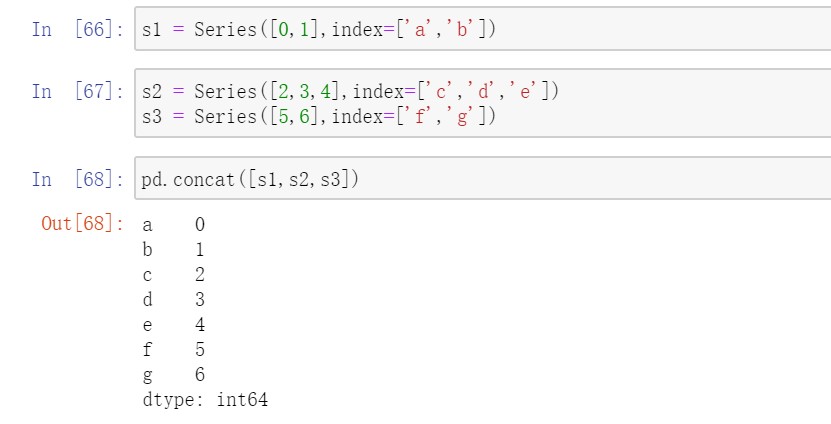
假设有三个没有重叠索引的Series,对这些对象调用concat可以将值和索引粘合在一起。
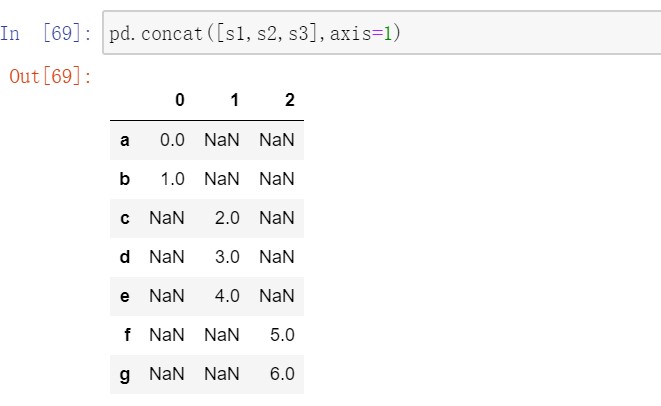
默认是在axis=0上工作的,也可以在axis=1上工作。
同样的逻辑对于DataFrame对象也是一样的
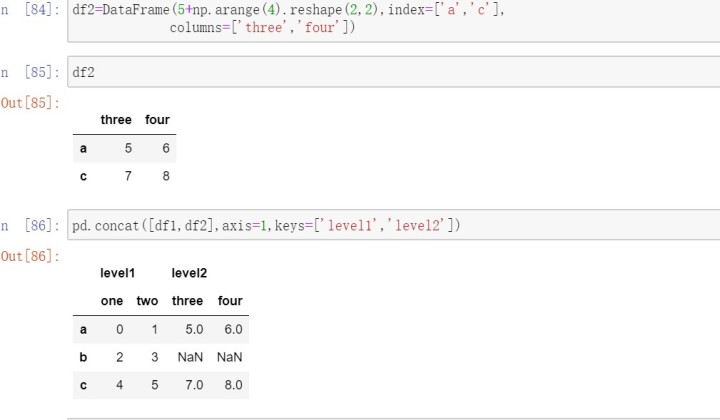
1.4合并重叠数据
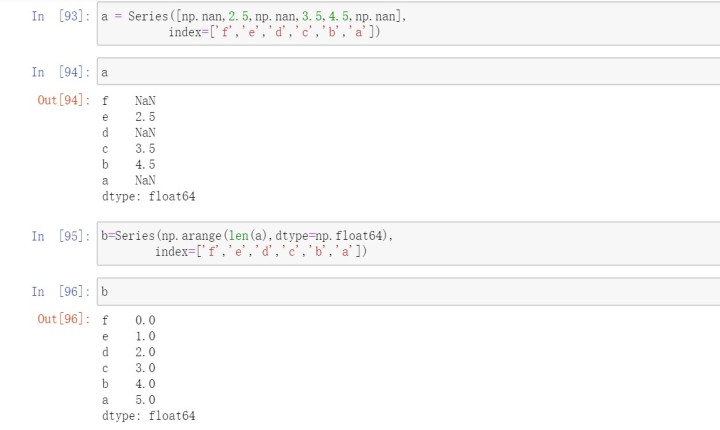
