





将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。常用的聚类算法包括原型聚类、密度聚类和层次聚类三大类。
其中密度聚类算法(density-based clustering)假设聚类结构能通过样本分布的紧密程度确定。通常情况下,密度聚类算法从样本密度角度考察样本之间的可连接性,并基于可连接性不断扩展聚类簇以获得最终的聚类效果。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种典型的密度聚类算法。其在交通领域的数据处理中有着广泛的应用和独特的优势。下面科研Lab将从算法优势、概念原理、案例讲解(附代码)三部分讲解DBSCAN。

1. 算法优势
- 作为密度聚类的经典算法,DBSCAN可以处理不同大小、形状的数据集,同时聚类结果产生的簇(性质相似的样本数据组成的最大非空子集)形状、大小、数量是任意的。以出行行为分析为例,研究之前,我们对出行链或站点的聚类结果是未知的,某种意义上,其聚类后的形状、大小、数量也是任意的。
- DBSCAN以高密度确定簇,同时自动将不属于任何簇的样本数据作为噪音舍弃,避免了噪音数据为结果产生的影响。仍以出行行为分析为例,由于罕见原因(重大活动,恶劣天气等等)产生的出行链数据,其发生概率很小,在一般性的研究中使用DBSCAN去除,既不影响研究目的,也可以避免“特殊”出行链对结果产生的干扰。
2. 概念原理
DBSCAN算法有两个全局参数:ε 和 MinPts ,在其基础上定义邻域,从而刻画样本分布的紧密程度。给定样本集
- ε-邻域:对
,其ε-邻域包含样本集D中与
的距离不大于
的样本,即:
这里的距离指的是欧氏距离,感兴趣的小伙伴可以自行了解闵可夫斯基距离。![]()
- 核心点(核心元素):若
的ε-邻域至少包含MinPts个样本,即
,即
核心点;是一个
- 边界点:若
的ε-邻域样本数量少于MinPts,且
位于核心点的ε-邻域内,则称
为边界点;
- 噪音点:若
既不是核心点,也不是边界点,则称
为噪音点;
- 密度直达:若
位于的ε-邻域中,且
是核心对象,则称
是由
密度直达; - 密度可达:对
与
,若存在样本序列
,其中
,
由密
度直达,则称
由
密度可达; - 密度相连:对
与
,若存在
使得
与
均由
密度可达,则称
与
密度相连。
更直观的可以看下图,MinPts=3,所有圆等大且半径为ε。
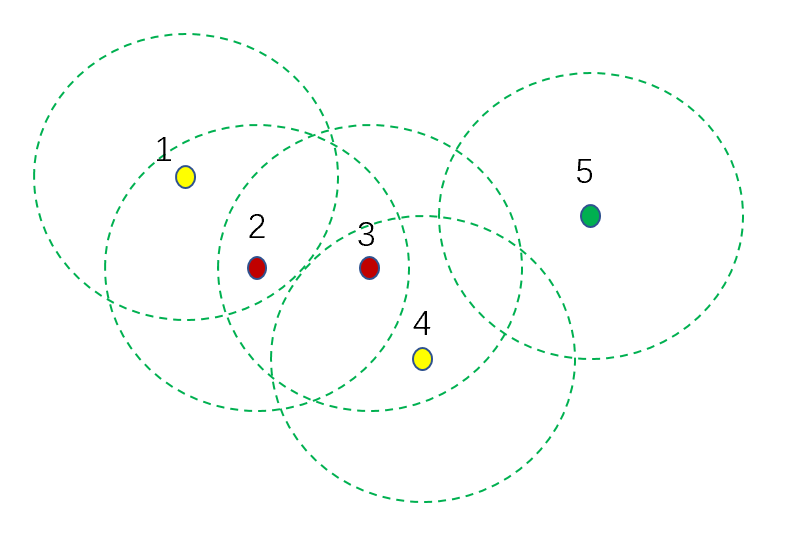
红色:核心点
黄色:边界点
绿色:噪音点
1可由2密度直达、4可由3密度直达、2和3互相密度直达;
1可由3密度可达,4可由2密度可达;
1与4密度相连。
基于以上概念,DBSCAN将“簇”定义为:由密度可达关系导出的最大密度相连的样本集合。给定邻域参数(ε和MinPts),簇是满足连接性和最大性的非空样本子集:
连接性:若
最大性:若
3. 案例讲解
- ·数据集构造
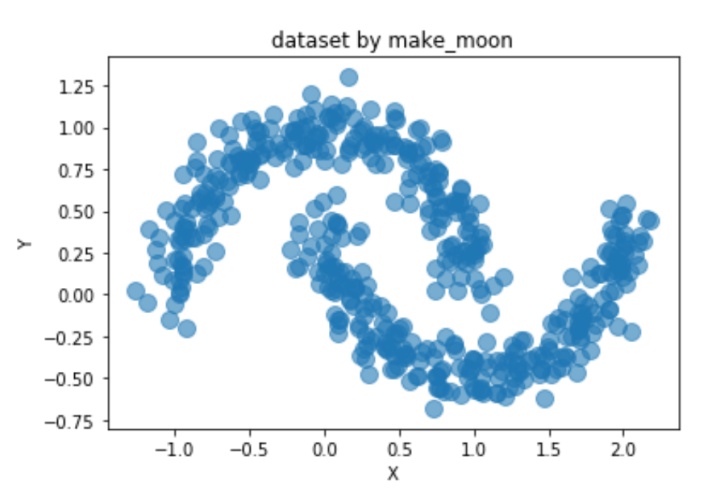
样本数据集由sklearn包构造
1) 导入包:
import 2) 生成数据集:
%matplotlib inline
#初始化样本数据集
#生成样本容量为500的样本集合,设置噪音比。
dataset,_ = datasets.make_moons(500,noise = 0.1,random_state=1)
df = pd.DataFrame(dataset,columns = ['X','Y'])
#绘图,设置透明度为0.6
df.plot.scatter('X','Y', s=100,alpha=0.6, title='dataset by make_moon')注:数据无量纲
样本集可视化得到:
- 算法思路
算法先根据给定的邻域参数(ε和MinPts)找出所有的核心对象;在以任意核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有的核心对象被访问过。
