






我们使用Elasticsearch进行搜索的时候,可以使用单个词语来搜索,也可以使用多个词语来搜索,从而搜索出我们需要的文档。
在出题前,先简单的了解一些知识。
举例如下:
首先,我们使用 bulk API 创建一些新的文档和索引(bulk执行多条数据插入,批量操作):
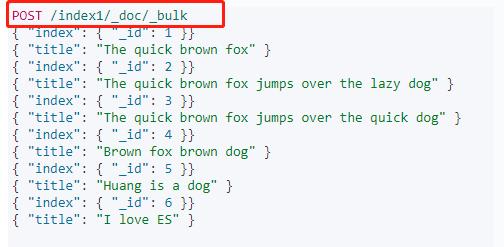
输出内容如下:
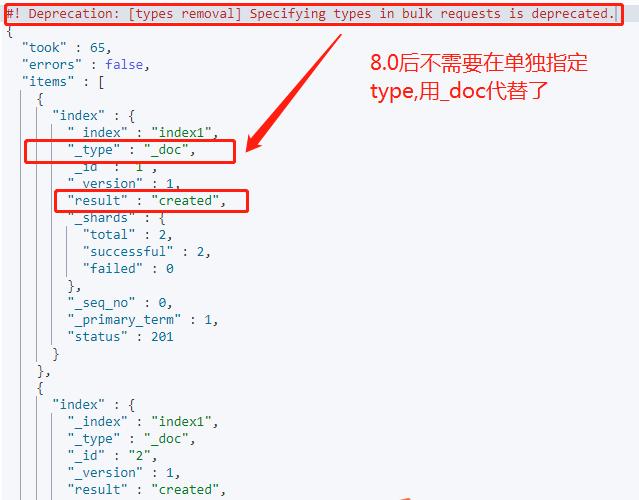
从图中可以看出,已经成功创建了文档,下面我想做单个词查询:查询 title中包含QUICK的文档。查询语句如下:使用 match 查询搜索全文字段中的单个词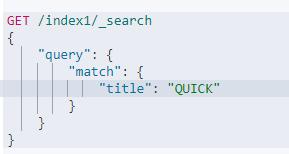
前面插入了6条数据,执行这条查询后,你认为会返回几条数据呢?先思考一下: 0条? 3条? 还是全部?
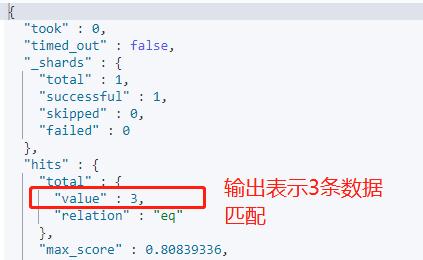
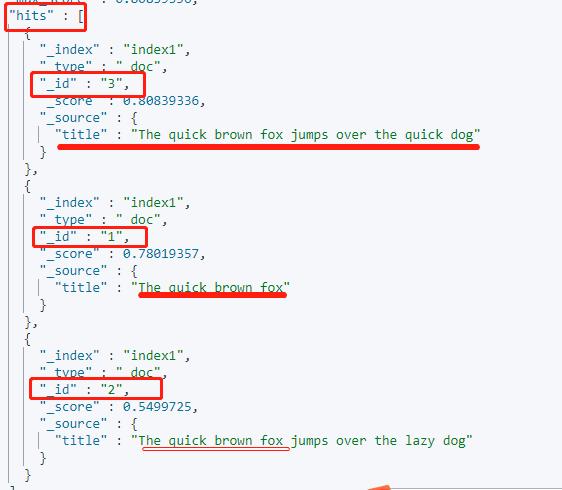
下面输出的为匹配到的内容:id=1 ,2 ,3 的三条数据匹配
匹配查询 match 是个 核心 查询。无论需要查询什么字段, match 查询都应该会是首选的查询方式。 它是一个高级 全文查询 ,这表示它既能处理全文字段,又能处理精确字段。
这就是说, match 查询主要的应用场景就是进行全文搜索。
看到结果,也许你会疑惑,我查找的是QUICK(大写),不是quick, 怎么输出都变成了小写呢?如果你看过之前的分析器的文章,你就会明白了,Elasticsearch默认会使用标准分析器,它会将输入的单词全部变成小写,这就是标准分析器(standard)的特点. 因此,这里输出的是小写的quick而不是大写的QUICK。
Elasticsearch 执行上面这个 match 查询的步骤是:
1. 检查字段类型
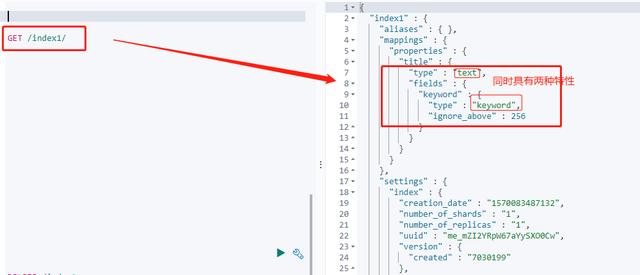
标题 title 字段是一个 字符串类型(text 可用于分词),是一个可分析的全文字段,这意味着查询字符串本身也应该被分析(查看所属类型)
# 注意text与keyword的区别,前文分析器也有说明的
2. 分析查询字符串