使用Numpy的where函数,它用于表达一种矢量化的if-else
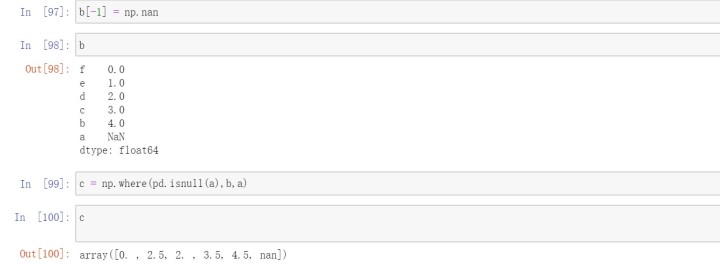
Series有一个combine_first方法,实现的也是一样的功能,而且会进行数据对齐。
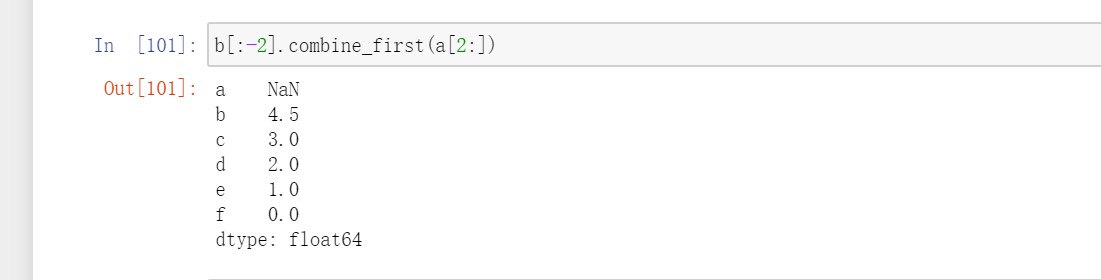
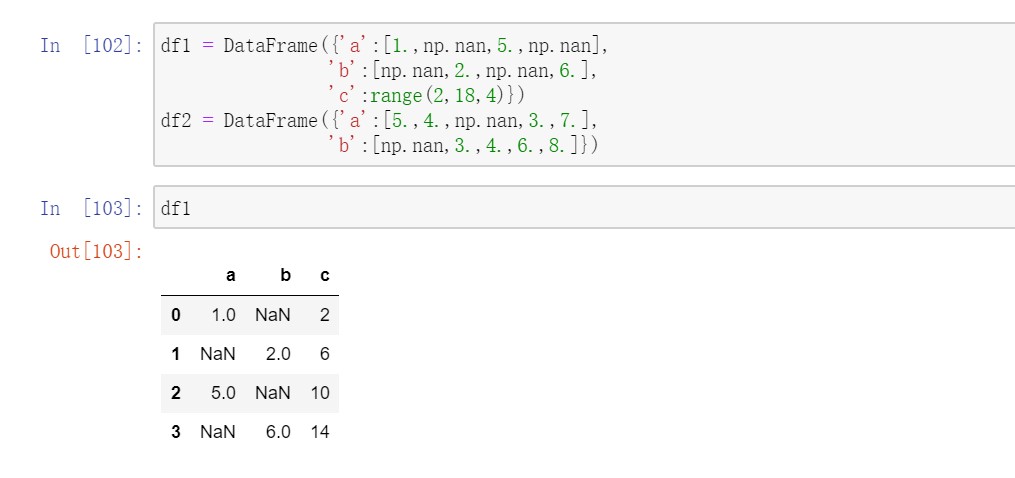
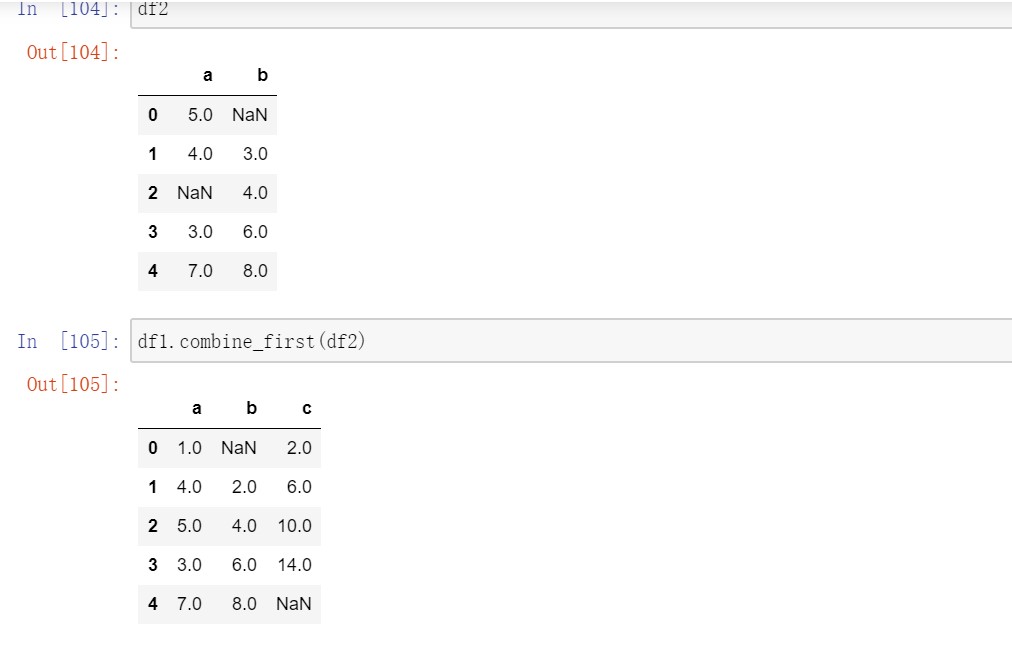
