





今天在用tensorflow处理线性回归的时候,提到两个数据集,adult_set数据集,可以用来做逻辑回归.但是其中一些标记是列表标记,既然是做分析,就得将起转化为数值编码.比如男(male),女(female),就得转化为1和2,或者one_hot编码.不少包都有对应的方式.总结一下.
sklearn.DictVectorizer
sklearn.feature_extraction中的DictVectorizer,将类别标签转化为one_hot编码
#coding:utf-8
#author:selous
measurements = [
{'city': 'Dubai', 'temperature': 33.,'gender':'女'},
{'city': 'London', 'temperature': 12.,'gender':'男'},
{'city': 'San Fransisco', 'temperature': 18.,'gender':'男'},
{'city': 'San Fransisco', 'temperature': 18.,'gender':'男'},
]
#list
measurements1 = [
{'city': 'London', 'temperature': 10.,'gender':'女'},
{'city': 'Dubai', 'temperature': 1.,'gender':'女'},
{'city': 'San Fransisco', 'temperature': 1.,'gender':'男'},
{'city': 'San Fransisco', 'temperature': 1.,'gender':'男'},
]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
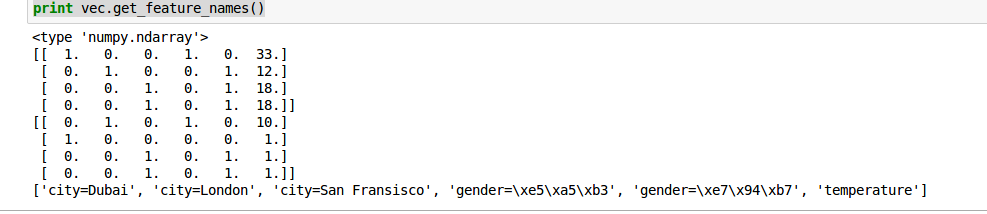
trans_vec = vec.fit_transform(measurements).toarray();
print trans_vec
print vec.transform(measurements1).toarray();
print vec.get_feature_names()
结果(汉字没有处理):
具体的DictVectorizer例子可以参考链接
sklearn.OneHotEncoder
sklearn.preprocessing包下的OneHotEncoder.这个方法只能转化原来的值就是整数的.(也就是数据中的种类已经用整数表示了.),将其转化为one_hot编码
错误实例:
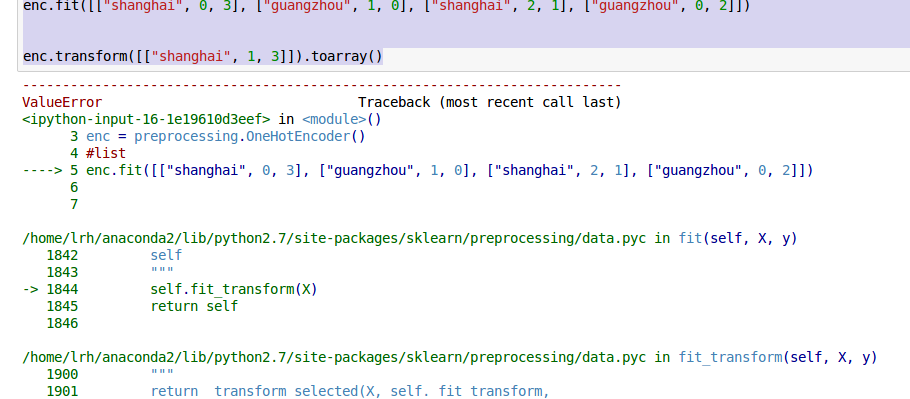
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
#list
enc.fit([["shanghai", 0, 3], ["guangzhou", 1, 0], ["shanghai", 2, 1], ["guangzhou", 0, 2]])
enc.transform([["shanghai", 1, 3]]).toarray()
上面这个是错的,因为转化的元素必须是整数Interger.而shanghai是str类型
正确写法:
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray()
如果:

字段意义的解释:
By default, how many values each feature can take is inferred automatically from the dataset. It is possible to specify this explicitly using the parameter n_values. There are two genders, three possible continents and four web browsers in our dataset. Then we fit the estimator, and transform a data point. In the result, the first two numbers encode the gender, the next set of three numbers the continent and the last four the web browser.
panda.get_dummies()*
最方便的还是panda提供的方法.
下面博客中提到的这两种编码:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
两种编码我们可能都要用到.所以最好的方法还是panda提供的方法.
贴一篇别人写的博客.,写的很详细.
tensorflow中的方法
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









