






上一期我们学习了MySQL查询语句的相关知识,这一期,我们就来学习一下表的创建、修改以及表的联结等知识吧。
一、MySQL基础---表操作
1.MySQL表数据类型
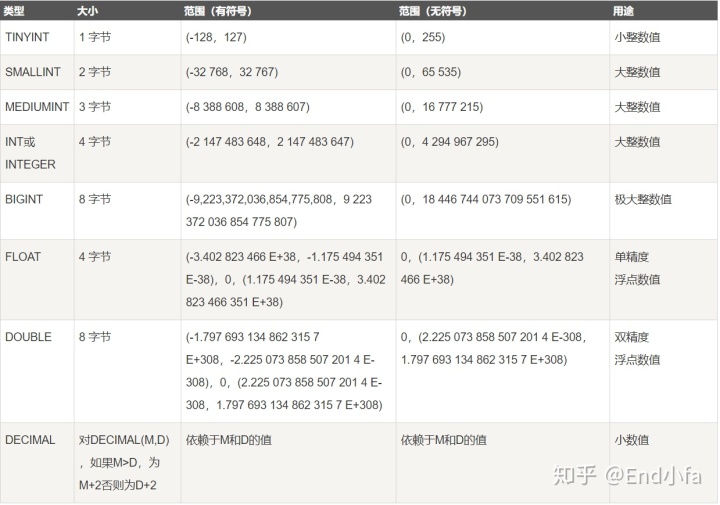
MySQL支持多种数据类型,大致可以分为三类:数值、日期/时间、字符串(字符)类型。
- 数值型有:
- 日期和时间类型有:
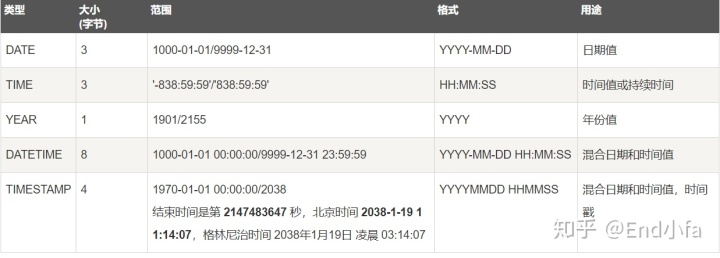
若定义一个字段为timestamp,这个字段里的时间数据会随其他字段修改的时候自动刷新,所以这个数据类型的字段可以存放这条记录最后被修改的时间。
- 字符串类型有:
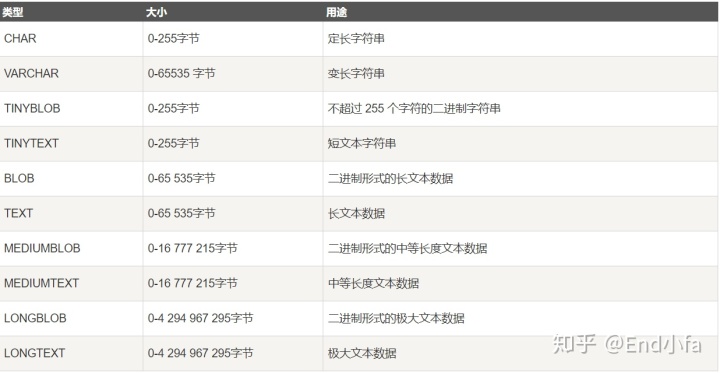
注:
(1)char与varchar比较
- char(n)若存入字符数小于n,则以空格补于其后,查询时再讲空格去掉。所以char类型存储的字符串末尾不能有空格,varchar则不限
- char(n)固定长度,char(5)不管存入几个字符,都将占用5个字符,varchar是存入的实际字符数+1个字节(n<=255)或+2个字节(n>255)
- char类型的字符串检索速度要比varchar类型快
(2)varchar与text比较:
- varchar可指定n,text不能,内部存储text是实际字符数+2个字节
- text类型不能有默认值
- varchar的查询速度快于text
2.用SQL语句创建表
2.1语句解释
CREATE - 要创建的表名称,不区分大小写,不能使用SQL语言中的关键字,如DROP、ALTER、INSERT等
- 定义数据表中每一个列的名称和数据类型,如果创建多个列,要用逗号(,)隔开
例如:创建员工表tb_emp1
#创建表tb_emp1
CREATE TABLE tb_emp1
(
id INT(11),
NAME VARCHAR(25),
deptID INT(11),
salary float
);
#查看表结构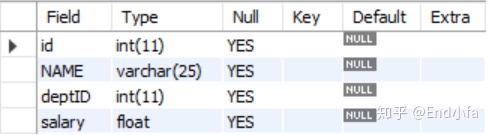
2.2约束
2.2.1主键约束(PRIMARY KEY)
- 主键又称主码,是表中一列或多列的组合,唯一标识表中的一条记录,如学生编号可以标识每一位学生身份
- 主键列的数据要唯一,不重复,不允许为空
- 可以结合外键来定义不同数据表之间的关系,并且加快数据库查询速度
(1)单字段主键
单字段主键由一个字段组成,SQL语句格式可分为以下两种情况:
方法1--在定义列的同时指定主键
字段名 数据类型 PRIMARY KEY [默认值]例:定义表tb_emp2,主键为id。
CREATE TABLE tb_emp2
(
id INT(11) PRIMARY KEY,
name VARCHAR(25),
deptID INT(11),
salary FLOAT
);方法2--在定义完所有列之后指定主键
[CONSTRAINT <约束名>] PRIMARY KEY [字段名]例:创建表tb_emp3,主键为id。
CREATE TABLE tb_emp3
(
id INT(11),
name VARCHAR(25),
deptID INT(11),
salary FLOAT
PRIMARY KEY(id)
);(2)多字段联合主键
PRIMARY KEY [字段1,字段2,...,字段n]例:创建表tb_emp4,假设表中没有主键id,为了唯一确定一个员工,可以把name、deptID联合起来作为主键。
CREATE TABLE tb_emp4
(
name VARCHAR(25),
deptID INT(11),
salary FLOAT,
PRIMARY KEY(name, deptID)
);2.2.2外键约束(FOREIGN KEY)
- 外键用来在两个表的数据之间建立链接,可以是一列或多列,一个表可以有一个或多个外键
- 一个表的外键往往是另一个表的主键