对于DataFrame,combine_first会做同样的事,用参数对象中的数据为调用者对象的缺失数据“打补丁”。
二、重塑和轴向旋转
有许多用于重新排列表格型数据的基础运算。这些函数也被称作重塑(reshape)或轴向旋转(pivot)运算。
2.1重塑层次化索引
使用stack将数据的列“旋转”为行,unstack是它的逆运算,将数据的行旋转为列。
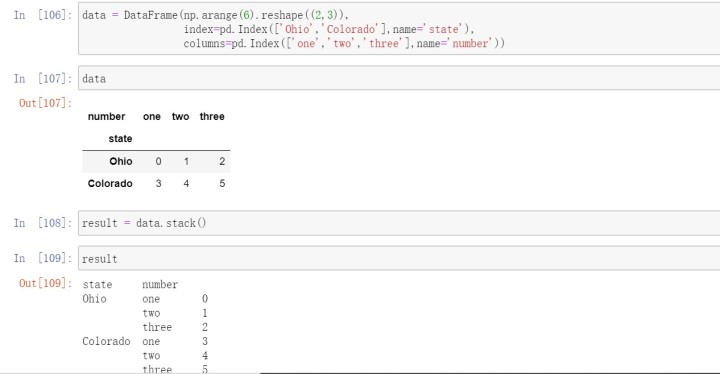
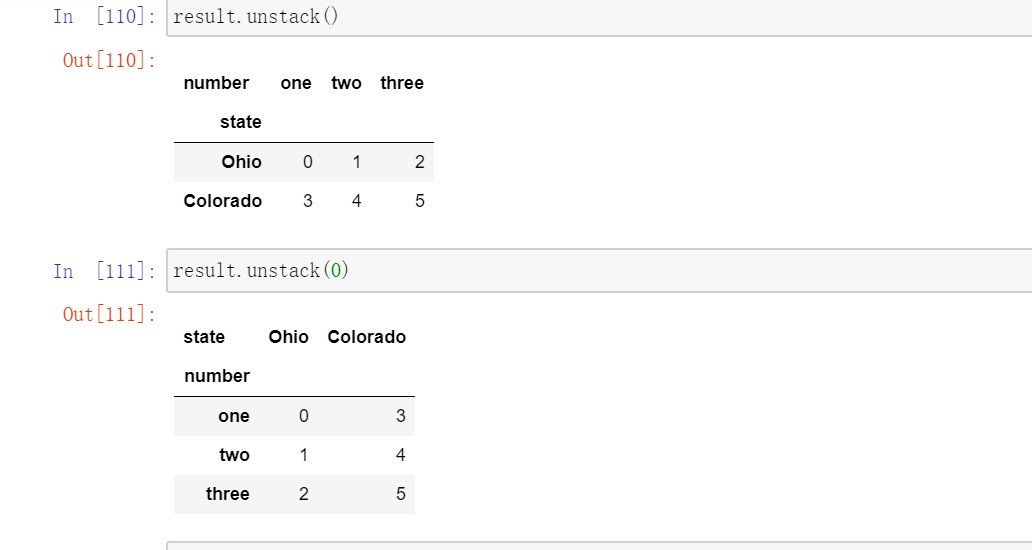
