





之前决定深入学习一次
data.table的时候做过一些它的笔记:
1. dtplyr/dplyr 的基本操作与对应的 data.table 操作
2. dtplyr/dplyr 的基本操作与对应的 data.table 操作(二)
当然,我当时并无明确缘由要学习它,只是忽然发现之前觉得麻烦(几年前我就知道它),可能就是自己无知,学的太少。现在就是纯感觉,更喜欢
data.table的语法,按照一定的原则自由组合 i , j 和 by 的位置即可。当然不能否认tidyverse更对新手友好,框架化,更接近自然语言,但是没办法,有时候不来电就是难以记忆。或许是统计之都的 一篇文章1所列举的原因,但我并不清楚,因为有一些观点我是看到了才觉得是这么回事,以前网上的说法总是一些关于容易陷入依赖的地狱,以及更新后代码不能用的问题。以上又犯了老毛病,啰里啰嗦跑题了,这并非本文重点。
最近 data.table 又更新了它的 vignettes2,专门 copy 和 setkey,看了之后解决了很多疑惑,最近几天有点失眠(可能是夜里真不适合看这个),索性在此此我对这些理解做一个整理,以方便后面查看。
1. Copy
1.1 shallow copy VS. deep copy
关于这个概念,之前没有在 R 内看到明确的出处,印象里应该在第一版的 advanced R 里有提到,但我也懒得查了,最初对这个概念的印象反而是来自于 python 官方文档的内容有明确的概念3,并且在学习 python 的 list 概念的时候,已经有这个概念了。
关于这个概念,wikipedia 是有明确解释的:
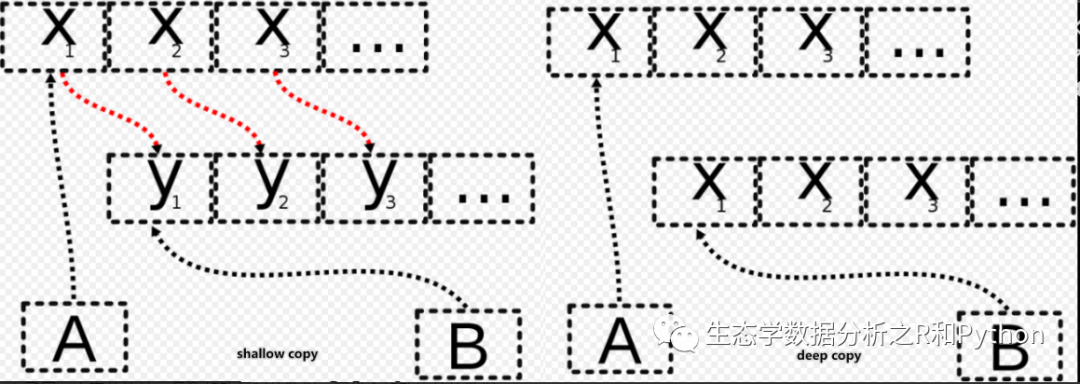
所谓的 shallow copy,以 dataframe 为例,就是不对数据进行我们常规意义上的复制,其实复制的内容只是数据在内存的地址,也就是和原数据指向了同一内存的地址,导致修改复制的数据,同样会修改原始的数据。
而对于 deep copy 则就是我们通常意义上的操作,又复制了一份数据,在不同的内存的位置上,修改不同位置上的数据,互不干扰。那么这就是为什么使用 data.table 的时候,有时候修改的是原来的 datatable,有时候又不影响最初的数据。那么由此而来的另一个问题就是,什么时候影响,什么时候不影响,或者说怎么是确切的 shallow copy,怎么是确切的 deep copy。
1.2 shallow copy
1.2.1 `:=` 进行 shallow copy
:= 在帮助文档的标题就是 “Assignment by reference”,明确无误的告诉我们,他的功能就是改变原有数据文件,因为改变的是 reference。这里看一个例子:
flights "data/flights14.csv")
# deep copy, a new data table created
# -------------------------------------
flights[hour == 24L][, hour := 0L]
# still the same with csv
flights[hour == 24L][, hour]
# shallow copy, copy by reference
# -----------------------------------------
flights[hour == 24L, hour := 0L]
# no 24 hour data
flights[hour == 24L][, hour]
# only 0 data
flights[hour == 0L][, hour]
1
2