- ·具体实现
1) 初始化邻域参数:
r= 0.2
minpts = 202) 在建立邻域字典的基础上,搜索所有核心元素:
#补充样本序号
dataset=dataset.tolist()
i=0
while i<len(dataset):
dataset[i]=[i+1]+dataset[i]
i+=1
#print(dataset)
#建立字典 点(键) 邻域集合(值) 为方便,点以序号代替
#初始化字典
N_dict = {}
for i in dataset:
n_tem = [] #临时存储邻域
for j in dataset:
dist=((i[1]-j[1])**2+(i[2]-j[2])**2)**0.5 #距离使用欧式距离
if dist<=r:
n_tem.append(j[0])
N_dict[i[0]]=n_tem
#print(N_dict)
#初始化核心元素集合
U = []
i = 1
while i <= 500:
if len(N_dict[i]) >= minpts:
U.append(i)
i +=1
print("the core points are ",U)3) 聚类:以任意核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有核心对象被访问过。
#初始化 簇的集合
C = []
#初始化 未访问的样本序号集合
DS =[i for i in range(1,501)]
#建立循环,直到core points全部被访问过 所有簇才被寻找到
while U != []:
DS_old = DS[:] #标记当前未访问过的样本集合
print("当前未访问过的样本集合:",DS_old)
Q1 = random.sample(U,1) #不失一般性,随机选取核心元素, #初始化 本次研究的points集
print("随机选取的核心元素:",Q1[0])
DS.remove(Q1[0]) #去除已访问过的核心元素
Q2 = [] #初始化 本次研究的簇
while Q1 != []:
print("本次研究的points集:",Q1)
num = Q1.pop(0) #取出不放回
print("取出的元素:",num)
if num in U:
for i in N_dict[num]:
if i != num and i in DS and i not in Q1:
Q1.append(i)
DS.remove(i)
#取DS_old内,但不在DS内的元素,作为本次的簇
print("DS_old:",DS_old)
print("DS",DS)
for i in DS_old:
if i not in DS:
Q2.append(i)
print("簇:",Q2)
C.append(Q2)
for i in Q2:
if i in U:
U.remove(i)
#初始化噪音集合
noise = []
for i in DS:
if i not in C[0] and i not in C[1]:
noise.append(i)
print("最终簇为:",C)
print("噪音为",noise)4) 可视化。
通过可视化,得到下图
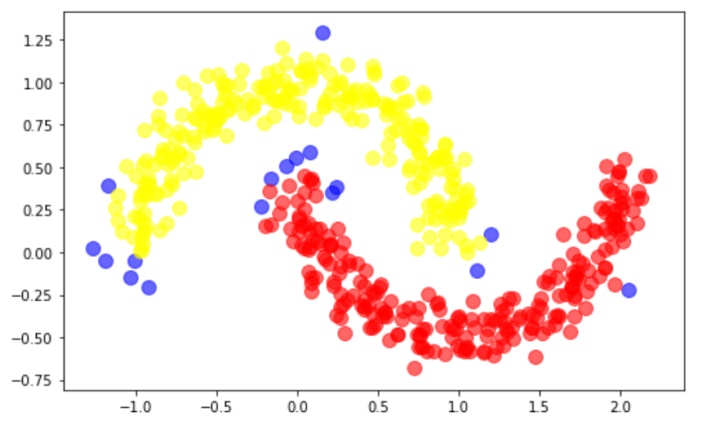
其中黄色代表簇1,红色代表簇2,蓝色代表噪音点。
本期讲解就到这里啦,下期推送讲讲解使用sklearn库实现DBSCAN算法,同时介绍DBSCAN算法的改进模型,如果你喜欢本篇文章的话,请点赞,转发,关注,您的鼓励与支持是我们创作的最大动力!
欢迎关注【交通科研Lab】公众号,所有文章均在公众号第一时间发布!

参考文献:[1]周志华.机器学习2016[M].北京:清华大学出版社.2016.















 8447
8447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