2.2将“长格式”旋转为“宽格式”
DataFrame的pivot方法可以实现这个转换
三、数据转换
上面介绍的都是数据的重排,另一重要操作是过滤、清理及其他转换工作。
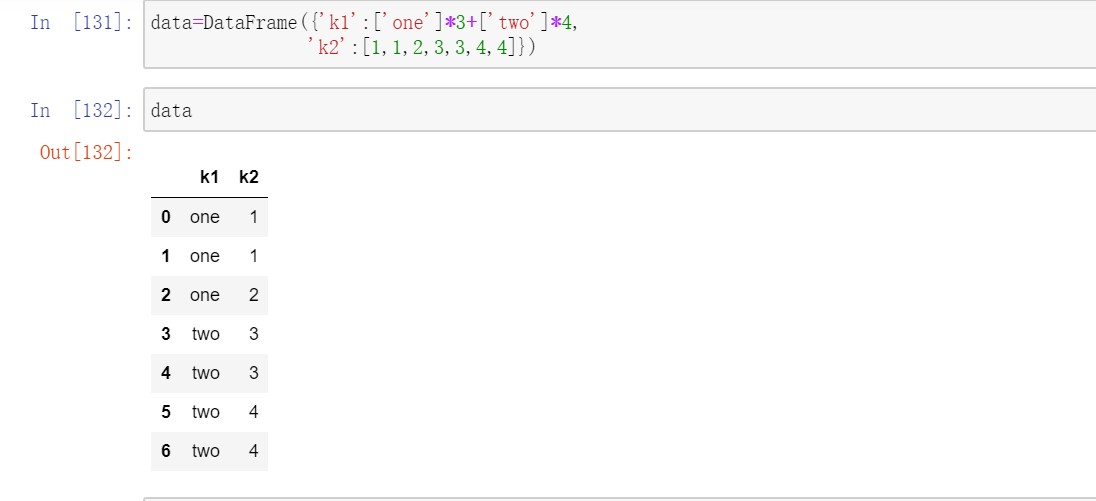
3.1移除重复数据
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行。使用drop_duplicates()方法去除重复值。
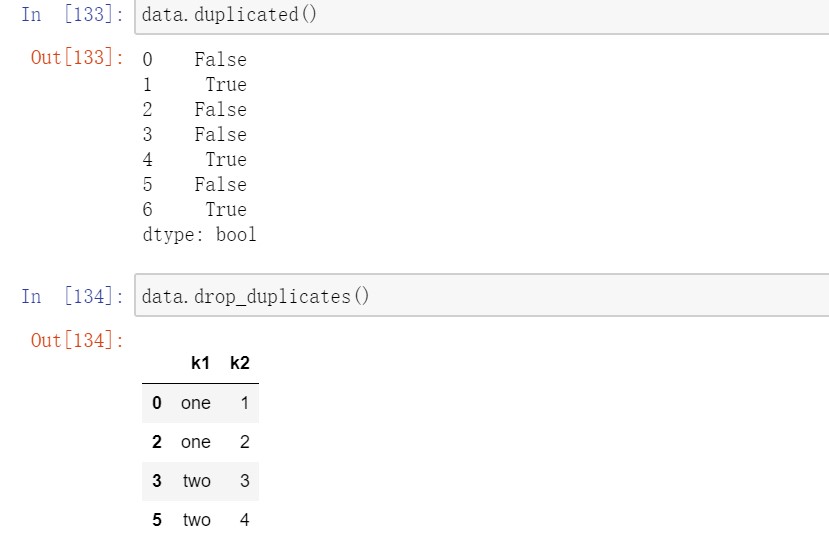