3
这里很清楚的可以看到,第一次修改 24 的数据,并没有影响到读入的 flights 的数据,而第二次修改 24 h 的数据,则清晰的影响到原来的数据集。换句话说,如果我们想用第一种方式修改数据集,并将其作为后续处理数据,那么我们需要将其赋值,例如:
flights0 <- flights[hour == 24L][, hour := 0L]因此在使用 datatable 的时候,如果没有显示数据,大可不必担忧,如果没有使用 chain operators (多于一个 [] 的操作)进行修改,那么只要 [] 内使用了 :=,那么修改就发生在了源数据。
1.3 set* 函数进行 shallow copy
除了 := 外,其实最明确的方式是一些列以 set 开始的函数,也就是说,只要在 data.table 内以 set 开头的函数,全部作用于原数据:
setkey:这个后面内容会详细解释,就是给我们的 datatable 创建一个 key。setDT:强制转换data.frame或 list 为data.table。setDF:与setDT相反,强制将data.table转换为data.framesetorder:根据提供的列名对行进行排序。setattr和setnames:设置对象的属性/名字。
当然,除此以外实际上应该还加上一个 data.table,当然这是每个使用 data.table 这个 package 的人都十分确定的一项了。
1.4 Deep copy
1.4.1 =
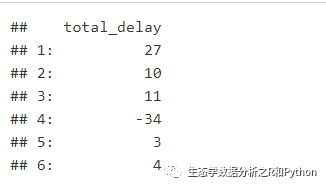
通过上面的例子,可以在需要的时候,使用 := 对数据进行添加列等的相关操作,这种操作不会改变原来已有的数据,虽然在原来的数据上进行了添加。这是非常方便的,例如 LI-6800 的数据,我们可以据此添加一列 WUE,水分利用效率,不改变原来其他的数据,不用再拷贝一份数据到内存。但有时候我们并不希望在原数据集上进行修改,例如我们需要其中某几列数据,进行简单运算对数据进行查看,我们可以使用 =,单独提取几列的数据(实际就是 deep copy 了这几列)进行运算等操作:
ans <- flights[, .(total_delay = arr_delay + dep_delay)]
head(ans)
当需要对数大量修改但又必须保留原来数据的时候,这样进行逐列的提取显然并不划算,那么 copy 则需要登场了。
1.4.2 copy
这个其实是最容易理解的函数,就是字面意思,跟我们要处理 LI-6800 数据之前,通常复制一份,然后再处理数据是一个道理。data.table 的 vignettes 里介绍了他一个简单的用法:
foo function(DT) {
## deep copy
DT ## doesn't affect 'flights'
DT[, speed := distance / (air_time/60)]
DT[, .(max_speed = max(speed)), by = month]
}
ans head(flights)
另一个容易被忽略的应用是 names(DT),在普通的 data.frame 内,我们将其赋值给某变量后,做修改的时候二者实际上是互不干扰的,但在 data.table 内,这属于 shallow copy,和 python list 是一种情况,若 data.table 的名称,则会影响这个变量。因此,若想单独使用,应该 copy(names(DT))。
2 Auto index
2.1 setkey
我们如果想按一定顺序排列 data.table,可以使用 DT[order(column)] 或者 DT[order(-column)] 的形式,但可以直接将该列设置为 key,这样 data.table 会自动按升序排列。这个key,作者将其称为 "supercharged rownames"。他和 data.frame 的行名相似,但有额外的功能:
首先
data.table有 rowname 的概念,但仅仅是因为继承了data.frame的属性,在data.table里没任何用处。所以为有相近功能的一些操作,他有新的概念叫做 key。key 可以设置多列,不同的数据类型均可。
key 不同于 rowname,他是可以重复的。
key 设定后,通过给定的列来重新排列行的顺序,并且顺序是升序;这时
data.table就多了一个 sorted 属性。因为data.table设定key 后只能按一种方式排列,所以 key 只能有一个,同时设定多列也只有一个,不能设置不同的key,这个几轮同之前的可以设置多列并不矛盾,同时设置的多列,算一个 key,key 不按列算,按设定的命令算,例如:
setkey(flights, dest)
setkey(flights, origin)
key(flights)
setkey(flights, origin, dest)
key(flights)
1