- 外键的作用是保证数据的完整性、一致性,在删除表的时候,注意先删除表之间的链接关系
- 对于两个具有关联关系的表而言,相关字段中主键所在的那个表即是主表(父表),外键所在的那个表为从表(字表)
语法:
[CONSTRAINT <外键名> FOREIGN KEY 字段名1 [, 字段名2,...] REFERENCES <主表名> 主键列1 [, 主键列2...]例:创建表tb_emp5,并在tb_emp5表上创建外键约束。
#2.2.3非空约束(NOT NULL)
非空约束指字段的值不能为空,若使用了非空约束的字段,在添加数据的时候没有指定值,数据库系统会报错。
字段名 数据类型 NOT NULL例:定义数据表tb_emp6,指定员工的名称不能为空。
CREATE TABLE tb_emp6
(
id INT(11) PRIMARY KEY,
name VARCHAR(25) NOT NULL,
deptID INT(11),
salary FLOAT
);2.2.4唯一性约束(UNIQUE)
唯一性约束要求该列取值唯一,允许为空,但只能出现一个空值。
字段名 数据类型 UNIQUE例:建立表tb_dept2,指定部门的名称唯一。
CREATE TABLE tb_dept2
(
id INT PRIMARY KEY,
name VARCHAR(22) UNIQUE,
location VARCHAR(50)
);另一种方式:
[CONSTRAINT <约束名> UNIQUE(<字段名>)同上例:
CREATE TABLE tb_dept2
(
id INT PRIMARY KEY,
name VARCHAR(22),
location VARCHAR(50)
CONSTRAINT STH UNIQUE(name)
);2.2.5默认约束(DEFAULT)
默认约束指定某列的默认值
字段名 数据类型 DEFAULT 默认值例:建立表tb_emp7,指定员工的部门编号默认为1111。
CREATE TABLE tb_emp7
(
id INT(11) PRIMARY KEY,
name VARCHAR(25) NOT NULL,
deptID INT(11) DEFAULT 1111,
salary FLOAT
);2.2.6表的属性值自动增加(AUTO_INCREMENT)
- AUTO_INCREMENT的初始值为1,每新增一条记录,字段值自动加1
- 一个表只能有一个字段使用AUTO_INCREMENT约束,且该字段必须作为主键的一部分
字段名 数据类型 AUTO_INCREMENT例:建立表tb_emp8,指定员工编号自动递增。
CREATE TABLE tb_emp8
(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(25) NOT NULL,
deptID INT(11),
salary FLOAT
);3.用SQL语句向表中添加数据
3.1语句解释
使用基本的INSERT语句插入数据,要求指定表名称和插入到新记录中的值。基本语法:
INSERT INTO table_name (column_list) VALUES (value_list);table_name指定要插入数据的表名,column_list指定要插入数据的那些列,value_list指定每个列对应插入的数据。注意:使用该语句时字段和数据值的数量必须相同。
3.2多种添加方式
例1--指定列名插入:
#先创建person表
CREATE TABLE person
(
id INT PRIMARY KEY AUTO_INCREMENT,
name CHAR(40) NOT NULL DEFAULT ' ',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL,
);
#插入数据
INSERT INTO person(id, name, age, info)
VALUES(1, 'Green', 21, 'Lawyer');
#查看结果