上述方法默认会判断全部列,也可以指定部分列进行重复项判断。
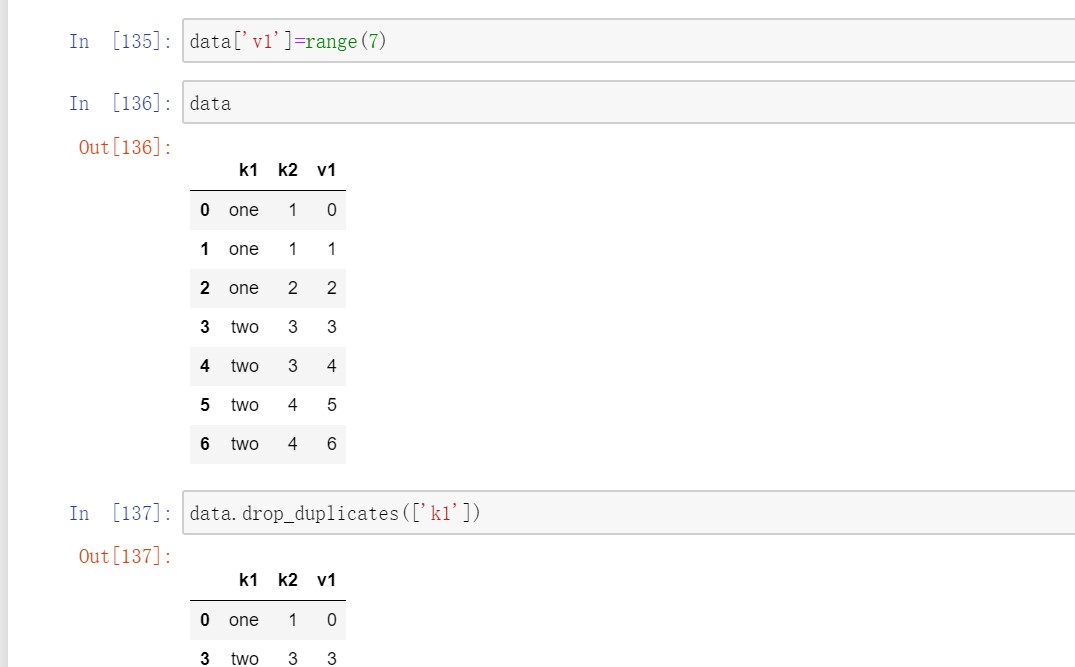
3.2利用函数或映射进行数据转换
Series的map方法可以接受一个函数或含有映射关系的字典型对象。
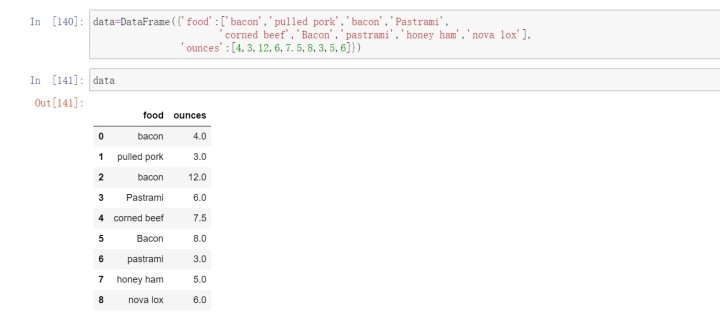
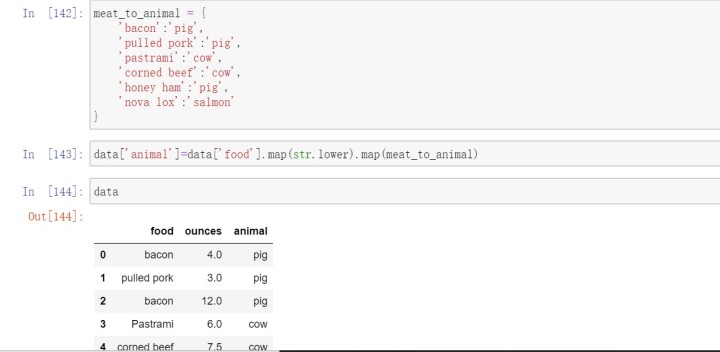
我们也可以传入一个能够完成全部这些工作的函数
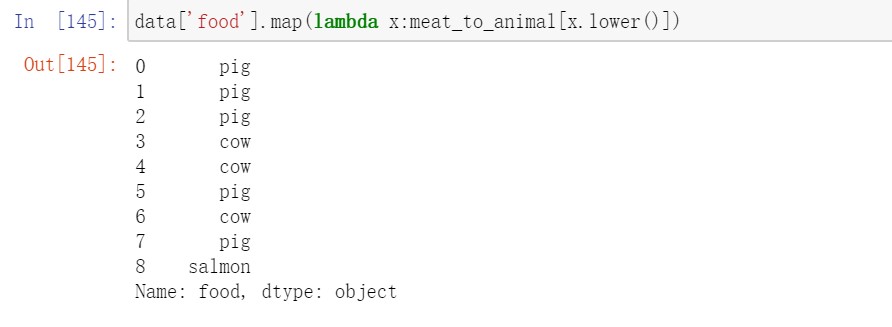