2

设定 key 的好处是操作方便了:
# NOT KEY
head(flights[carrier == 'AA'])
# origin = ewr,dest = alb
head(flights[c("EWR", "ALB")])
1
2
除了方便外,当数量大时,使用 key 还有速度快的优点,因为 key 已经被设置好了,顺序也都排好了,所以直接就找到了所需要的数据,这种方式称为 Binary search,而第一种方式,在提取相关内容时,还需要按列来寻找要求匹配的内容,多个列就需要匹配多次,这当然会慢,这种方式被称为 Vector search。既然使用 key 只能升序,那么想得到倒序结果怎么做?
head(flights["EWR"][order(-arr_delay)])
2.2 Secondary indices
secondary indices 是比较新的功能,所起到的效果类似于 key,其主要差异为:
它不在物理上(RAM)对
data.table进行重新排序,只是对所提供的数据列进行排序计算,这个计算的有序向量是另存在额外的属性 index 内。可以设置多个 secondary indices,这是和 key 最显著的区别,也是视觉上最直观的差异(此处的carrier是前文内容设置)。
setindex(flights, origin)
indices(flights)
setindex(flights, origin, dep_delay)
indices(flights)
1

2

最重要的是,它并没有改变 flights 的排序情况。之所以增加一个看似重复的功能,主要是 key 有如下缺点:
他会根据提供的 key 进行重新的计算排序,
这个排序是一个修改物理位置的排序
以上行为当然并不耗费大量时间,但是当数据量大(行多列多)时,对整个 data.table 排序则会相当费时。如果我们的工作就是针对某列进行反复排序,例如,我们所有的数据列都是围绕某一实验处理反复进行的,那么这就不是问题,反而很节省时间。
key 只能有一个,在某些时候我们需要另设置 key,但那样又重复了上面的耗时过程。尤其是当这两列有相同的内容时。
index 相比于我们之前在 i 位置进行的条件判定,他有可以重复使用的优点。除了使用 setindex 外,还可以方便的使用 on 来进行一个设置,也就是 [i,j,on],这个也是优点非常明显的一个用法:
可以不用使用
setindex()就可以轻松的利用 secondary indies 进行子集的计算。方便设置,当然更方便重复使用(遗憾的是目前还没实现)。
语法上更清晰。
如果之前已经熟悉了 data.table,那就是无缝衔接,例如:
flights[.("LGA", "TPA"), .(max(arr_delay), unique(carrier)),
keyby = month, on = c("origin", "dest")
]

可以看到 DL 和 B6 真不是美帝商务出行的好选择,当然,这种航空公司可能是便宜吧。
2.3 Auto index
前面介绍的 indices 和 key 在 data.table 内都属于 autoindex 的范畴,目前仅支持 == 和 %in%,这句话的意思是讲,当我们在用这两个符号进行条件的筛选时,他会创建一个额外的属性,不同于 on 在使用时才有效(除非提前 setindex),这两个符号可以立刻支持在 data.table 内创建 secdondary index 属性。如果我们第一次使用这两个符号,那么它首先创建这些属性,当第二次用这个符号后,运行时间将大大缩短(相同的列)。仍然的遗憾就是其他常用的逻辑判断 , >= 尚未支持,还是其他新版本吧。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