SELECT * FROM person;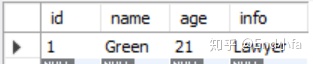
指定列名插入时,插入值的顺序可以与原表中列的顺序不同,但一定要与指定的列名顺序相同,不一定要使用全部列名,只要不违背约束条件就行(如非空约束)。
例2--不指定列名插入
#使用同上表person
INSERT INTO person
VALUES(2, 'Mary', 24, 'Musician');在没有指定列名的情况下,插入值的顺序必须与表中列的顺序相同。
例3--插入多条数据
#创建person_old表
CREATE TABLE person_old
(
id INT PRIMARY KEY AUTO_INCREMENT,
name CHAR(40) NOT NULL DEFAULT ' ',
age INT NOT NULL DEFAULT 0,
info CHAR(50) NULL
);
#插入数据
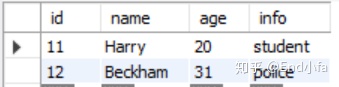
INSERT INTO person_old
VALUES (11, 'Harry', 20, 'student'), (12, 'Beckham', 31, 'police');
#查看数据
SELECT * FROM person_old;
4.用SQL语句删除表
删除表的时候要慎重,最好先做备份,以防表误删造成无法挽回的严重后果。
4.1DROP语句
4.1.1删除没有关联的表(可以同时删除多个表)
DROP TABLE [IF EXISTS] 表1, 表2, ..., 表n;如果删除的表不存在,MySQL会提示一条错误信息,使用IF EXISTS参数后,表不存也不会报错,但会发出警告。
例:删除数据表tb_dept2。
DROP TABLE IF EXISTS tb_dept2;4.1.2删除被其他表关联的主表
数据表之间存在外键关联的情况下,如果直接删除父表,结果会显示失败。如果必须要删除,可以先删除与它关联的字表,再删父表。当然,如果需要保留子表,只需将关联的表外键约束取消,然后就可以删除父表了。
4.2DELETE语句
从数据表中删除数据使用DELETE语句。DELETE语句允许WHERE子句(可选)指定删除条件。
DELETE FROM table_name [WHERE <condition>];例:
DELETE FROM person; #删除person表所有记录
DELETE FROM person
WHERE id=1; #删除person表中id为1的记录4.3TRUNCATE语句
如果想删除表中所有的记录,还可以使用TRUNCATE语句,它将直接删除原来的表,并重新创建一个表。
TRUNCATE TABLE table_name;
#例
TRUNCATE TABLE person;4.4多种删除方法区别
- DROP语句是直接删除整张表(不可以设置删除条件,必须删除整张表)
- DELETE语句是删除表中的记录,而不删除这张表,可以设置删除记录的条件
- TRUNCATE语句也是直接删除整张表,但不同于DROP是,它删除表后又创建一个新的和原来表结构一模一样的空表
- TRUNCATE与DROP语句的执行效率高于DELETE语句
5.用SQL修改表
5.1修改表名
ALTER TABLE <旧表名> RENAME <新表名>;
#例如:将表tb_emp1名字修改为ttbb_emp1
ALTER TABLE tb_emp1 RENAME ttbb_emp1; 5.2修改列的数据类型/列名
5.2.1修改数据类型
ALTER TABLE <表名> MODIFY <字段名> <数据类型>
#例如
ALTER TABLE tb_emp1 MODIFY name CHAR(100);5.2.2修改列名
ALTER TABLE <表名> CHANGE <旧列名> <新列名> <新数据类型>
#例如:将表tb_emp1中的name列改名为stu_name
ALTER TABLE tb_emp1 CHANGE name stu_name;5.3添加/删除列