3.3替换值
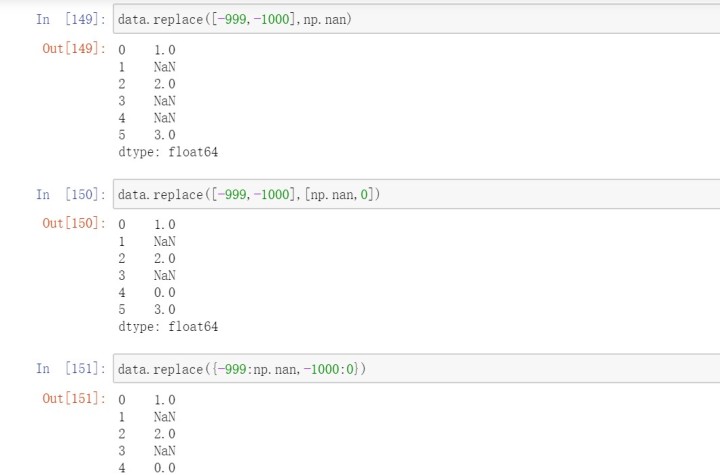
使用replace方法进行替换
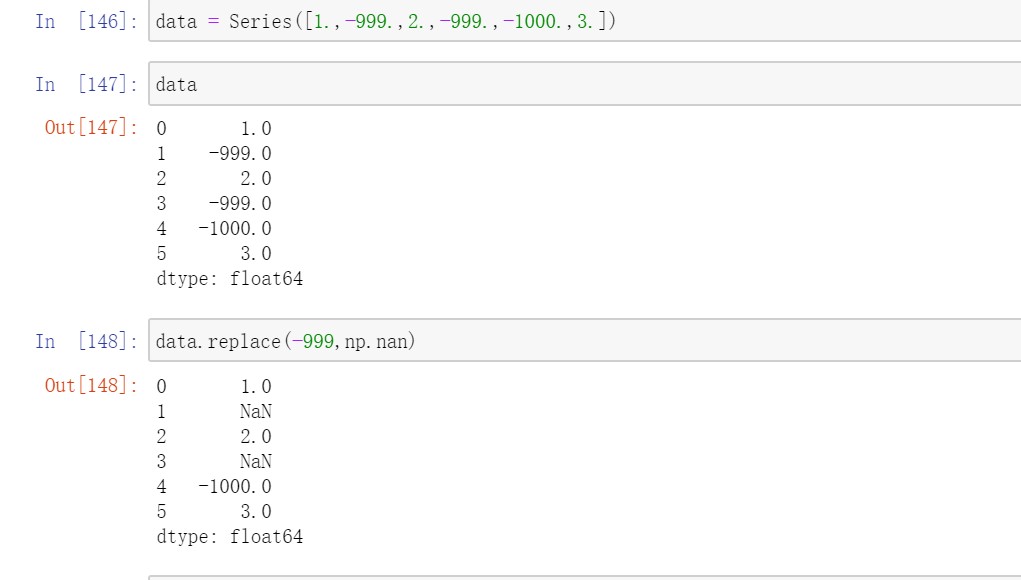
如果希望一次性替换多个值,可以传入一个由待替换值组成的列表以及一个替换值;如果希望对不同的值进行不同的替换,则传入一个由替换关系组成的列表;传入的参数也可以是字典。
3.4重命名轴索引
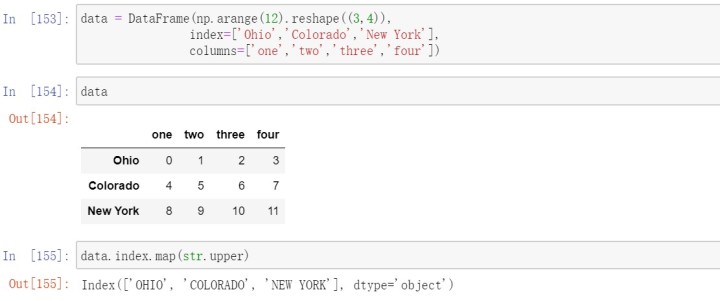