将查询的字符串 QUICK 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term(词条) 查询。
3. 查找匹配文档
用 term(词条) 查询在倒排索引中查找 quick 然后获取一组包含该项的文档,本例的结果是文档:1、2 和 3
4. 为每个文档评分
用 term(词条) 查询计算每个文档相关度评分 _score ,这是种将 词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式
看看各条数据的评分:
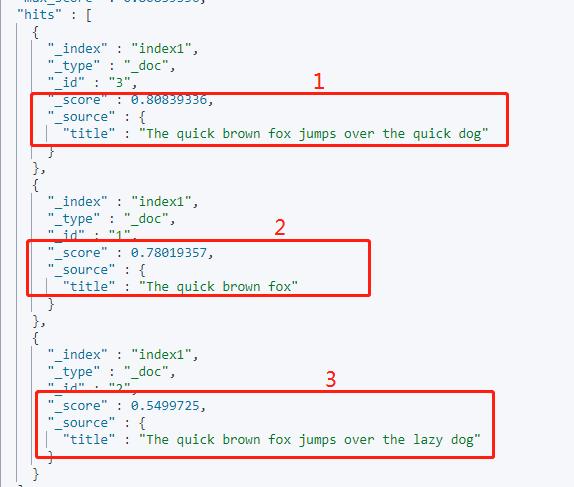
文档1的分数最高,也就是表示相关度最高,因为它在title中出现了两次。
文档2比文档3分数高,表示相关度更高,因为文档2的 title 字段更短,即 quick 占据内容的一大部分
了解了上面的知识后,我们再来看看 多词查询
如果我们一次只能搜索一个词,那么全文搜索就会不太灵活,幸运的是 match 查询让多词查询变得简单。
还是以上面post的6条数据举例:
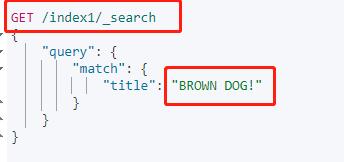
执行下面的查询语句,查询title中包含"BROWN DOG!"的文档:
那么问题来了,请回答下面几个问题(原理跟单词查询类似):
1)输出结果中是否有数据返回?
2)如果有输出,分别是那几条?
3)如果有输出,结果中按分数高低排名,怎么排?
请思考后认真回答,输出内容以及答案在后面,然后对照自己的对比下,看是否答对。

id: 2, 3 分数相同

id: 1, 5分数相同

答案: 共有5条数据输出,分数排名为:4> 2=3 > 1=5
剖析:
- 文档 4 最相关,因为它包含词 "brown" 两次以及 "dog" 一次
- 文档 2、3 同时包含 brown 和 dog 各一次,而且它们 title 字段的长度相同,所以具有相同的评分。
- 文档 1和5 也能匹配,因为各自匹配brown 、dog
- 文档6没有任何匹配,所以输出不包含文档6
上例查找中, match 查询必须查找两个词( ["brown
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