5.3.1添加列
ALTER TABLE <表名> ADD <新列名> <数据类型>;
#例如:给表tb_emp1添加新列address,数据类型为VARCHAR(50)
ALTER TABLE tb_emp1 ADD address VARCHAR(50);
#添加列的时候设置约束条件
ALTER TABLE tb_emp1 ADD address VARCHAR(50) NOT NULL;
#在表的第一列添加一个列(FIRST关键字)
ALTER TABLE tb_emp1 ADD address VARCHAR(50) FIRST;
#在表的指定列之后添加一个列(AFTER关键字)
ALTER TABLE tb_emp1 ADD address VARCHAR(50) AFTER name;5.3.2删除列
ALTER TABLE <表名> DROP <列名>;
#例如
ALTER TABLE tb_emp1 DROP name;5.4添加/删除行
5.4.1添加行
INSERT INTO table_name (column_list) VALUES (value_list);
#另一种插入方式:将查询结果插入到表中
INSERT INTO table_name1 (column_list1)
SELECT (column_list2) FROM table_name2 WHERE (condition);
#例如:
INSERT INTO person(id, name, age, info)
SELECT id, name, age, info FROM person_old;5.4.2删除行
DELETE FROM <表名> [WHERE <condition>];5.5修改表中数据(UPDATE语句)
UPDATE table_name
SET column_name1 = value1, column_name2 = value2 ..., column_n = valuen
WHERE (condition);
#例如:在person表中,更新id值为11的记录,将age的值改为15,name值改为LiMing
UPDATE person SET age = 15, name = 'LiMing' WHERE id = 11;6.项目实战
项目三:超过5名学生的课(难度:简单)
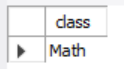
创建如下所示的courses 表 ,有: student (学生) 和 class (课程)。
例如,表:
+---------+------------+
| student | class |
+---------+------------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
| A | Math |
+---------+------------+
编写一个 SQL 查询,列出所有超过或等于5名学生的课。
应该输出:
+---------+
| class |
+---------+
| Math |
+---------+
Note:
学生在每个课中不应被重复计算。
参考:
#
项目四:交换工资(难度:简单)
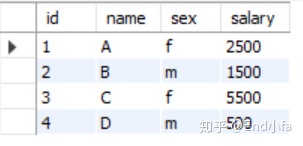
创建一个 salary表,如下所示,有m=男性 和 f=女性的值 。
例如:
| id | name | sex | salary |
|----|------|-----|--------|
| 1 | A | m | 2500 |
| 2 | B | f | 1500 |
| 3 | C | m | 5500 |
| 4 | D | f | 500 |
交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求使用一个更新查询,并且没有中间临时表。
运行你所编写的查询语句之后,将会得到以下表:
| id | name | sex | salary |
|----|------|-----|--------|
| 1 | A | f | 2500 |
| 2 | B | m | 1500 |
| 3 | C | f | 5500 |
| 4 | D | m | 500 |
参考:
#
二、MySQL基础---表联结
1.MySQL别名
1.1表的别名
当表的名字很长或者执行一些特殊查询时,为了方便操作或需要多次使用相同的表时,可以为表指定一个别名,用这个别名替代原来的名称。
表名 [AS] 表别名AS关键字是可选的,加不加都可以
例:
SELECT 1.2列的别名
列的名称很长或者列的名称不够直观的时候,可以给列取个别名,当然,计算的表达式也可以取别名;
列名 [AS] 列别名例:
SELECT 2.连接查询---内连接/外连接/交叉连接/自连接
通过连接操作可以查询从出放在不同表中的数据。当两个或多个表中存在相同意义的列时,便可以通过这些列对不同的表进行连接查询。
2.1内连接查询
2.1.1INNER JOIN内连接,获取两个表中列匹配关系的记录
SELECT column_list FROM table_name1
INNER JOIN table_name2
ON [condition];在这里的查询语句中,两个表之间的关系通过INNER JOIN指定(MySQL默认关系为INNER JOIN,此处的INNER可以省略),连接条件用ON子句给出(连接条件对要连接的数据进行过滤,发生于表连接之前)。内连接形式大概如下:

例子:
#生成两个示例表
CREATE TABLE age
(
id CHAR(5) PRIMARY KEY,
age int
);
CREATE TABLE stu_score
(
id CHAR(5) PRIMARY KEY,
score int
);
#给两个表插入数据
INSERT INTO age
VALUES('1', 12), ('3', 13), ('5', 14), ('6', 15), ('8', 16);
INSERT INTO stu_score
VALUES('1', 78), ('3', 85), ('4', 67), ('7', 92), ('8', 88);
#内连接
SELECT * FROM age a
INNER JOIN stu_score s #指定连接方式
ON a.id = s.id; #指定连接条件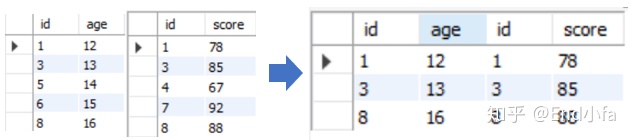
2.1.2结合WHERE而不使用JOIN的内连接
实际上,不使用INNER JOIN也可以实现表之间的内连接。但是,这种连接方式在效率上不及INNER JOIN,原因是这种方式会先产生一张笛卡尔积表,然后再根据WHERE的条件过滤数据,即数据的过滤在表连接之后进行的,而ON对数据的过滤发生在表连接前。
例:
#使用前面创建的表
SELECT * FROM age a, stu_score s
WHERE a.id = s.id;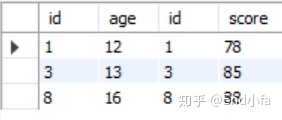
2.2外链接---LEFT JOIN/RIGHT JOIN
2.2.1左连接
LEFT JOIN是获取左表所有记录,即使右表没有对应匹配的记录。表连接的形式大概是:

例子:
#同上表
SELECT * FROM age a
LEFT JOIN stu_score s
ON a.id = s.id;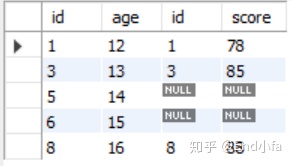
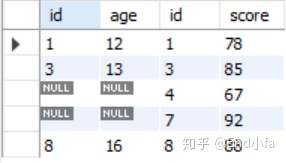
2.2.2右连接
RIGHT JOIN是获取右表所有记录,即使左表没有对应匹配的记录。右连接的形式大概是:

例子:
#
2.3交叉连接
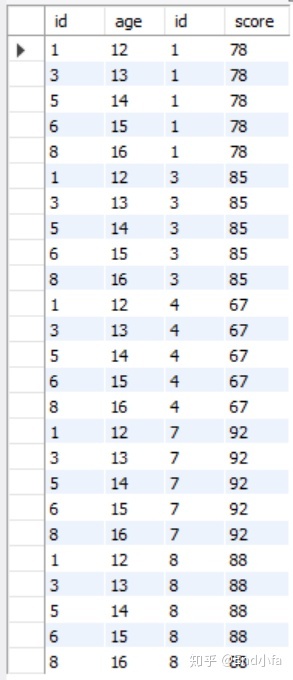
CROSS JOIN子句从连接的表返回行的笛卡尔积,即用CROSS JOIN连接两个表,结果集是两表生成的笛卡尔积表,包含两个表所有的行以及所组合。形式大概如下:
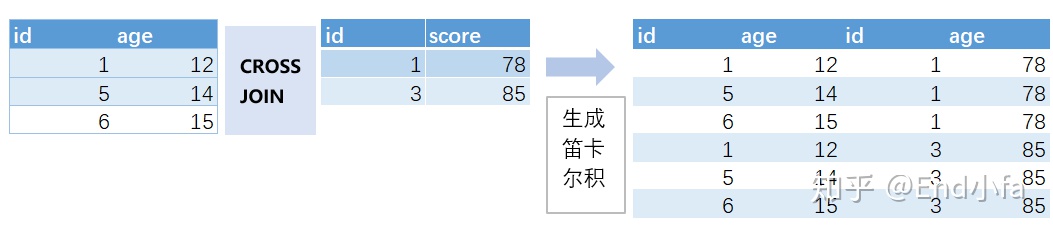
例子:
#
2.4自连接
自连接就是对相同一个表的多次连接。
例:
SELECT 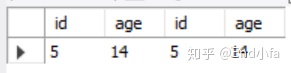
3.UNION
- 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果输出
- 合并时,两个表对应的列数和数据类型必须相同
- 各个SELECT语句需用UNION或UNION ALL关键字分隔
- UNION不使用关键字ALL,执行的时候删除重复的记录,返回的记录都是唯一的
- 使用ALL关键字,则不剔除重复的记录
SELECT 例子:
#
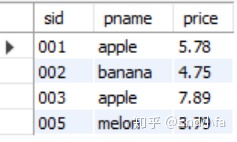
4.各种连接查询的区别
- JOIN连接是横向连接表数据,UNION是纵向连接表数据
- JOIN连接和FROM table1, table2这种连接方式在没有指定连接条件时都会生成笛卡尔积表,但在指定连接条件后,JOIN使用的ON子句对数据的过滤是发生在表的连接前,因此不会直接产生笛卡尔积表,而是产生符合条件的表。而第二种方式需要WHERE子句来指定连接条件,WHERE子句对数据的过滤发生在表连接后,故需先产生一张笛卡尔积表,再做数据的过滤。因此,从效率上来看,JOIN连接方式优于后者。
5.SQL语句执行顺序
- From
- ON
- JOIN
- WHERE
- GROUP BY
- SELECT
- HAVING
- ORDER BY
- LIMIT
6.项目练习
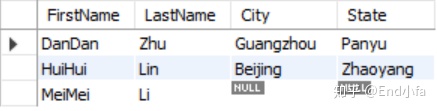
项目五:组合两张表 (难度:简单)
在数据库中创建表1和表2,并各插入三行数据(自己造)
表1: Person
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
+-------------+---------+
PersonId 是上表主键
表2: Address
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
+-------------+---------+
AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:FirstName, LastName, City, State
参考:
#
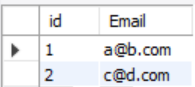
项目六:删除重复的邮箱(难度:简单)
编写一个 SQL 查询,来删除 email 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
+----+---------+
| Id | Email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
Id 是这个表的主键。
例如,在运行你的查询语句之后,上面的 Person表应返回以下几行:
+----+------------------+
| Id | Email |
+----+------------------+
| 1 | a@b.com |
| 2 | c@d.com |
+----+------------------+
参考:
#
本期到此结束,欢迎后续继续学习下一期的内容~
上一期内容:
End小fa:MySQL入门---2.zhuanlan.zhihu.com
参考
mysql(2)-- 由笛卡尔积现象分析数据库表的连接
Mysql 连接的使用 | 菜鸟教程
《MySQL5.7从入门到精通》 ---刘增杰














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