跟Series中的值一样,轴标签也可以通过函数或映射进行转换,从而得到一个新对象。如使用轴标签的map方法
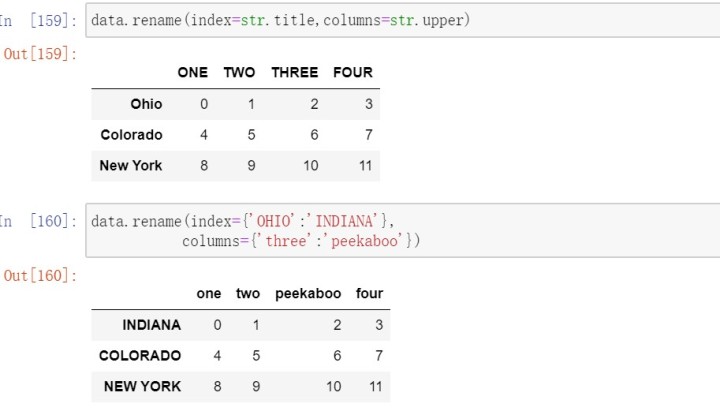
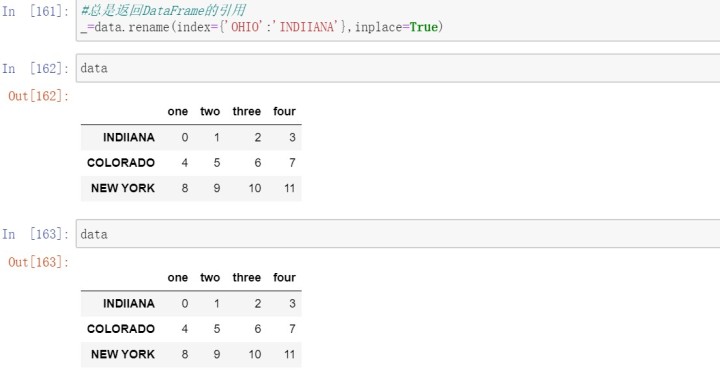
还可以使用rename方法
3.5离散化和面元划分
为了便于分析,连续数据常常被离散化或拆分为“面元”(bin),可以使用cat函数。

cut有codes、categories、value_counts三个属性

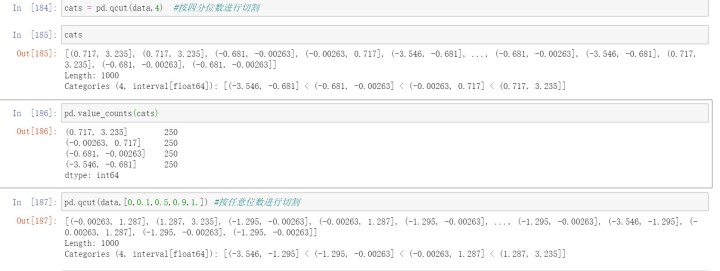
qcut可以根据样本分位数对数据进行面元划分
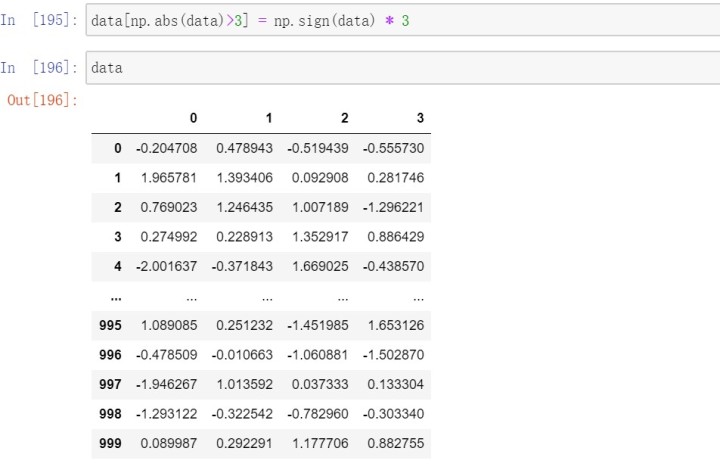
3.6检测和过滤异常值
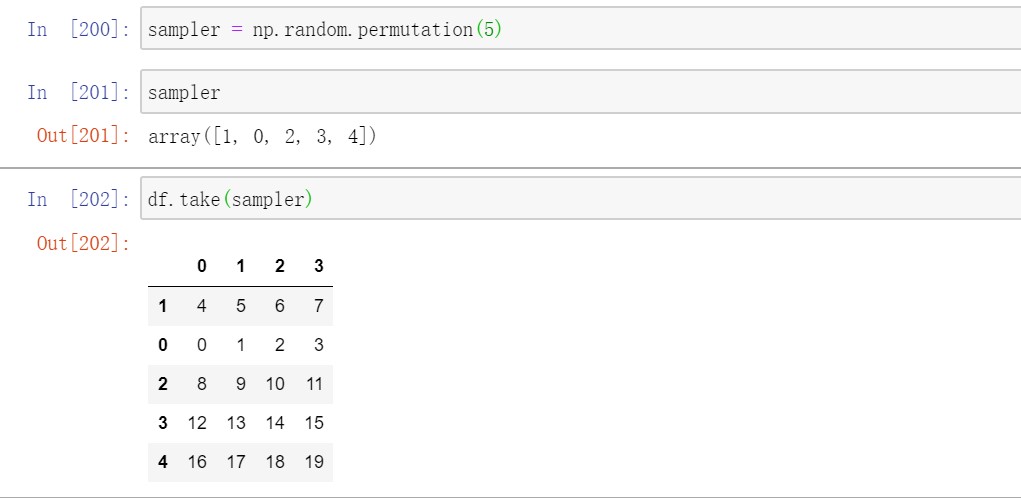
3.7排列和随机采样
使用numpy.random.permutation函数可以对列的顺序重排















 8840
8840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









